
Abstract
- Quantizing Models to run in 8 bit is a non-trivial task.
- Equalizing the weight ranges in the network by making use of a scale-equivariance property of activation functions.
- Scale Equivarience $f(sx) = sf(x)$ ReLU함수처럼 입력에 s배를 진행하면 Output 또한 s배가 된다. 이 성질을 사용하여 두 레이어 사이에 Diagonal 성분에 스케일링 성분을 집어넣고, 다음 레이어에서 역행렬 성분을 사용해도 전체 output에는 영향을 미치지 않는다. 위 성질을 사용하여 Quantization 시에 중요하게 사용되는 Weight 범위를 적절하게 조절해주고자 한다.
- Correcting biases in the error that are introduced during quantization
1. Introduction
최근에 DNN의 Power Consumption이 중요해지면서 fixed-point quantization이 주로 사용되었다. 하지만, Quantization을 진행함에 따라서 Accuracy가 감소하는 문제가 발생하였고, 이를 해결하기 위해 수많은 방법들이 고안되었다. 다만, 대부분의 방법론들은 모두 데이터를 사용하여 해결하는 쉽게 말해 데이터 의존적인 방법들이 많았다.
만약, FP32 정도의 굉장히 큰 모델을 별다른 데이터 없이 바로 INT8 정도의 경량 모델로 변환하는 방법이 존재한다면 Quantization 방법을 모르는 사람은 물론이고, 해당 방법에 특화된 사람들도 엄청난 시간 이득을 보게 될 것이다.
이번 논문에서 저자들은 Full-Precision 모델의 Weight값을 가져와서 Quantization을 진행하는 과정에서 발생하는 Quantization Error Bias를 최소화하는 방식으로 FP32정도의 모델을 INT8로 압축하는 과정을 소개한다고 한다. (사실 전체 모델의 가중치를 가져오는 방법은 교사학습의 한 종류로 많이들 사용하던 방식이다.)
Levels of quantization solutions
사실 여러 Quantization 방법론들이 제시되었지만, 해당 방법론들이 실제로 적용되는 대상에 대한 논의는 거의 없다. 이 논문의 저자들은 여러 방법론들의 실제 적용 가능성들을 비교하기 위해서 4가지의 단계를 제안한다. 이 과정을 통해서 방법론들 사이의 조금 더 공평한 비교가 가능하기 때문에 이렇게 구분한다고 한다.
단계를 구분하는 기준은 아래와 같다.
- Data를 요구하는 방법론인가?
- Quantized model의 Error Backpropagation을 필요로 하는가?
- 모델을 재구성하지 않아도 일반적으로 적용이 가능한가?
위 단계를 토대로 저자들은 네가지 단계로 방법론들을 구분한다.
- Level 1 : No Data / No BackProp / Any Model
- Level 2 : Data Required / No Backprop / Any Model 이 과정에서 사용되는 데이터는 Normalization 과정에서 사용되는 파라미터를 조정하기 위함이나 Layer wise Loss를 연산하기 위한 데이터이지 실제로 fine tuning을 진행하기 위한 데이터가 아니다.
- Level 3 : Data Required / Backprop Required / Any Model Quantization 방법론을 적용할 수 있지만, Fine-tuning을 거쳐야만 제대로 된 성능을 보인다. 따라서 Training 파이프라인 전체가 필요하다.
- Level 4 : Data Required / Backprop Required / Specific Model 해당 방법론을 적용할 수 있는 모델 자체가 한정적이고, 모든 훈련과정을 제대로 거쳐야 하므로 굉장히 많은 시간이 소요된다.
2. Background and Related Work
기존의 연구들은 Fine-Tuning 기법을 적용한 것이 대부분이기 때문에 Level3 방법론에 해당한다. Data가 필요없는 방법은 해당 방법론들과 비슷한 수준의 성능을 내기 때문에, 저자들의 제안하는 방법을 Pre-Processing 과정으로 생각할 수 있다.
기존의 방법론 중에서 Level 1으로 각 Channel 별로 양자화를 진행하는 방법론이 존재했지만, 각 Channel 별로 Scale $S$값과 Offset $Z$들을 필요로 하기 때문에 굉장히 비효율적이라고 한다. 논문에서 제안하는 방법은 Per channel Quantization을 전체 Weight Tensor에 대해서 Single Set Scale / Offset을 사용하면서 이를 해결한다고 한다.
Level 4 중 Binary나 Tenary로 가중치를 수정하는 경우에는 실제로 굉장히 XOR 연산이나 Bit Shift 연산으로 효율적으로 동작할 수 있지만, 심각한 수준의 정확도 저하가 문제가 된다.
3. Motivation
3.1 Weight Tensor Channel Ranges
많은 방법론들이 FP32에서 INT8로의 변환은 정확도를 굉장히 잘 유지하면서 Quantization을 진행한다. 다만, Quantization을 진행한 직후에는 굉장히 큰 폭으로 성능이 저하되지만, 추후의 Fine Tuning 과정을 통해서 정확도를 복원하는 과정을 거친다.
저자들은 Channel 별로 Weight의 분포가 굉장히 차이가 많이 나기 때문에 발생하는 문제라고 주장한다. 실제로 Channel 별로 Weight의 분포를 파악해본 Figure 2를 확인해보면, 편차가 굉장히 심한 것을 알 수 있다. 이렇게 된다면 전체를 다 커버하기 위한 Step size를 사용한다면 어떤 Channel의 Weight값은 전부 0으로 양자화되는 문제가 발생하게 될 것이다.
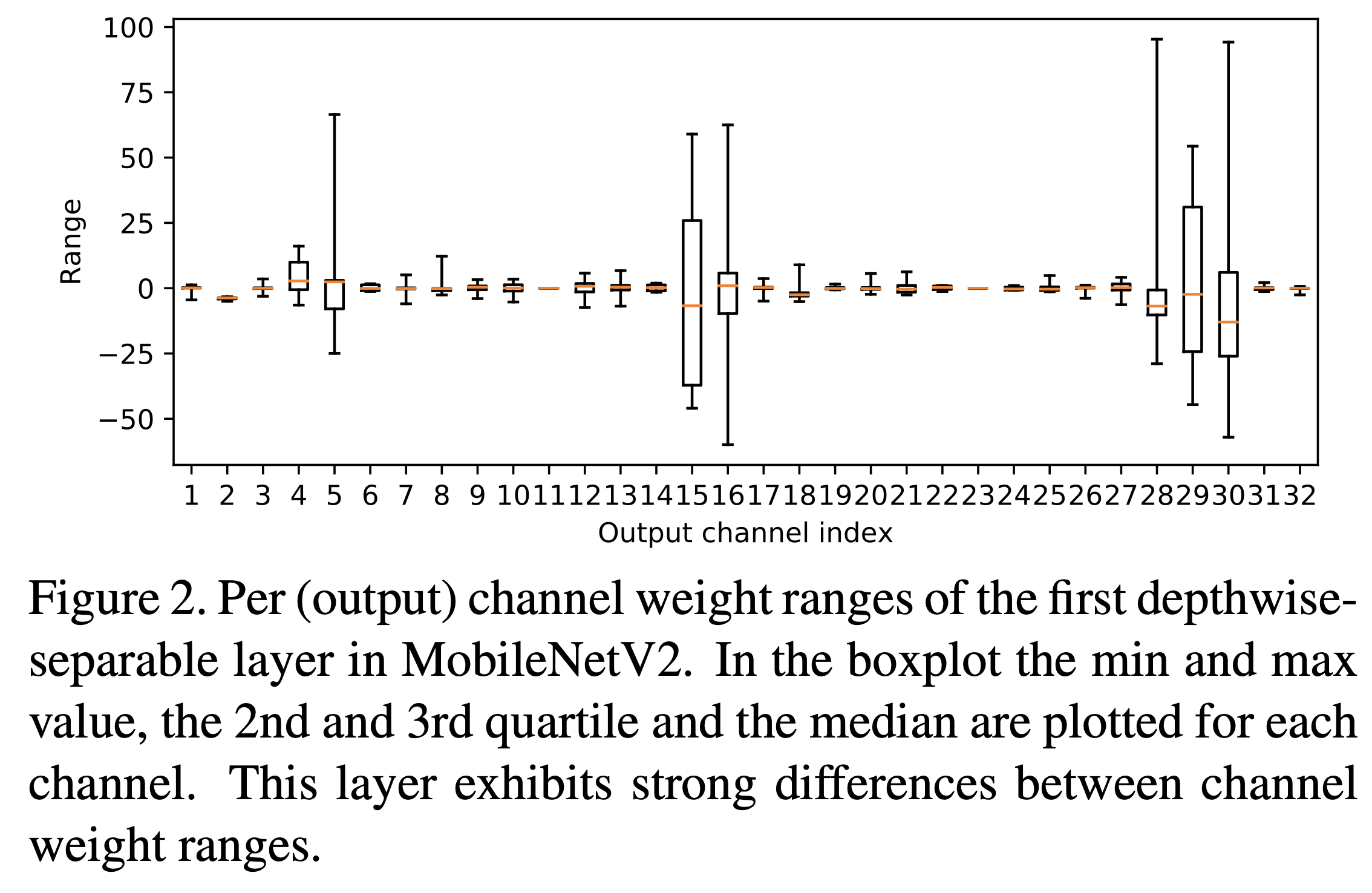
따라서 저자들은 비슷한 범위를 가진 Per-Channel로 양자화를 진행한다면 양자화 직후의 성능을 높일 수 있을 것으로 추측한다고 한다. Level 1 방법으로 FP32 모델의 출력을 변형하지 않고도 이를 달성할 수 있는 방법을 제공하는 것이다.
3.2 Biased Quantization Error
기존까지의 연구는 Quantization Error 즉, $\tilde W$와 $W$사이의 차이는 비편향 오차이기 때문에 이를 통해 비롯된 최종적인 Output의 차이는 상쇄된다는 것이 정론이었다. 다만, 실제로 그럴지에 대한 실험을 진행해보면 양상이 다르다는 것을 확인할 수 있다.
\[\mathbb{E}\!\left[\tilde{y}_j - y_j\right] \approx \frac{1}{N}\sum_{n}\left(\left(\tilde{\mathbf{W}}\mathbf{x}_n\right)_j - \left(\mathbf{W}\mathbf{x}_n\right)_j\right)\]위 식을 통해서 각 output의 경험적 기댓값을 구할 수 있을 것이다. 이제 효율적인 연산을 위하여 Depth-wise 연산을 진행하는 경우를 고려해보자. 먼저 일반적인 경우의 CNN이다.
\[\text{Input: } X \in \mathcal{R}^{C \times H \times W} \;\;\; \text{Weight : } W \in \mathcal{R}^{F \times C \times K \times K} \;\; \text{Output: }Y \in \mathcal{R}^{F \times H_{out} \times W_{out}}\]위와 같은 연산을 진행하는 데에, $F \times H_{out} \times W_{out} \times C \times K^2$에 해당하는 연산이 필요하다. 이 연산을 진행하지 말고, 먼저 $\mathcal{R}^{C \times 1 \times K \times K}$에 해당하는 가중치를 사용하여 Channel 별로 Conv2D 연산을 진행할 수 있다.
\[\text{Input: } X \in \mathcal{R}^{C \times H \times W} \;\;\; \text{Weight : } W \in \mathcal{R}^{C \times 1 \times K \times K} \;\; \text{Output: }Y \in \mathcal{R}^{C \times H_{out} \times W_{out}}\]이후에, $\mathcal{R}^{F \times C \times 1 \times 1}$ 에 대응하는 Weight값을 사용하여 한번 더 연산을 진행할 수 있다.
\[\text{Input: } X \in \mathcal{R}^{C \times H_{out} \times W_{out}} \;\;\; \text{Weight : } W \in \mathcal{R}^{F \times C \times 1 \times 1} \;\; \text{Output: }Y \in \mathcal{R}^{F \times H_{out} \times W_{out}}\]결론적으로 연산의 결과는 동일하다. 하지만, 두번째 방법의 연산 횟수는 $C \times H_{out} \times W_{out} \times K^2 + F \times H_{out} \times W_{out} \times C = (C \times H_{out} \times W_{out}) (K^2 + F)$에 해당한다. 따라서 더 효율적으로 연산이 가능하다.
1단계까지만 진행하는 것이 Depth-wise layer이고, 뒤이어 진행하는 연산이 Point-wise Layer이다. 논문에서는 1단계까지만 진행한 이후 각각의 Channel에 대한 경험적 오차를 실제로 구해보았다.
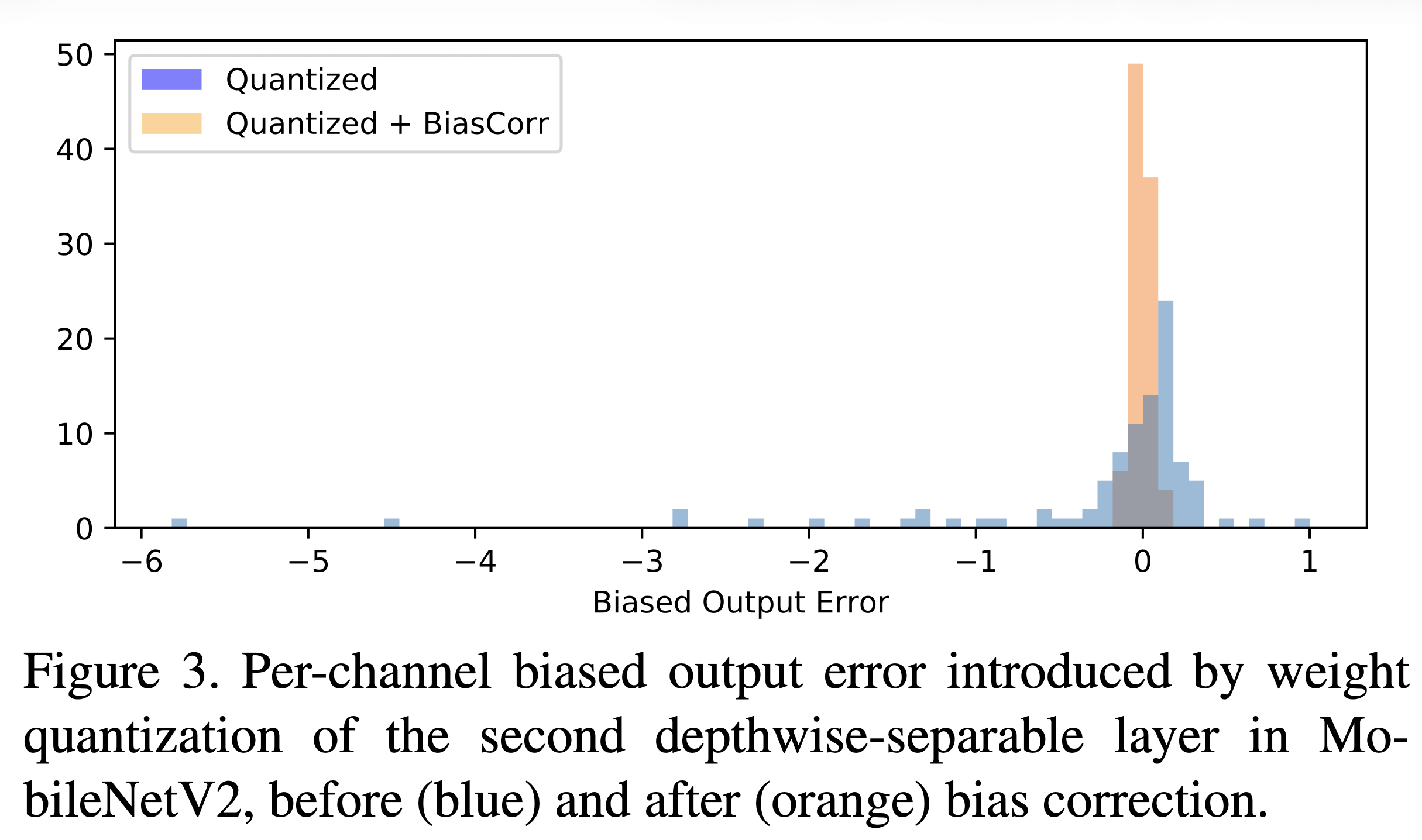
위 도표를 통해서 확인할 수 있듯이, 여러 가정과 달리 편향된 오차가 존재하기 때문에 이를 보정하는 과정도 필요하다고 주장한다.
4. Method
논문에서 제안하는 DFQ 방법론은 3가지 단계로 구성된다.
4.1 Cross Layer Range Equalization
Positive scaling equivariance : ReLU Activation Function에 대해 $f(sx) = sf(x)$가 성립한다. 더 일반적으로, Piece-wise Linear Activation function에 대하여 아래와 같은 수식이 성립한다.
\[f(x)= \begin{cases} a_{1}x+b_{1} & \text{if } x\le c_{1},\\ a_{2}x+b_{2} & \text{if } c_{1}<x\le c_{2},\\ \vdots & \vdots\\ a_{n}x+b_{n} & \text{if } c_{n-1}<x. \end{cases}\]위와 같은 Activation function에 대하여 $\hat{a}_i=a_i,\qquad \hat{b}_i=\frac{b_i}{s},\qquad \hat{c}_i=\frac{c_i}{s}.$ 와 같이 설정한다면, $f(sx) = s \hat f(x)$가 성립한다.
Weight의 선형성으로 인해서 아래와 같이 정리가 가능하다. 이때 $S = diag(s)$이다.
\[\begin{aligned} \mathbf{h} &= f\!\left(\mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)}\right), \\ \mathbf{y} &= f\!\left(\mathbf{W}^{(2)} \mathbf{h} + \mathbf{b}^{(2)}\right) \\[6pt] &= f\!\left(\mathbf{W}^{(2)} f\!\left(\mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)}\right) + \mathbf{b}^{(2)}\right) \\[6pt] &= f\!\left(\mathbf{W}^{(2)} \mathbf{S} f\!\left(\mathbf{S}^{-1} \mathbf{W}^{(1)} \mathbf{x} + \mathbf{S}^{-1} \mathbf{b}^{(1)}\right) + \mathbf{b}^{(2)}\right) \\[6pt] &= f\!\left(\widehat{\mathbf{W}}^{(2)} f\!\left(\widehat{\mathbf{W}}^{(1)} \mathbf{x} + \widehat{\mathbf{b}}^{(1)}\right) + \mathbf{b}^{(2)}\right), \\[10pt] \mathbf{S} &= \operatorname{diag}(\mathbf{s}), \quad S_{ii} = s_i, \\[6pt] \widehat{\mathbf{W}}^{(2)} &= \mathbf{W}^{(2)} \mathbf{S}, \\ \widehat{\mathbf{W}}^{(1)} &= \mathbf{S}^{-1} \mathbf{W}^{(1)}, \\ \widehat{\mathbf{b}}^{(1)} &= \mathbf{S}^{-1} \mathbf{b}^{(1)}. \end{aligned}\]따라서 앞뒤의 Weight값에 적절한 값을 곱하거나 나누어서, 최종적인 output이 변화하지 않은 상태에서 원하는 가중치 범위로 수정할 수 있다는 것을 확인할 수 있다. 이 가정에서 최종적으로 원하는 것은 각 Channel 별로 최종적인 Precision을 최대화하는 것을 목표로 한다. 이를 위해서 Channel 별로 Precision을 $\hat{p}i^{(1)} = \frac{\hat{r}_i^{(1)}}{\hat{R}^{(1)}}$로 설정한다. 우리가 원하는 것은 모든 Channel에서의 Precision을 최대화하는 것이므로, 결과적으로 $\max{\mathbf{s}} \sum_i \hat{p}_i^{(1)} \hat{p}_i^{(2)}$를 만족하는 s를 찾는 문제를 풀어야 한다.
- $\hat R^{(1)}$ = $\hat W ^{(1)}$의 표현범위
- $\hat r_i^{(1)}$ = $\hat W^{(1)}$의 i번째 channel의 표현범위를 의미한다.
결국 FC를 가정한다면, i번째 Activation을 만들기 위한 이전 Layer Weight의 범위가 $\hat r_i^{(1)}$이고, 이후 Input뉴런을 처리하는 범위가 $\hat r_i^{(2)}$에 해당한다. 연결되는 Weight값들을 의미한다는 것을 기억해야 한다.
\[\begin{equation} \max_{\mathbf{s}} \sum_{i} \hat{p}^{(1)}_{i}\,\hat{p}^{(2)}_{i} \tag{9} \end{equation}\]따라서 s를 제대로 설정해야 하는데, 최적 S를 달성하는 과정 중 하나가
\[\begin{equation} s_i \;=\; \frac{1}{r^{(2)}_{i}} \sqrt{\,r^{(1)}_{i}\,r^{(2)}_{i}\,} \tag{11} \end{equation}\]위와 같이 설정하는 방법이다. 모든 channel(Activation output -> Input)연결 별로 위 과정을 거쳐서 원하는 9번 식을 달성하기 위함이다. 물론 여러 연결 과정이 있다면 순차적으로 여러번 S를 적용해야 하는 것이 당연하다.
다만, 곱해지는 S의 값에 따라서 Bias값이 너무 커지는 경우가 존재한다. 너무 큰 경우 이를 다음 단에서 흡수할 수 있도록 해야 Quantization이 제대로 이루어지기 때문에, 아래와 같은 과정을 고쳐야 한다.