
소개
FocusLLM은 디코더 전용(Decoder-only) LLM의 컨텍스트 길이를 확장하여, 매우 긴 시퀀스에서도 모델이 관련성 있는 정보에 집중할 수 있도록 설계된 프레임워크입니다. 이를 위해 긴 입력을 메모리와 로컬 컨텍스트로 나누고, 병렬 디코딩을 통해 효율적으로 처리합니다.
1. 배경
1.1 Attention 메커니즘의 복잡도
- 일반적인 Attention은 입력 길이가 길어질수록 계산 복잡도가 급격히 증가합니다.
- 긴 시퀀스에서 모든 토큰을 동일하게 처리하는 것은 비효율적이며, 중요한 정보와 불필요한 정보를 구분하는 메커니즘이 필요합니다.
1.2 목표
- 긴 문서(수천~수만 토큰)에서도 효율적으로 작동
- LLM이 현재 문맥과 관련된 정보만 추출하여 디코딩
- 기존 모델 구조를 크게 변경하지 않고 확장 가능
2. FocusLLM 구조
2.1 기본 표기법
- 긴 시퀀스: ${x_1, …, x_S}$
- Memory tokens: ${x_1, …, x_m}$
- Local tokens: ${x_{m+1}, …, x_S}$
- 메모리를 여러 청크(Chunk) $C₁, C₂, …, C_k$로 분할
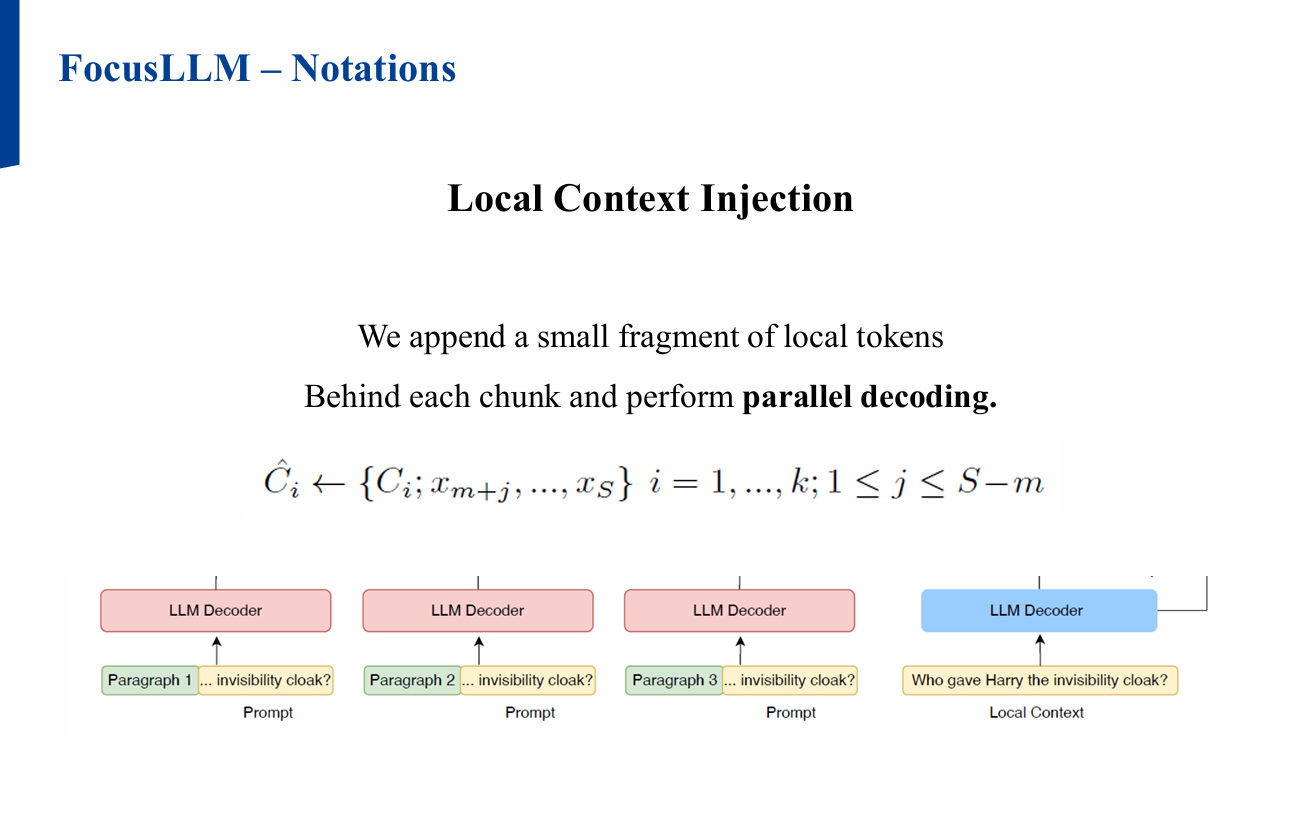
2.2 Local Context Injection
- 각 청크 뒤에 소량의 로컬 토큰을 붙여 병렬 디코딩 수행
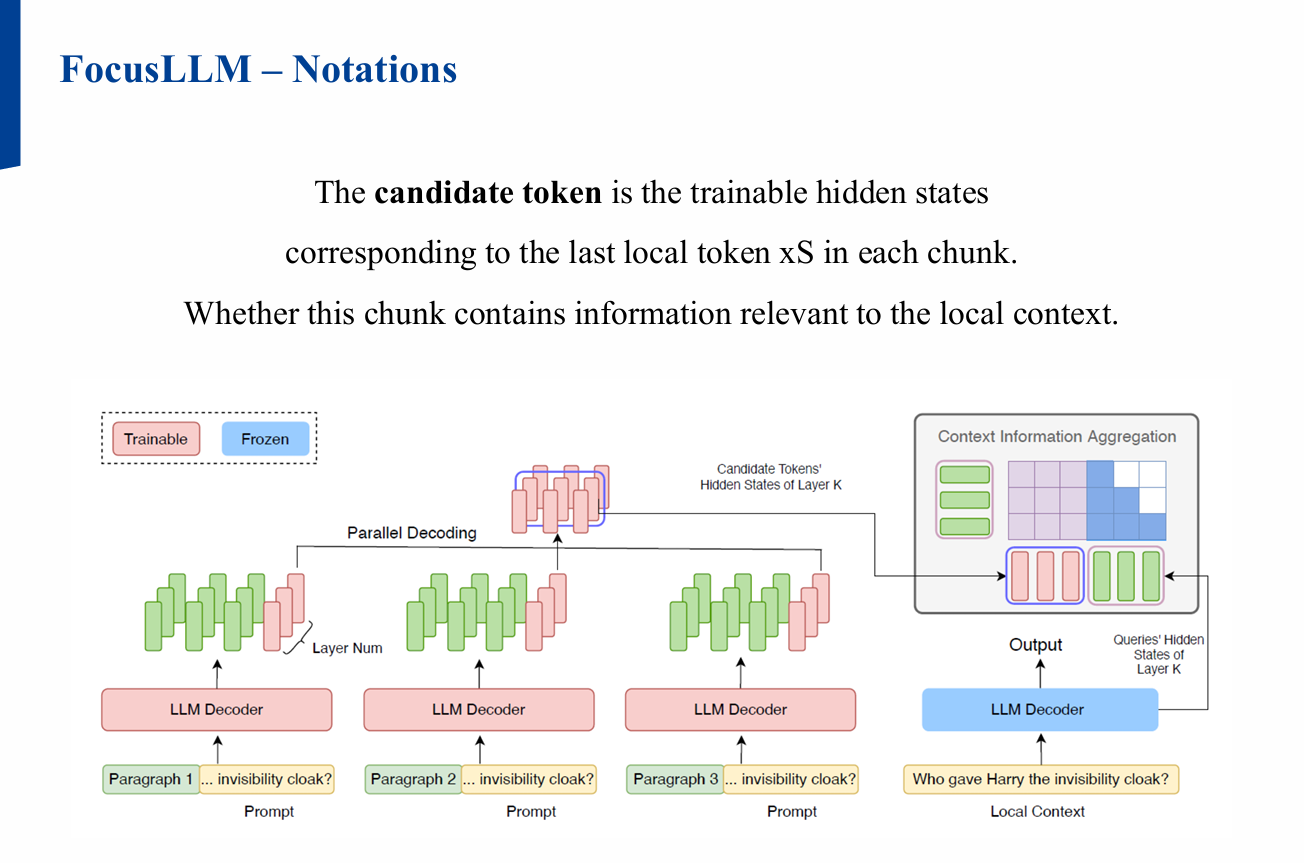
- 병렬 처리된 각 청크의 마지막 로컬 토큰에 해당하는 Candidate token이
로컬 컨텍스트와 관련된 정보를 포함하도록 학습![Figure1]()
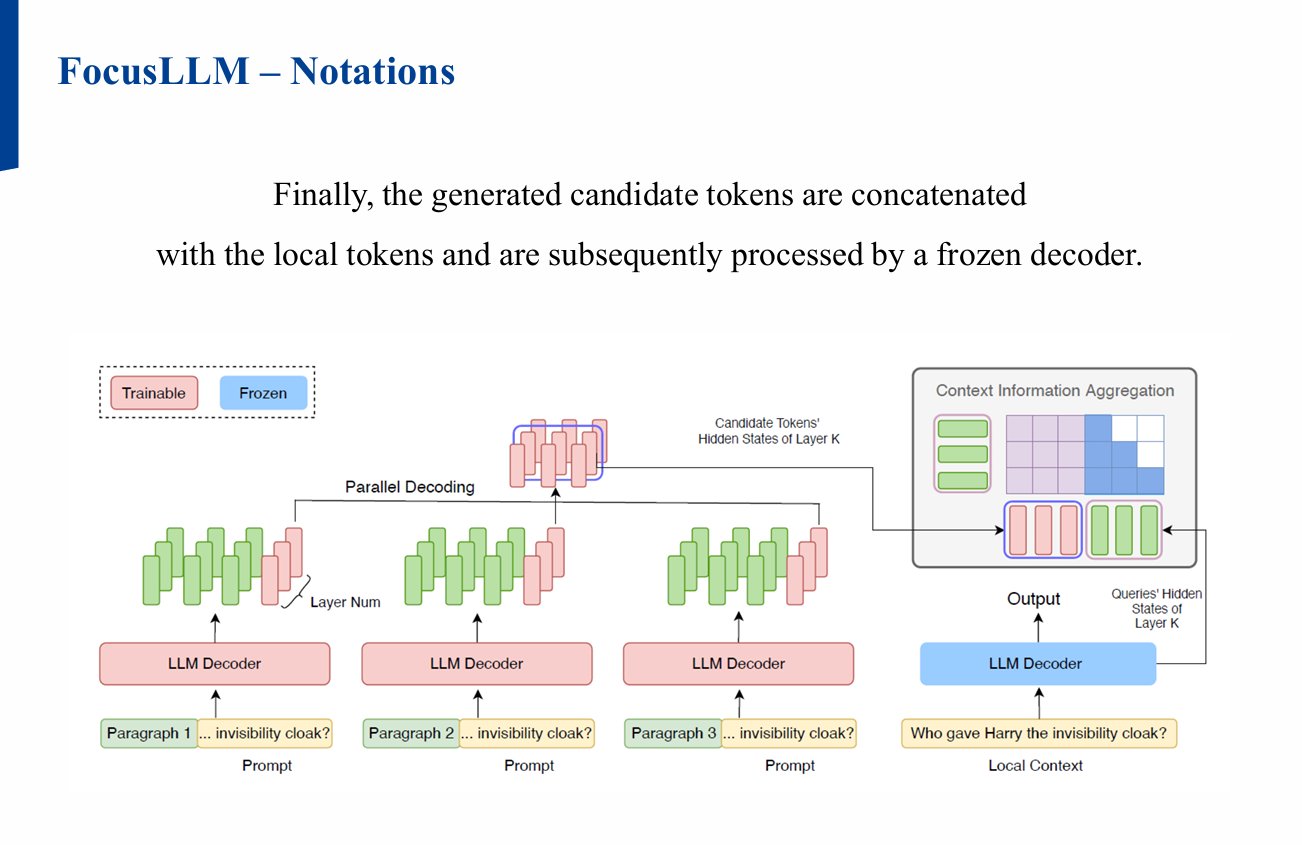
2.3 Candidate Token 결합
- 생성된 Candidate tokens를 로컬 토큰과 결합
- 이후 Frozen decoder를 사용해 최종 처리
![Figure2]()
3. 학습 방식
3.1 Auto-regressive Training
- 다음 토큰 예측 방식으로 학습
- Candidate token이 각 청크의 유용한 정보를 집약하도록 유도
3.2 Joint Loss Functions
- Continuation Loss
- 긴 문서의 마지막 L 토큰을 로컬 토큰으로 선택
- Repetition Loss
- 긴 문서를 전부 메모리로 사용한 뒤,
무작위로 연속된 L 토큰을 로컬 토큰으로 선택
- 긴 문서를 전부 메모리로 사용한 뒤,

4. 실험
4.1 데이터셋
- PG19: 장편 도서
- Proof-Pile: 학술 논문(arXiv)
- CodeParrot: 코드 저장소
- 각 데이터셋에서 100개의 긴 테스트 케이스 평가
4.2 결과
- 긴 문서에서도 효과적으로 관련 정보에 집중 가능
- 기존 Attention 대비 계산 효율성 및 성능 향상 확인
5. 결론
- FocusLLM은 긴 컨텍스트를 효율적으로 처리하기 위한 실용적인 접근입니다.
- 주요 장점:
- 기존 모델 아키텍처 변경 최소화
- 병렬 처리로 속도 향상
- 정보 선택 메커니즘을 통한 성능 개선
- 향후 과제:
발표 자료
- 자세한 내용은 논문이나 아래 발표 자료로 확인 가능합니다.