
From Video Generation to World Model
1. Scaling Foundation World Models as a Path to Embodied AGI
우리가 World Model을 가지고 궁극적으로 하고자 하는 것은 Agent를 위한 무한한 environment를 생성해주는 것이다. 이를 통해서 Agent들은 Simulation이나 passive data를 통해 원하는 목적을 학습할 수 있도록 말이다.
1
2
3
4
5
6
Proposed Recipe for embodied AGI
1. Pretrain highly capable agents from all available data
2. While Improving
a. Generate diverse challenging tasks
b. Select the most interesting ones
c. Train Agent
Embodied AGI로 가는 길을 거칠게 설명하면 위와 같다. 각각의 과정은 Non-Trival하고 각 Task마다 최적의 방법을 찾는 과정을 거쳐야 하며 a, b, c 모두 동시에 병렬적으로 이루어져야 한다.
기존의 알파고나 마인크래프트에서 다이아를 찾는 Task를 생각해본다면 Simulation Environment에서의 RL을 사용한 Agent Training이 진행된 것이다. LLM을 생각해보면 Pretraining 과정을 거치고 원하는 Task에 대한 Fine-Tuning을 거치기 때문에 저 Recipe들을 일부 따른다고 생각할 수는 있다. 하지만, 언어모델을 사용하는 것은 Embodied Task가 아니며, 특정 Task에 대해서 집중적으로 해결할 수는 있지만, 모든 Task에 대해서 미세조정할 수는 없기 때문에 World Model이 해결하고자 하는 수준의 문제는 아니다.
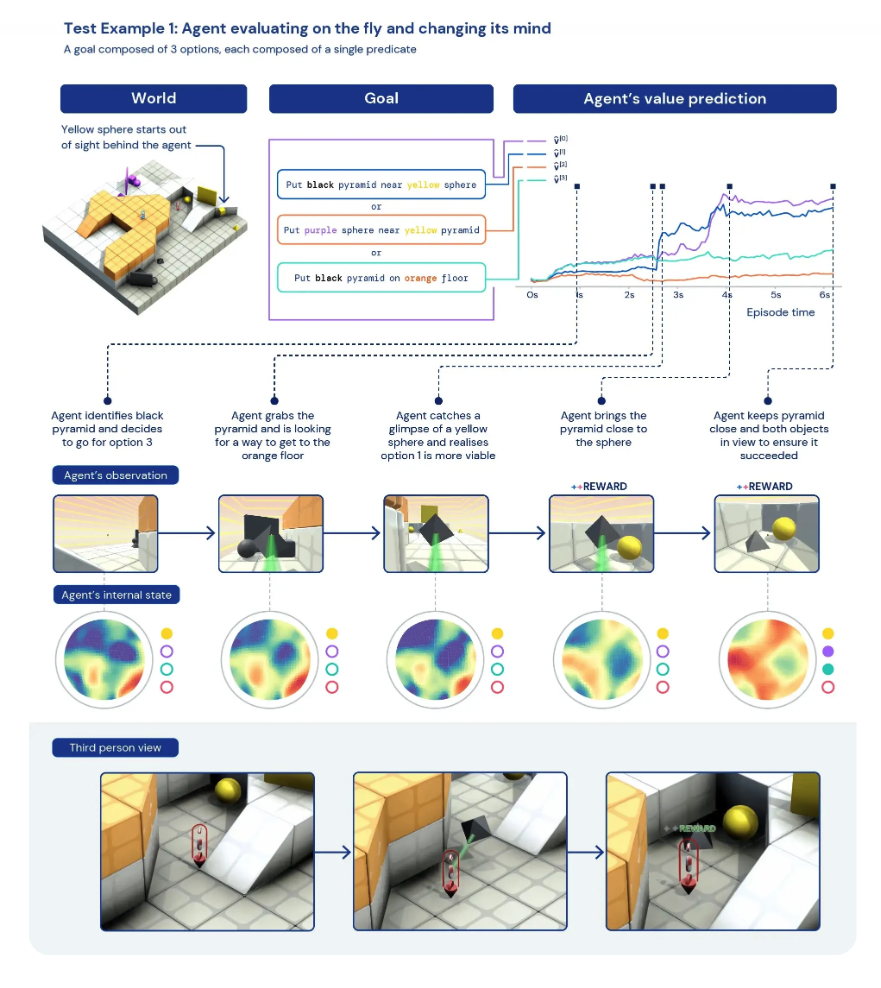
그렇다면 진짜 Embodied AGI를 위한 연구에는 어떤 것이 있을까? Google Deepmind의 가장 대표적인 Embodided AGI 연구는 XLand이라는 연구이다. 25Billion Task가 존재하는 Rich Interactive Environment가 해당하는데, Agent는 Unknown Task를 egocentric view를 통해 해결할 수 있도록 학습된다. 즉, World가 주어지면 Agent는 최초의 Goal만 부여받고, partially observable view에서부터 하나씩 시도하면서 Agent를 학습하는 구조이다. In context Adaption이란 하나의 Task에 대한 시도가 끝나면 이전의 기억을 모두 가지고 다음 새로운 Task를 받는 상태로 진행하는 것이다.
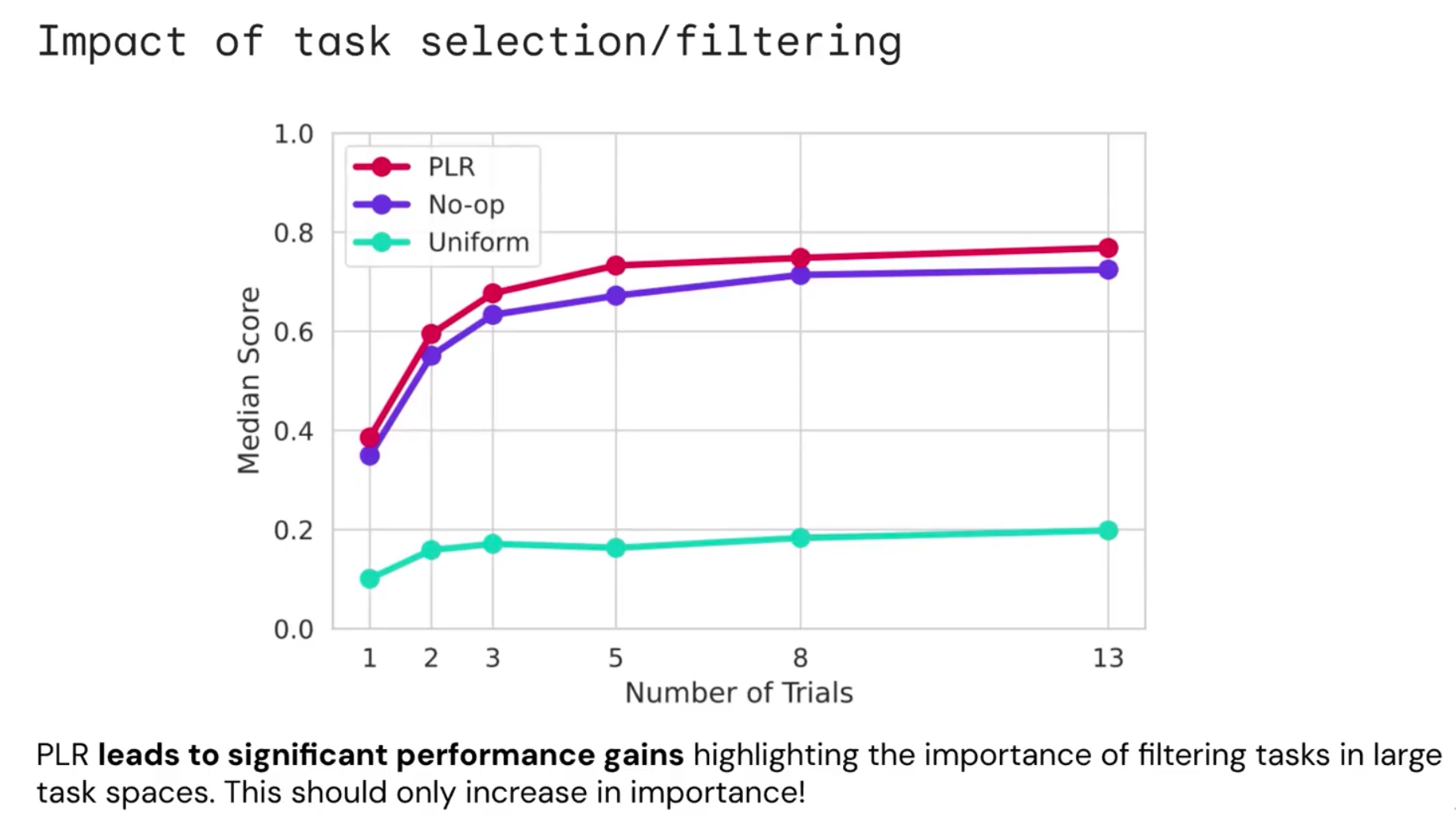
Deep Mind 저자는 이 실험과 관련하여 Training Curriculum이 굉장히 중요했다고 한다. 그냥 무작위의 Task를 받고 학습을 진행한 것은 거의 의미가 없는 민트색 Training Curve를 보이지만, Prioritize level replay를 사용한다면 굉장히 좋은 성능을 얻을 수 있다.
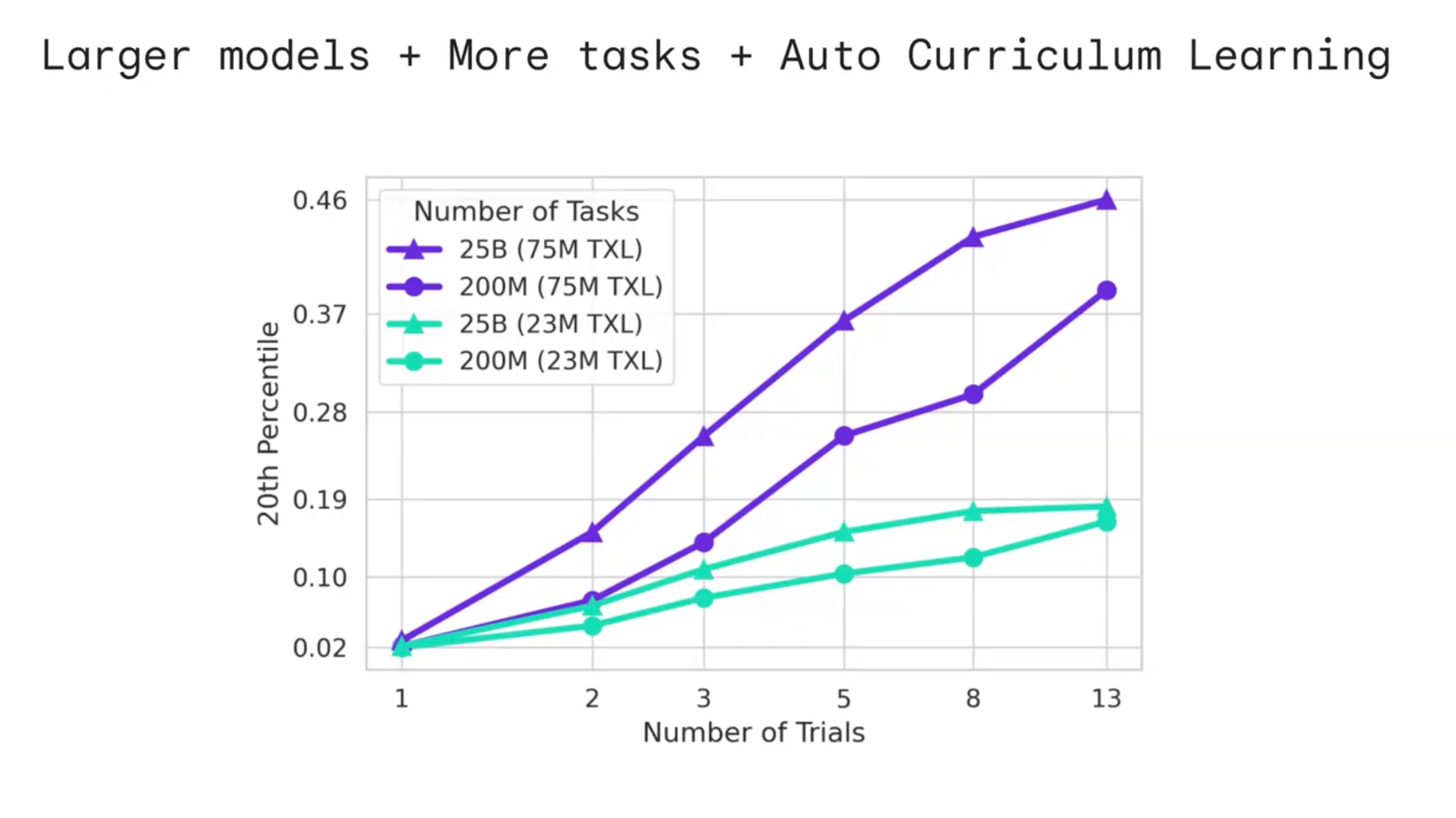 또한, 저자들은 모델의 크기가 커지고, 이에 따라 더 많은 의미있는 Task를 바탕으로 학습을 진행하면 성능이 올라가는 Law of Scaling을 Foundation World Model에 대해서도 확인했다고 한다.
또한, 저자들은 모델의 크기가 커지고, 이에 따라 더 많은 의미있는 Task를 바탕으로 학습을 진행하면 성능이 올라가는 Law of Scaling을 Foundation World Model에 대해서도 확인했다고 한다.
하지만, 이런 내용은 사실 Impressive하지 않다. 작은 픽셀 레벨에서의 실험 결과와 Actual Real World는 너무나도 큰 간격이 있기 때문이다. 사실 지금 나오는 World Model들 또한 Real World라고 전혀 부를 수 없는 수준이다. 또한 우리는 Agent를 주어진 환경에서 학습시키는 것을 목적으로 하는데, 이 Agent 성능의 Upper bound는 Environment에 의해 정의된다. 우리가 더 일반적인 Agent를 학습시키길 원한다면 더 Rich한 정보를 가진 Environment를 생성하는 것이 선수되어야 함이 자명하다. 이렇기에 Simulation을 생성하는 것이 어쩌면 맞는 길이 아닐지도 모른다.
1
2
3
4
5
6
Proposed Recipe for embodied AGI
1. Pretrain highly capable agents from all available data
2. While Improving
a. Generate diverse challenging tasks (With Foundation World Model)
b. Select the most interesting ones (With AutoCurriculum Learning)
c. Train Agent (With Model-based RL)
그렇다면 우리는 위에서 생각해본 Embodied AGI로 가는 길을 더 자세하게 생각해볼 수 있다. Foundation World Model을 사용하여 굉장히 다양한 Task를 만들어내는 것에서부터 시작해야 한다. Foundation WM은 우리가 생각할 수 있는 그 어떤 것이든 생성할 수 있기 때문이다. 이후 간단한 실험 결과에서 확인했던 것처럼 생성한 Task들 중에서 의미있는 Task에 관해 학습하기 위해 AutoCurriculum Learning을 진행해야 한다. 이후 실제로 Agent를 학습하는 과정을 Model based RL로 진행한다.
2. Foundation World Models
위에서 우리는 World Model을 우리가 생각할 수 있는 그 어떤 것이든 생성할 수 있는 모델이라고 정의했다. 더 자세하게는 어떤 의미를 가질까?