
From Video Generation to World Model
1. Scaling Foundation World Models as a Path to Embodied AGI
우리가 World Model을 가지고 궁극적으로 하고자 하는 것은 Agent를 위한 무한한 environment를 생성해주는 것이다. 이를 통해서 Agent들은 Simulation이나 passive data를 통해 원하는 목적을 학습할 수 있도록 말이다.
1
2
3
4
5
6
Proposed Recipe for embodied AGI
1. Pretrain highly capable agents from all available data
2. While Improving
a. Generate diverse challenging tasks
b. Select the most interesting ones
c. Train Agent
Embodied AGI로 가는 길을 거칠게 설명하면 위와 같다. 각각의 과정은 Non-Trival하고 각 Task마다 최적의 방법을 찾는 과정을 거쳐야 하며 a, b, c 모두 동시에 병렬적으로 이루어져야 한다.
기존의 알파고나 마인크래프트에서 다이아를 찾는 Task를 생각해본다면 Simulation Environment에서의 RL을 사용한 Agent Training이 진행된 것이다. LLM을 생각해보면 Pretraining 과정을 거치고 원하는 Task에 대한 Fine-Tuning을 거치기 때문에 저 Recipe들을 일부 따른다고 생각할 수는 있다. 하지만, 언어모델을 사용하는 것은 Embodied Task가 아니며, 특정 Task에 대해서 집중적으로 해결할 수는 있지만, 모든 Task에 대해서 미세조정할 수는 없기 때문에 World Model이 해결하고자 하는 수준의 문제는 아니다.
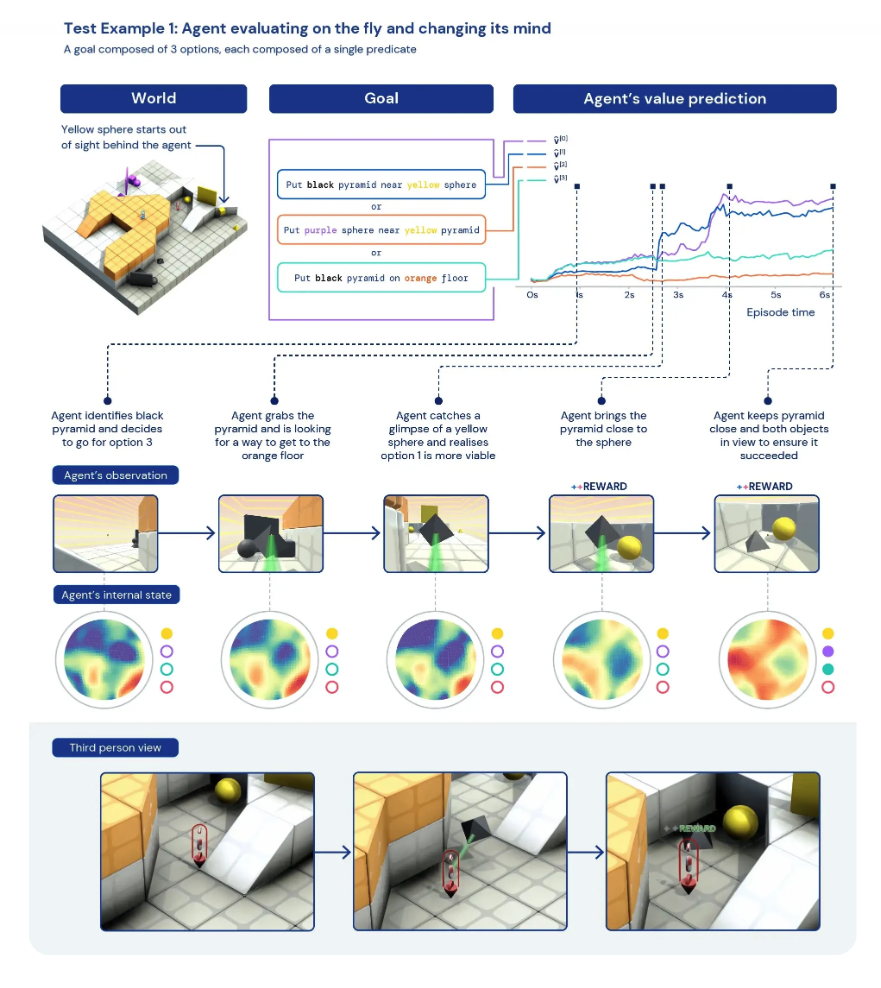
그렇다면 진짜 Embodied AGI를 위한 연구에는 어떤 것이 있을까? Google Deepmind의 가장 대표적인 Embodided AGI 연구는 XLand이라는 연구이다. 25Billion Task가 존재하는 Rich Interactive Environment가 해당하는데, Agent는 Unknown Task를 egocentric view를 통해 해결할 수 있도록 학습된다. 즉, World가 주어지면 Agent는 최초의 Goal만 부여받고, partially observable view에서부터 하나씩 시도하면서 Agent를 학습하는 구조이다. In context Adaption이란 하나의 Task에 대한 시도가 끝나면 이전의 기억을 모두 가지고 다음 새로운 Task를 받는 상태로 진행하는 것이다.
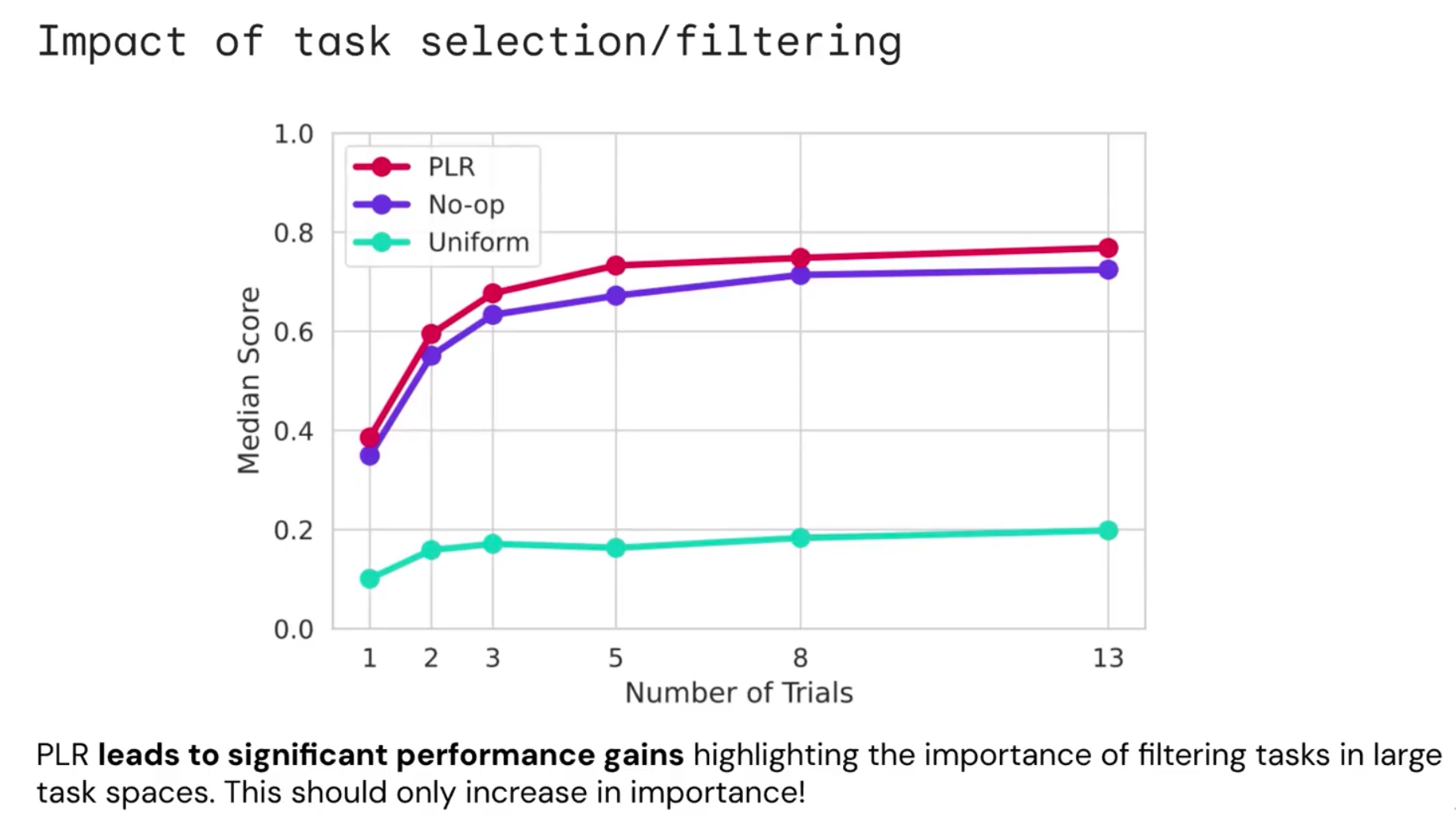
Deep Mind 저자는 이 실험과 관련하여 Training Curriculum이 굉장히 중요했다고 한다. 그냥 무작위의 Task를 받고 학습을 진행한 것은 거의 의미가 없는 민트색 Training Curve를 보이지만, Prioritize level replay를 사용한다면 굉장히 좋은 성능을 얻을 수 있다.
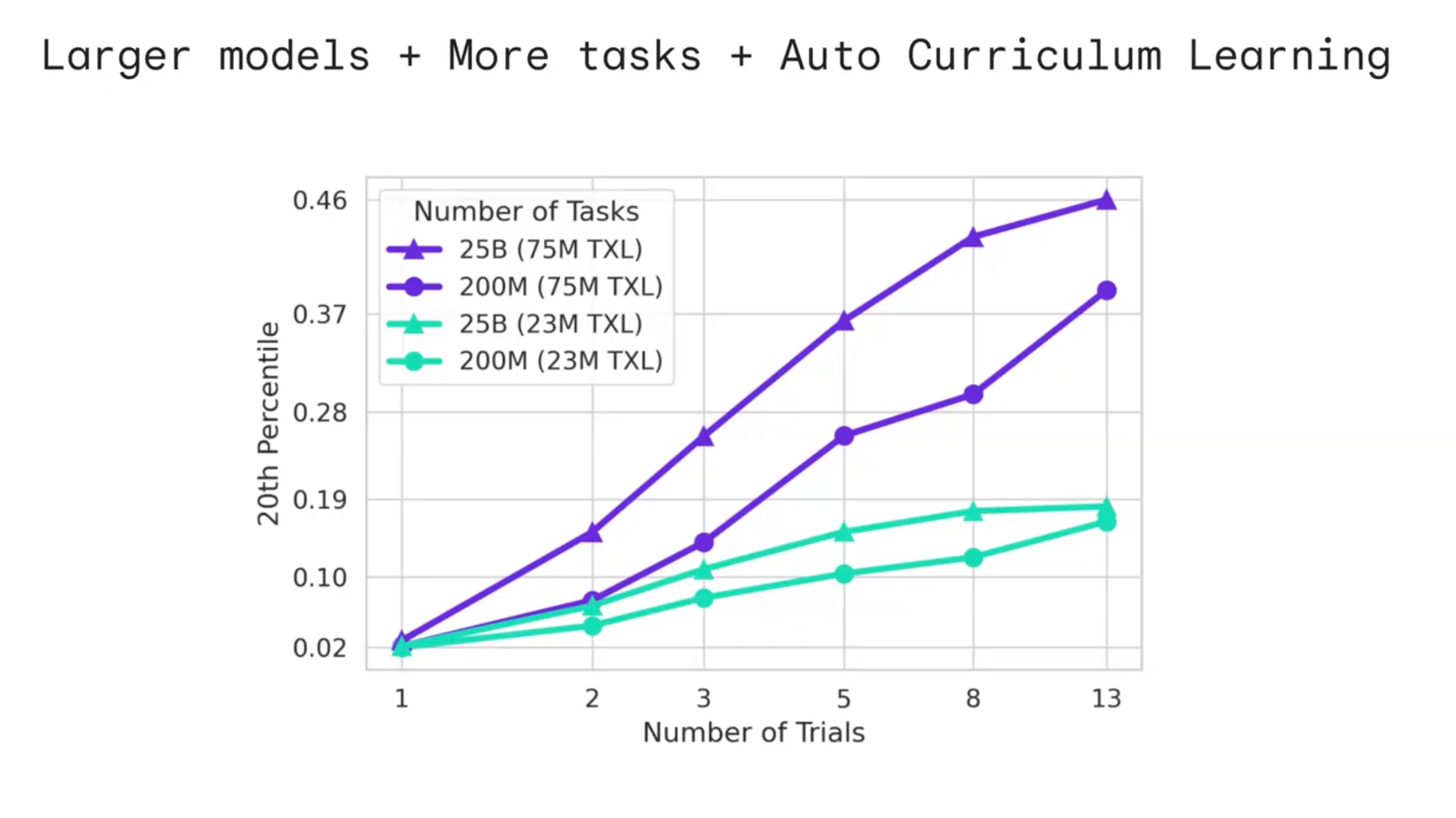 또한, 저자들은 모델의 크기가 커지고, 이에 따라 더 많은 의미있는 Task를 바탕으로 학습을 진행하면 성능이 올라가는 Law of Scaling을 Foundation World Model에 대해서도 확인했다고 한다.
또한, 저자들은 모델의 크기가 커지고, 이에 따라 더 많은 의미있는 Task를 바탕으로 학습을 진행하면 성능이 올라가는 Law of Scaling을 Foundation World Model에 대해서도 확인했다고 한다.
하지만, 이런 내용은 사실 Impressive하지 않다. 작은 픽셀 레벨에서의 실험 결과와 Actual Real World는 너무나도 큰 간격이 있기 때문이다. 사실 지금 나오는 World Model들 또한 Real World라고 전혀 부를 수 없는 수준이다. 또한 우리는 Agent를 주어진 환경에서 학습시키는 것을 목적으로 하는데, 이 Agent 성능의 Upper bound는 Environment에 의해 정의된다. 우리가 더 일반적인 Agent를 학습시키길 원한다면 더 Rich한 정보를 가진 Environment를 생성하는 것이 선수되어야 함이 자명하다. 이렇기에 Simulation을 생성하는 것이 어쩌면 맞는 길이 아닐지도 모른다.
1
2
3
4
5
6
Proposed Recipe for embodied AGI
1. Pretrain highly capable agents from all available data
2. While Improving
a. Generate diverse challenging tasks (With Foundation World Model)
b. Select the most interesting ones (With AutoCurriculum Learning)
c. Train Agent (With Model-based RL)
그렇다면 우리는 위에서 생각해본 Embodied AGI로 가는 길을 더 자세하게 생각해볼 수 있다. Foundation World Model을 사용하여 굉장히 다양한 Task를 만들어내는 것에서부터 시작해야 한다. Foundation WM은 우리가 생각할 수 있는 그 어떤 것이든 생성할 수 있기 때문이다. 이후 간단한 실험 결과에서 확인했던 것처럼 생성한 Task들 중에서 의미있는 Task에 관해 학습하기 위해 AutoCurriculum Learning을 진행해야 한다. 이후 실제로 Agent를 학습하는 과정을 Model based RL로 진행한다.
2. Foundation World Models
위에서 우리는 World Model을 우리가 생각할 수 있는 그 어떤 것이든 생성할 수 있는 모델이라고 정의했다. 더 자세하게는 어떤 의미를 가질까?
1
2
World Model
f : State x Action -> State Distribution
World Model이 무엇인지에 관해선 다양한 해석이 존재할 수 있다. 발표자는 World Model은 Action이 필요하고, 해당 Action으로 인한 Outcome을 활용/개입할 수 있어야 한다고 주장한다. 마치 강화학습처럼 어떤 행동을 해야 하는지를 찾고 시뮬레이션하며 학습하는 과정이 Real World에 대해서도 진행되어야 한다는 것을 의미한다. 즉, 내가 이전에 공부한 Video Generation Model, T2V Model은 한 프롬프트에 대한 비디오 생성 과정을 의미하므로 궁극적으로는 World Model이라고 볼 수 없다. 간단하게는 이를 Sequential하게 이어붙여 Action을 할 수 있는 구조로 변경해주어야 한다.
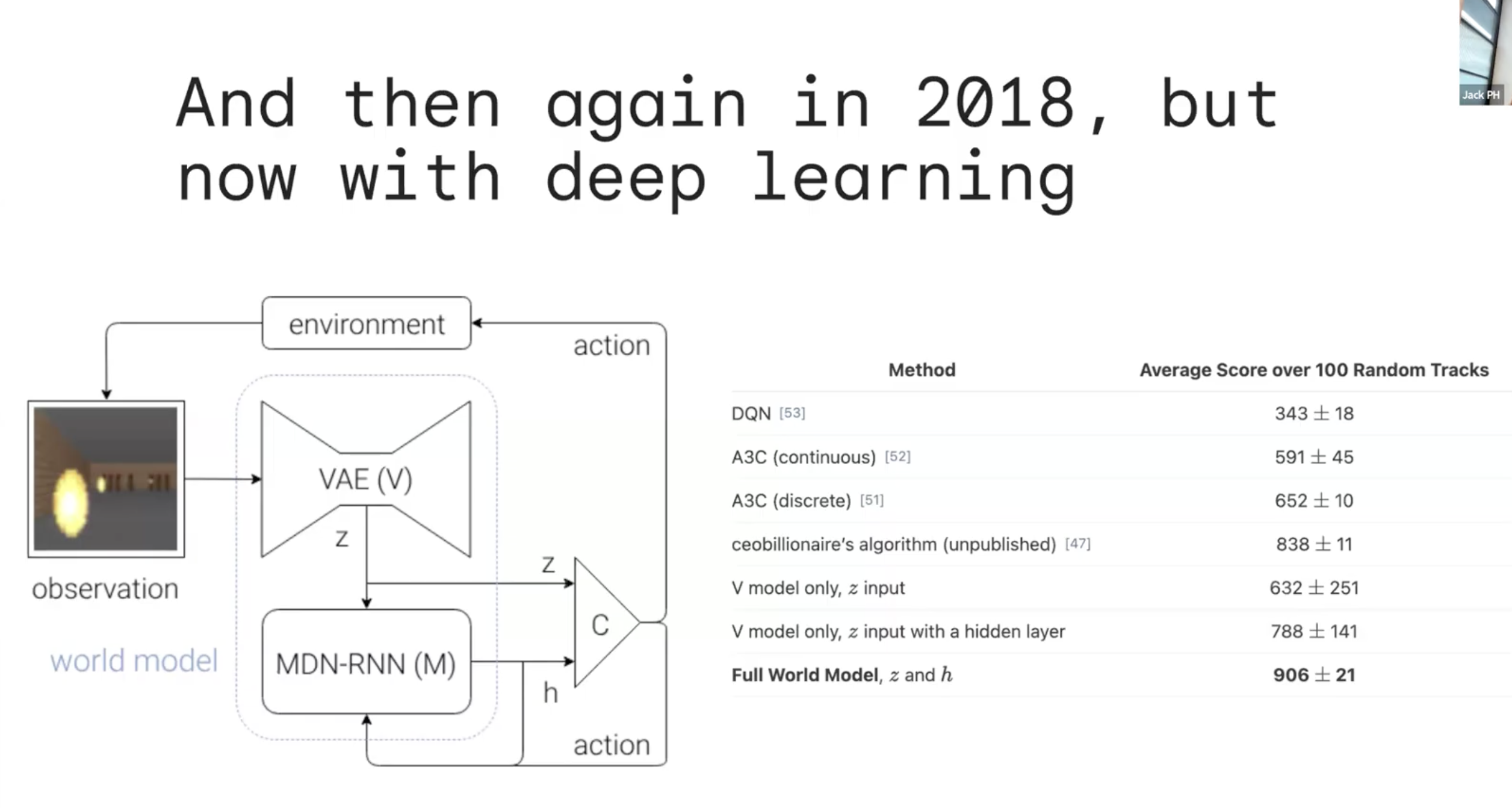
초기의 World Model을 활용한 예시는 Race Track 학습과정에서 Offline WM을 활용한 학습을 진행한 경우 일반화 성능이 굉장히 좋아짐을 확인했다고 한다. 이를 위해서는 당연히 WM을 제대로 설계하는 과정이 필요하지만, WM이 주어졌을 때, Policy를 제대로 학습하는 것이 굉장히 중요하다. 이와 관련해서는 다행히 많은 연구가 이루어졌고, DreamerV3와 같은 연구들이 존재한다.
또한, Single Task에 대한 World Model Training은 이미 잘 이루어지고 있다고 주장한다. Minecraft, Doom, Gaia-2등의 단일한 목표를 가진 World Model에 관해서는 굉장히 학습이 잘 되고 있는 상황이다. 다만, Foundation World Model Training은 아직 미해결 과제이다. Veo-2와 같은 생성모델이 등장하긴 했지만 이는 앞서 언급한 것처럼 Action이라는 정보는 들어가지 않기 때문에 제대로 된 World Model이라고 부를 수 없다.
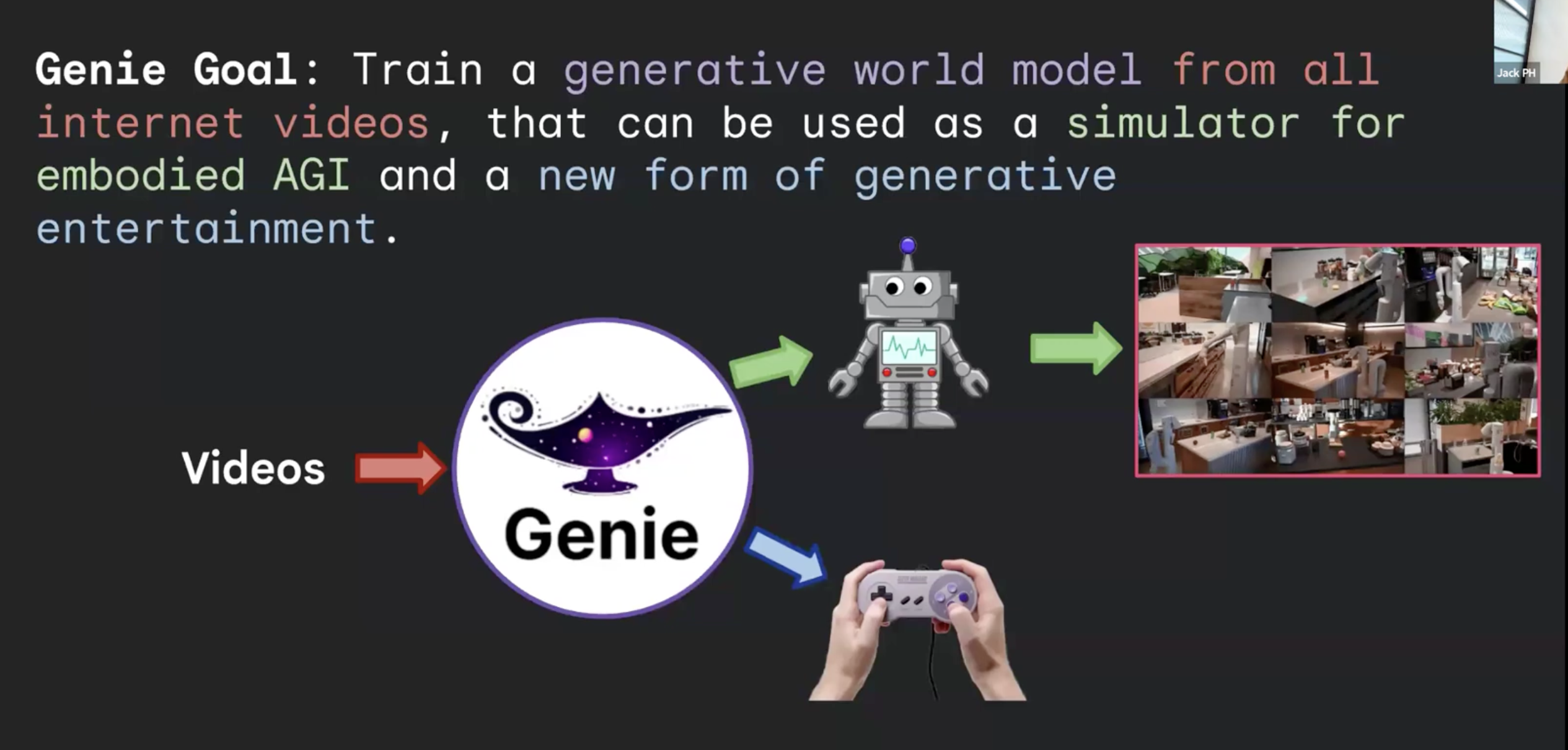 그렇다면 World Model을 학습하는 과정에 필요한 데이터를 어떻게 얻을 수 있을까? Minecraft나 car driving의 예시에서는 당연히 Video와 Action에 대응하는 데이터들을 생성할 수 있겠지만, 사실 인터넷 상에 존재하는 거의 대부분의 영상 데이터는 Action이라는 것이 존재하지 않는 데이터이다. Genie Project는 인터넷 상에 존재하는 이미지 데이터들을 활용하여 World Model을 학습할 수 있는 데이터로 변환하는 프로젝트라고 이해할 수 있다.
그렇다면 World Model을 학습하는 과정에 필요한 데이터를 어떻게 얻을 수 있을까? Minecraft나 car driving의 예시에서는 당연히 Video와 Action에 대응하는 데이터들을 생성할 수 있겠지만, 사실 인터넷 상에 존재하는 거의 대부분의 영상 데이터는 Action이라는 것이 존재하지 않는 데이터이다. Genie Project는 인터넷 상에 존재하는 이미지 데이터들을 활용하여 World Model을 학습할 수 있는 데이터로 변환하는 프로젝트라고 이해할 수 있다.
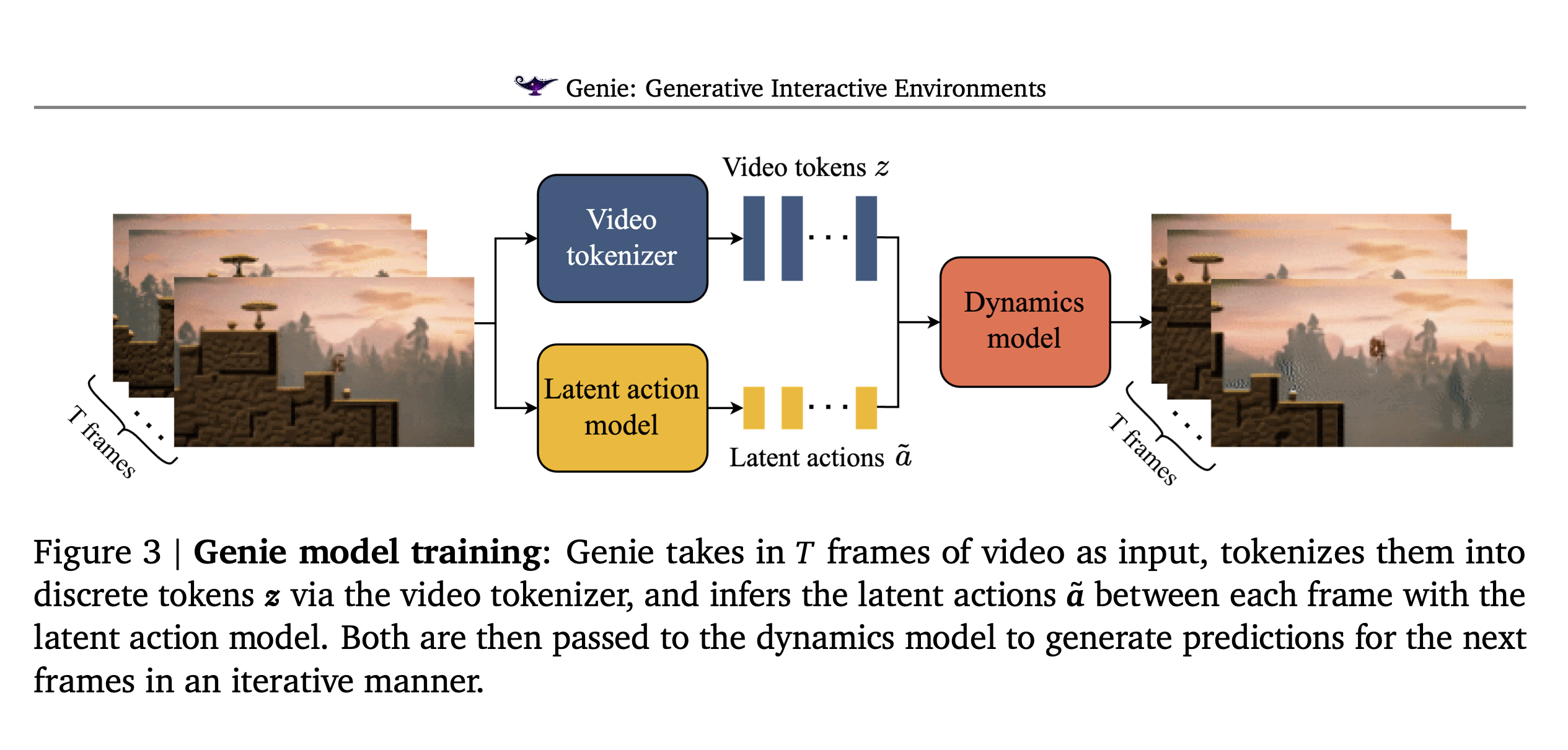
위 Figure는 Genie Model의 훈련 과정을 자세히 설명한다. T Frame Video를 받고 이를 Video Tokenizer를 활용하여 Discrete Token $z$로 변환하는 과정을 거친다. 이후 Latent action model을 통해서 두 프레임 사이의 latent action $\hat a$를 예측하도록 한다. 또한 이를 Dynamic model에 넣어 개별 video frame에 대한 다음 frame을 생성하도록 한다.
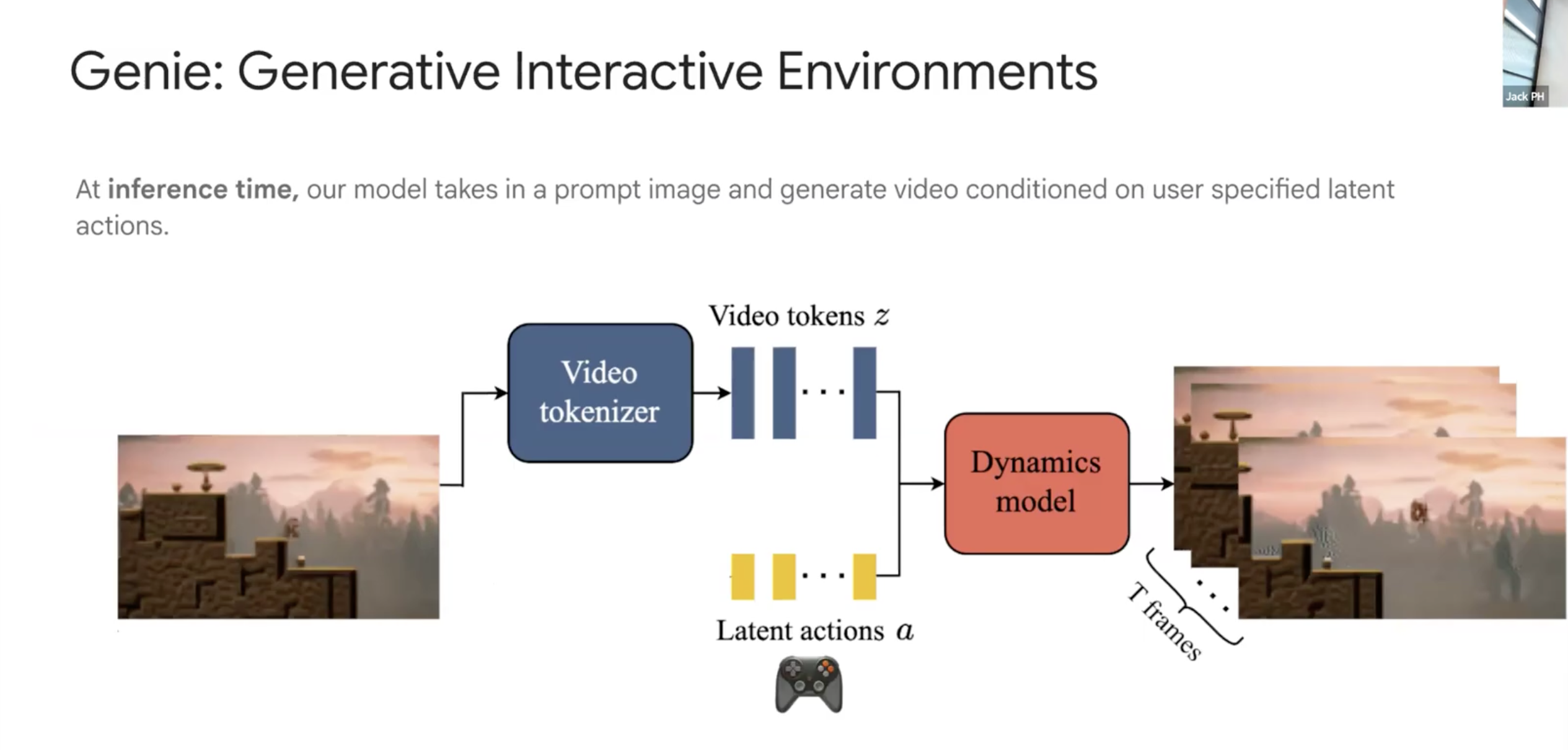
실제 Inference 과정에서는 사용자의 Latent Action $a$를 받아 해당 action에 대응하는 다음 Frame을 생성하도록 할 수 있다. Genie는 처음 보는 Input Image에 대해서 Input Action에 따른 Frame을 생성하도록 일반화가 굉장히 잘 될 수 있음을 확인했다고 한다.
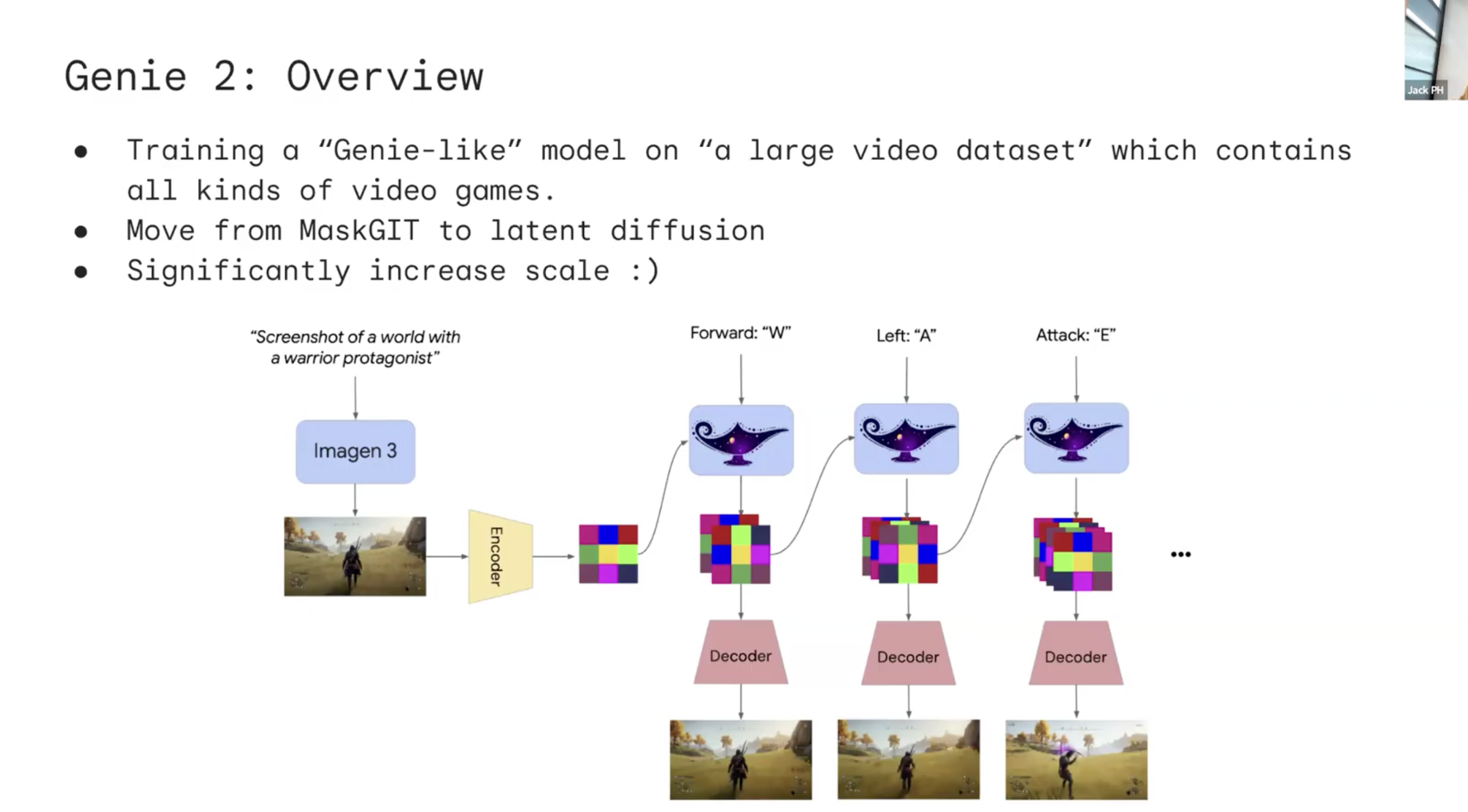
이후, Genie-2모델을 활용하여 더 일반적인 World Model으로 발전시켰다고 한다. Google에서 발표한 Imagen 3을 활용하여 주어진 프롬프트에 맞는 처음 이미지를 생성하고, 이후 사용자의 Action Input을 기반으로 다음 Frame을 Inference/Decoding하는 과정으로 동작한다고 한다. 이전 Frame을 Context로 활용하여 Autoregressive하게 프레임을 생성하는 방식을 택했다.
저자들은 Physics를 따로 주지 않았음에도 기본적인 역학을 따르는 것처럼 보인다고 했고, Google에서 발표한 3D Virtual Environment Agent인 SIMA를 사용하여 서로 Genie <-> SIMA대응 파이프라인으로 여러 실험도 진행했다고 한다. 또한, Temporal Consistency도 꽤나 잘 유지되는 것처럼 보인다고 했다.
Q&A
- Long Context Generation 과정에서 오류는 없었는가? 당연히 오류는 존재했다. 동일한 길이의 생성이라도, 픽셀 변화가 많이 요구되는 Action을 빈번하게 사용한 경우라면 더 많은 오류가 존재했다.
- 다른 Memory Mechiasm이 위 문제를 해결할 수 있는가? Genie-2 모델에 관해서 자세한 Detail을 설명하지는 않았지만 Autoregresive model이라고 설명하긴 했다. 기존에 LLM과 관련한 연구들을 잘 접목시키면 이 오류를 잘 다룰 수 있을 것이다.
3. Physics-Grounded World Models : Generation, Interaction, and Evaluation
최근 다양한 Video Generation Model이 나왔고, 굉장한 시각적 발전을 이루긴 했지만, World Model은 단순히 보기 좋은 이미지를 생성하는 것에 그치면 안된다. World Model은 action을 바탕으로 Environment가 어떻게 변화하는지를 제대로 이해해야 하며 정확하게 Agent와 Interact할 수 있어야 한다.
다만, Video Generation Model은 이 관점에서 봤을 때 굉장히 많은 문제점이 있다.
- Precise Action Control이 불가능함. (컵을 10cm 옮겨라)
- Physical Consistency가 부족함. (물체가 복사되었다 사라졌다 반복함)
- Efficiency가 떨어짐. (CG Render를 사용하면 굉장히 효율적으로 프레임을 생성)

그렇다면 우리가 LLM에서 했던 것처럼 단순히 model size를 scaling하는 과정을 통해서 이 문제를 해결할 수 있을까? 이를 위해서는 정확한 Action-Video Data가 필요하지만 사실 이는 거의 불가능한 수준이다. 이를 해결하기 위한 Key Idea는 Pixel Generation의 장점은 살리되, 이전의 Physical Representation으로 정확한 Action과 효율적인 Rendering을 진행할 수 있도록 하는 과정을 거치는 것이다. Physics-grounded world model을 총 3가지 관점에서 정리한다.
3.1 Generation of Physics-Grounded World Models
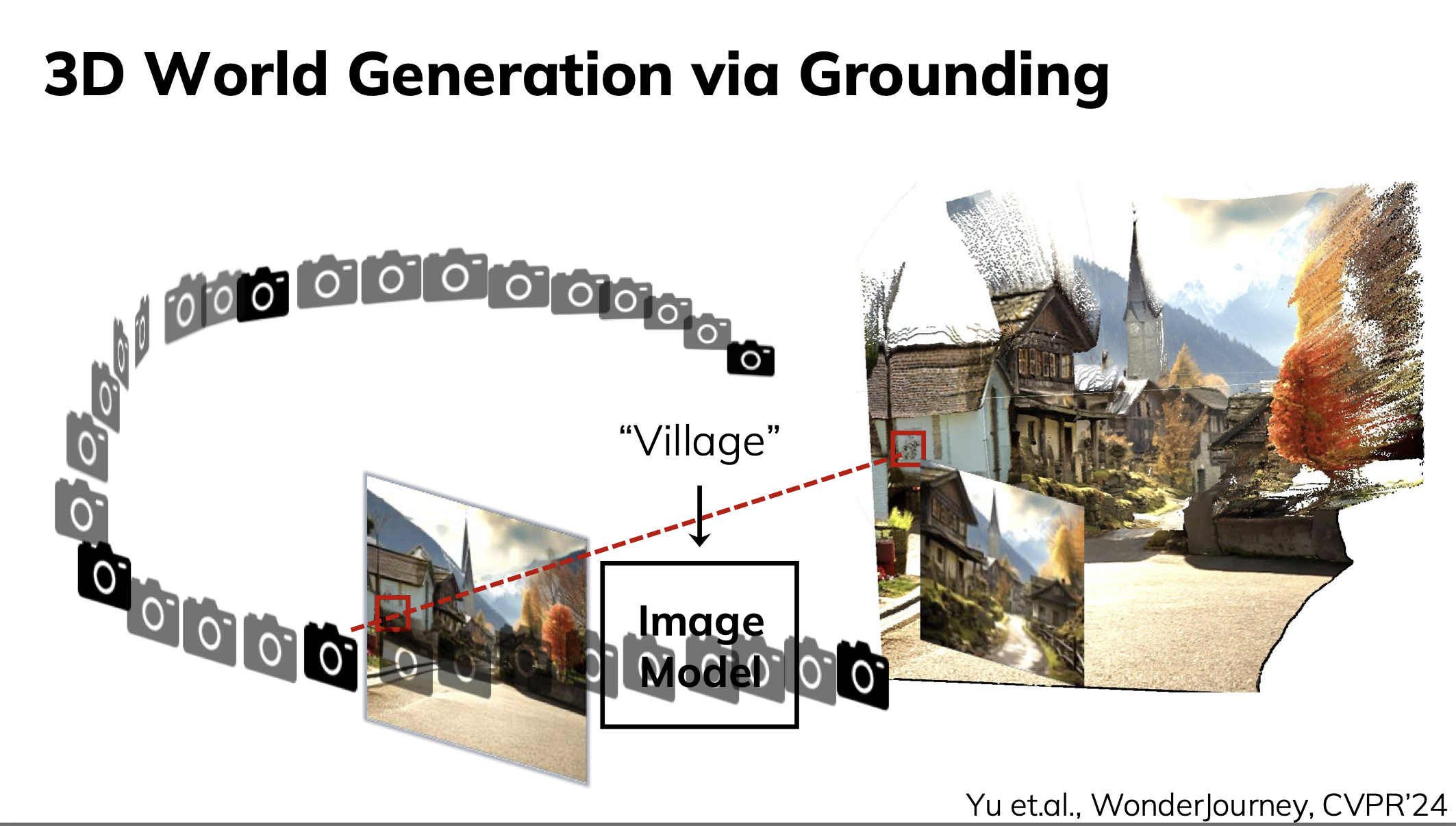
기본적으로 World Generation의 목표는 사용자의 control에 맞는 빠른 3D scene을 생성하는 것을 목적으로 한다. 이는 이전의 3D Representation generation task와 거의 비슷한 양상이다. 기본적으로 Physical grounding은 Image를 생성하고 해당 이미지를 Point Cloud 형태로 Unprojection을 진행한다. 이후 해당 Point Cloud에 대한 다른 시점을 Projection하여 Image를 생성하고, Image Model을 사용하여 빈 공간을 채우고 다시 Unprojection하는 과정을 통해서 전체적인 Point Cloud Map을 생성한다.
다만 위 과정은 너무 시간이 오래 걸린다는 단점이 있다. 이 Physical Grounding과정은 2가지 문제점이 존재함.
- Too many View to generate
- Slow 3D Optimization Methods
위의 문제를 해결하기 위해서 저자들은 FLAGS(Fast Layered Gaussian Surfels)논문을 발표했다.
물론, 이 논문의 contribution은 위 두 문제를 해결할 수 있도록, Single Point View를 생성하면 되고, 빠른 3D Optimization이 가능하다는 점이다.

예를 들어, 위와 같은 간단한 이미지를 고려하더라도 분명히 특정 사물에 의해 가려져 보이지 않는 지점들이 존재하기 때문에, 각각의 사각지대에 대한 View point들을 생성하여 자세한 Point들을 생성해야 한다는 문제점이 있다. 따라서 저자들은 아래와 같이, 3가지 단계로 이미지를 구분하고 BackGround와 Sky에 대한 Inpainting을 진행하여 한번에 3D Scene을 생성하는 과정을 거침으로써 많은 View Point들을 생성하는 것을 방지했다.

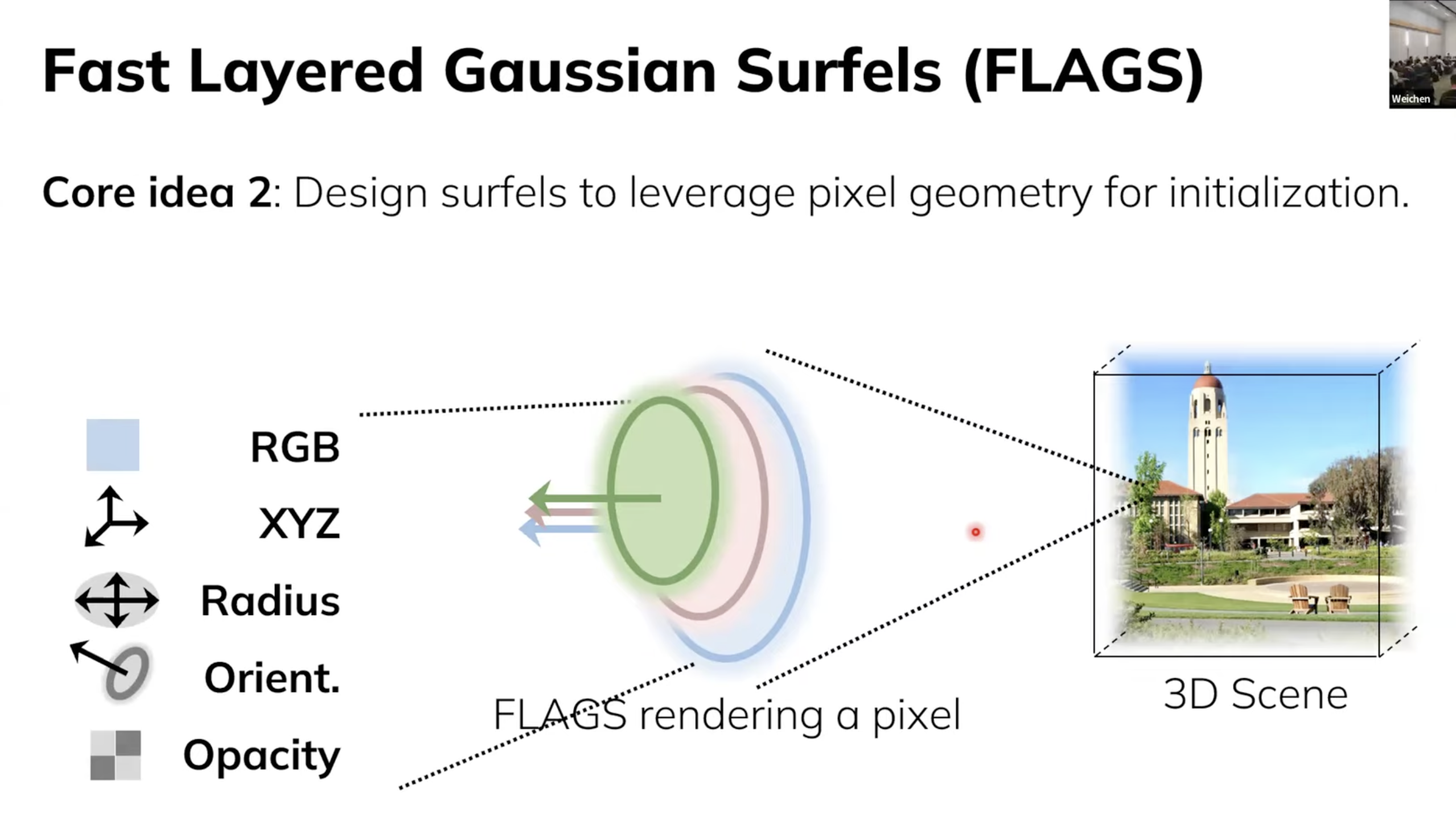
그 다음으로 3D Optimization 과정을 거쳤다고 한다. gaussian surfel들을 생성하기 위해서 위와 같은 5가지 요소가 필수적으로 필요하다. 저자들은 Opacity/불투명도를 제외한 나머지 요소들을 deterministic한 방법으로 결정하여 굉장히 좋은 initialization point를 설정했다고 한다.
RGB,XYZ: 이전에 본 Unprojection 과정을 거쳐 빠르게 진행할 수 있음.Orient: Normal Vector Estimation 방법론을 적용함.Radius: Anti-Aliasing 방법론을 적용함.
위 방법들을 토대로 엄청나게 빠른 최적화를 달성할 수 있었다고 한다.
3.2 Interactions with World Models(Physically Grounded)
위에서 본 것처럼, 사용자들의 ViewPoint에 따라서 Static World는 꽤나 빠른 속도로 생성할 수 있다. 그렇다면 사용자/Agent의 Action과 상호작용하면서 변하는 환경은 어떻게 처리할 수 있을까? 즉, 사용자의 입력을 받아 Physical Law를 따라서 변화하는 World를 어떻게 만들 수 있을까에 관한 내용이다.
3.2.1 Physics Simulation Based Methods

이와 관련하여 기존의 연구들이 존재한다. PhysDreamer 논문에서의 과정을 먼저 설명해보면, 먼저 입력에 대해서 3D Gaussian Splatting을 진행하고, Physical Material Parameter를 VLM이나 Video Gen 모델을 통해서 Approximate한다. 이후, Physic Simulator를 활용하여 각 GS들이 어떤 식으로 표현될 것인가 예측하여 이를 Rendering 과정을 거치게 된다.
다만, 위와 같은 방법은 굉장히 많은 한계점이 존재한다. 특히 이는 Multi-Physics를 다루어야 하는 경우 더 도드라지는데, 일단 Physics Simulation이 완벽하지 않을 뿐만 아니라, 그냥 표면적인 성질 뿐만 아니라 배경의 성질(물의 밀도, 질량, 부피)등의 물리적 성질을 완벽하게 알아야 하기 때문에 현실적으로 오차가 굉장히 크다.
3.2.2 Hybrid Model
Video Generation 모델 자체로 {Action, Video} 쌍을 생성해서 만드는 것은 굉장히 어렵기 때문에 Video Gen Model만을 가지고 좋은 물리적 성질을 가지는 영상을 생성하기란 쉽지 않다. 또한, Video Model은 3D 생성이 불가능하기 때문에 시점 변환 등도 불가능하다. 그렇다면 Physics Simulator를 보정하는 방법으로 진행하면 좋지 않을까? 이 아이디어에서 출발한 것이 하이브리드 모델이다. Physics Simulator를 사용하긴 하지만, Video Model로 Simulation의 내용을 보정하자는 것이 주 아이디어이다.

위 Figure가 사실 어떻게 두 가지를 하이브리드하는 지를 보여준다. 먼저 Simulator가 예측한 내용을 바탕으로 RGB와 Motion을 뽑아내고, 이를 Video Generator에게 넣어주기 위한 준비물로 사용한다. 이후 RGB를 바탕으로 노이즈를 생성하고, Simulated Motion을 사용하여 Noise Video의 Pixel이 움직이는 모습을 주입한다. 이를 바탕으로 우리가 Video Generation을 진행하고, Photometric Loss를 통해서 Simulation을 정제한다.
3.3 Evaluation of World Model
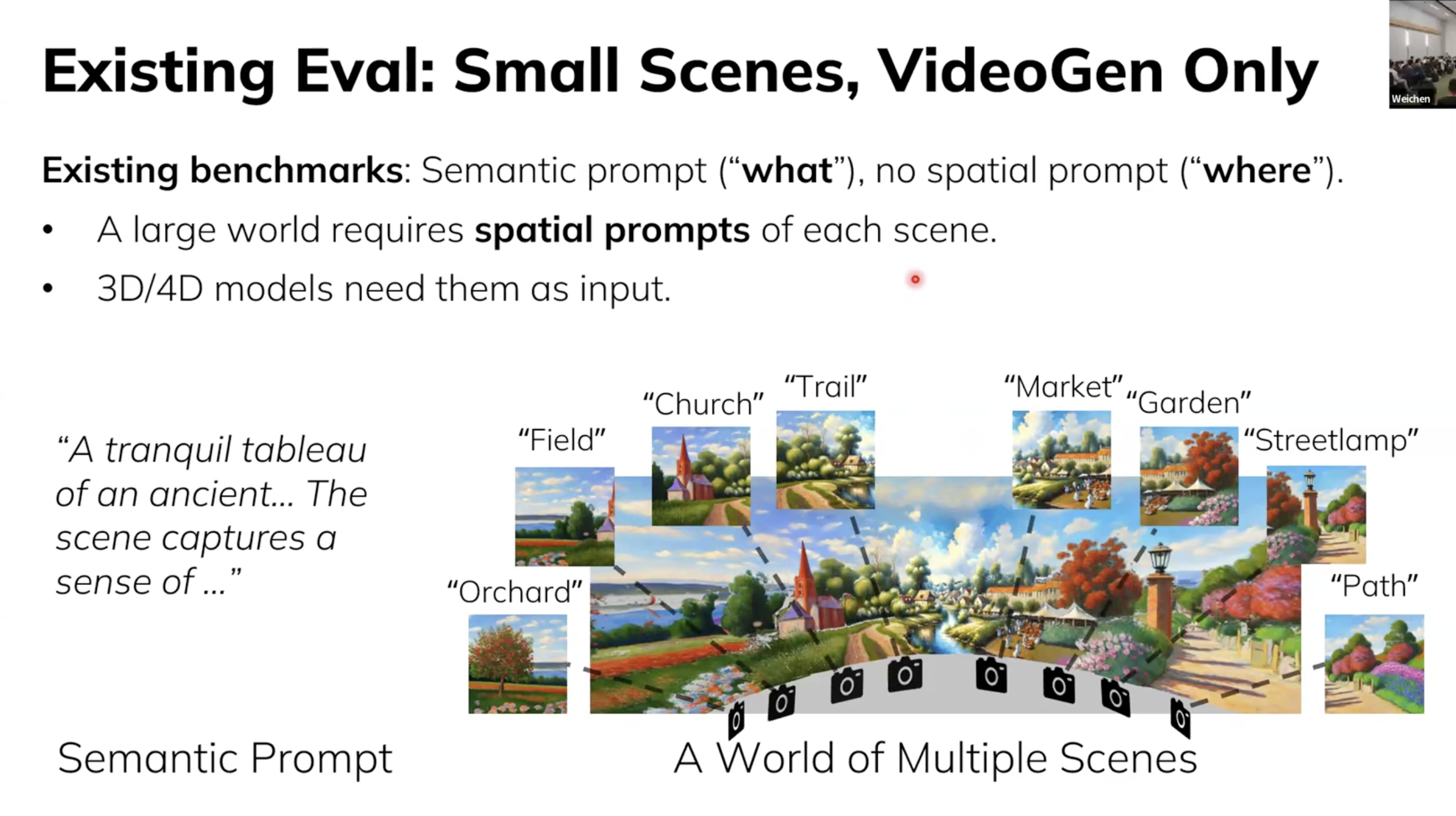
기존의 World Model의 평가 방법들을 보면, 2가지 문제점이 있다.
- 평가 대상이 Video World Model에 한정되어 있다.
- Semantic Prompt는 존재하지만 Spatial Prompt는 존재하지 않는다.(3D 존재)
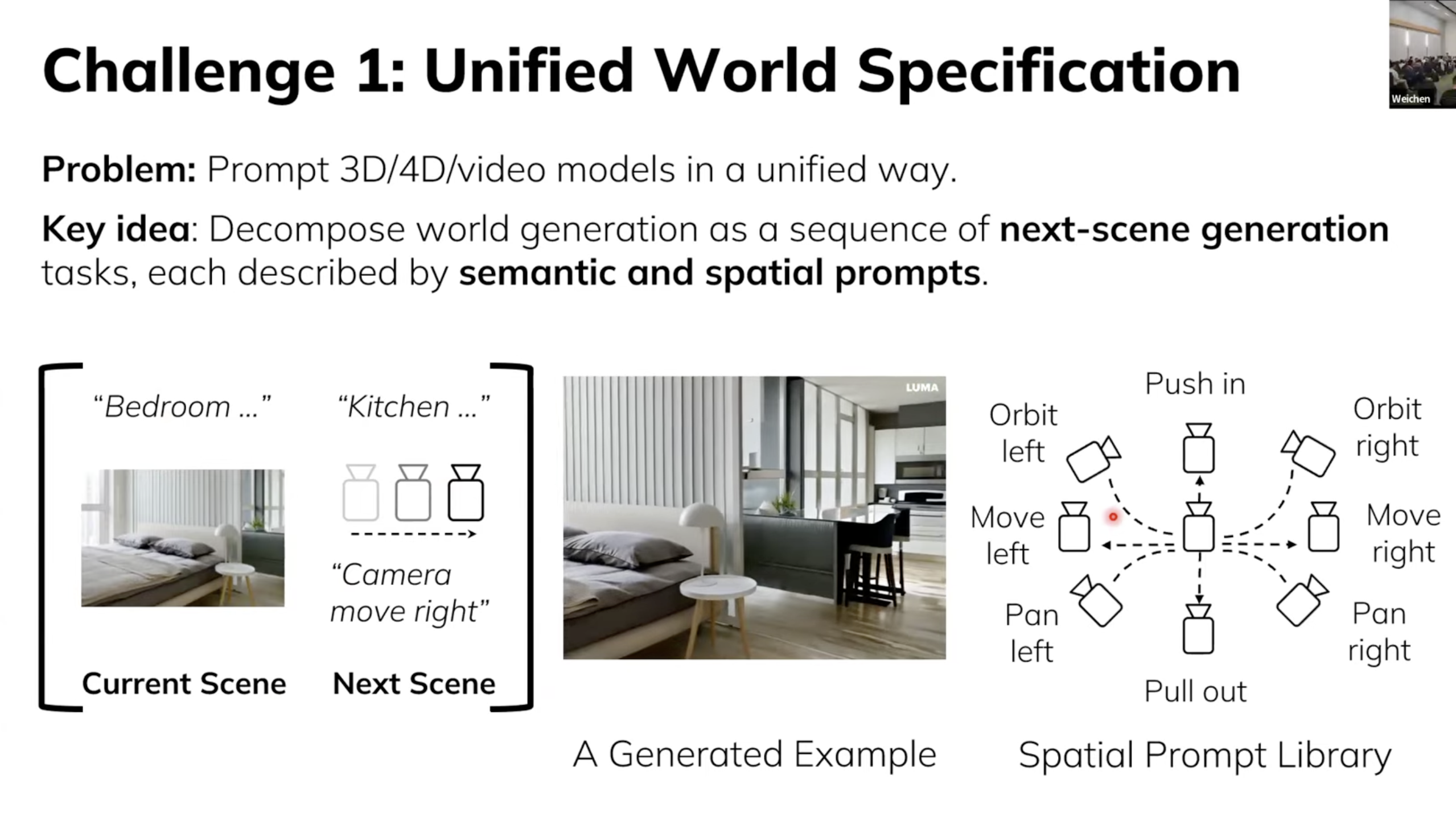
따라서 첫번째 문제를 해결하기 위해 Unified World Specification을 제안한다. 현재 장면을 제공하고, 이후에 생성할 장면에 대한 Semantic Prompt와 Spatial Prompt를 연속하여 제공하는 것으로 구성되는데, Spatial Prompt에 관해서는 카메라를 어떻게 움직여라 등의 정보가 들어간다.

또다른 문제점은, 생성된 결과물은 사실 Camera Motion과 Scene Motion이 결합된 결과라는 점이다. 이는 다시 말해서 내가 보고 있는 Dynamic이 Camera 시점이 변경되어서 발생하는 것인지, 환경 자체가 변화하여 발생하는 것인지를 구분할 필요가 있다는 의미이다. 따라서 이를 해결하기 위해 각각을 평가할 때, 하나는 Static으로 유지해야 한다. Camera motion 평가를 위해 scene을 static으로, scene motion 평가를 위해서는 camera를 static으로 고정해야 한다.
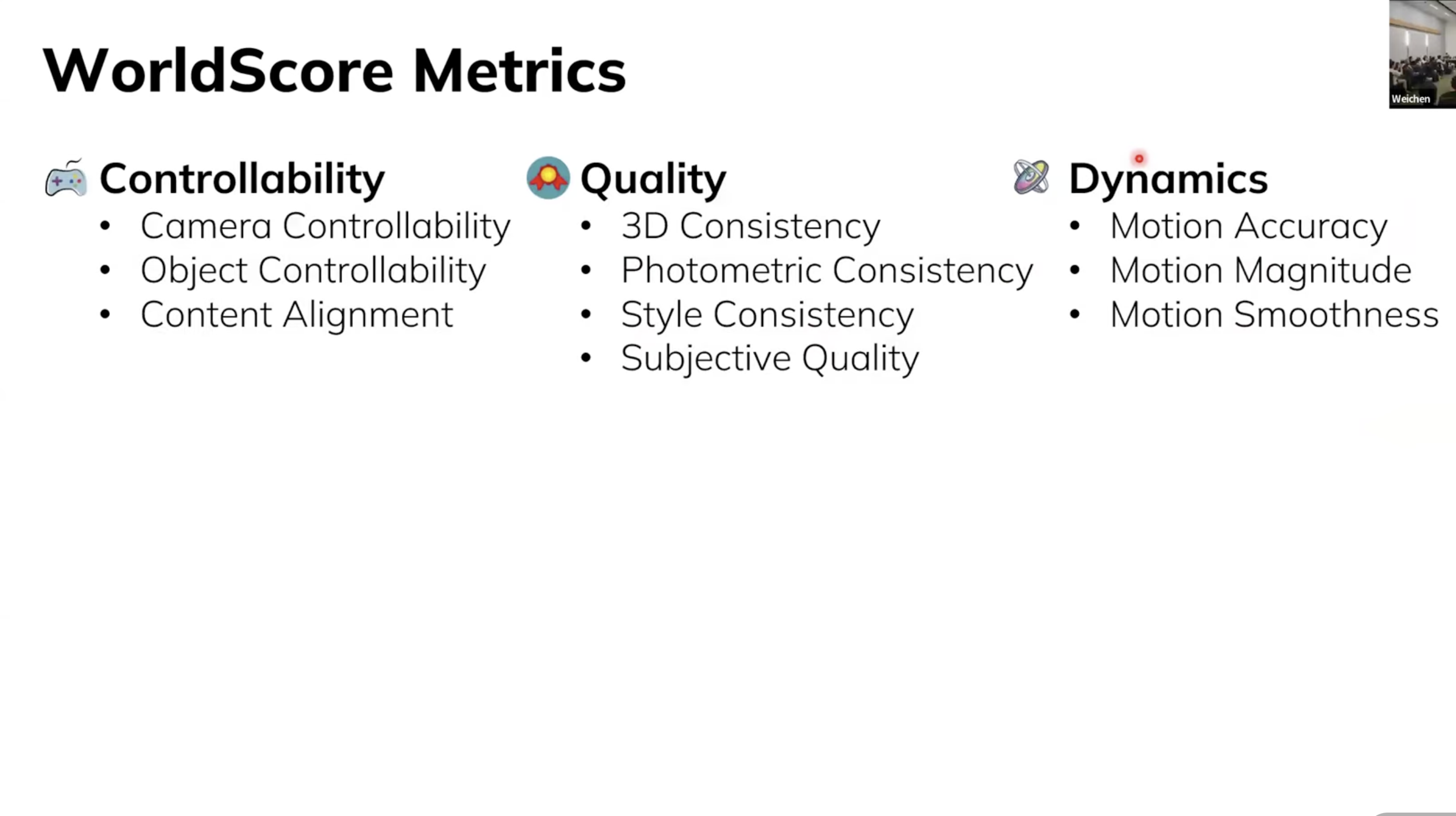
최종적인 World Score이 평가하고자 하는 지표가 위와 같다.
- Controllability
사용자가 준 Input Prompt을 얼마나 잘 따르느냐에 대한 내용이다.
- Camera Controllability : Spatial Prompt를 얼마나 잘 따르냐?
- Object Controllability : Semantic Prompt의 object를 얼마나 잘 따르냐
- Content Alignment : Semantic Prompt를 얼마나 잘 따르냐
- Quality
- 3D Consistency : 시점을 변경할 때, 이전 프레임과의 정합성을 평가
- Photometric Consistency : Flickering이 발생하는지 평가
- Dynamics
- Motion Accuarcy : Motion이 Semantic Prompt와 얼마나 잘 맞는지
- Motion Magnitude : Motion의 크기가 얼마나 큰지?
- Motion Smoothness : Optical Flow의 Smootheness 평가
Conclusion
- Static World를 생성하는 과제에 대해서는 3D Model이 Video Generation Model보다 성능이 더 좋다.
- Open Source Model이 Closed Source Model보다 더 좋다.
- Video Model은 Longer Sequence/Larger World에 취약하다.
4. New Pre-training paradigms from a Inference-First Perspective

Video Diffusion Model에 관해서 지금까지 많은 발전이 있었지만, 그중 가장 대표적인 활용은 흔히 아는 Text와 Image를 동시에 처리하는 Task였다. 텍스트를 처리하는 방향은 거의 대부분 AR방식인데, 영상을 생성하는 과정도 AR방식처럼 Discrete Token으로 처리하는 방향은 어떨까? 예를 들어 VideoPoet와 같은 논문들이 있을 것이다.

다만, 여러 실험들을 통해서 Discrete Tokenization을 진행하는 것은 막대한 성능 저하를 일으킨다는 점이 발혀저 실제로는 Continuous Token들이 많이 쓰이고 있다. 이는 당연하게도 이산으로 처리하려면 더 많은 압축률이 필요하기 때문이다. Continuous Tokenization도 당연히 문제가 존재하는데 바로 속도와 관련된 문제이다. 이산적인 Token을 사용한다면 그냥 한번에 값이 생성될 수 있지만, 연속 token을 사용한다면 여러번의 Diffusion Step이 필수적으로 동반되기 때문이다.
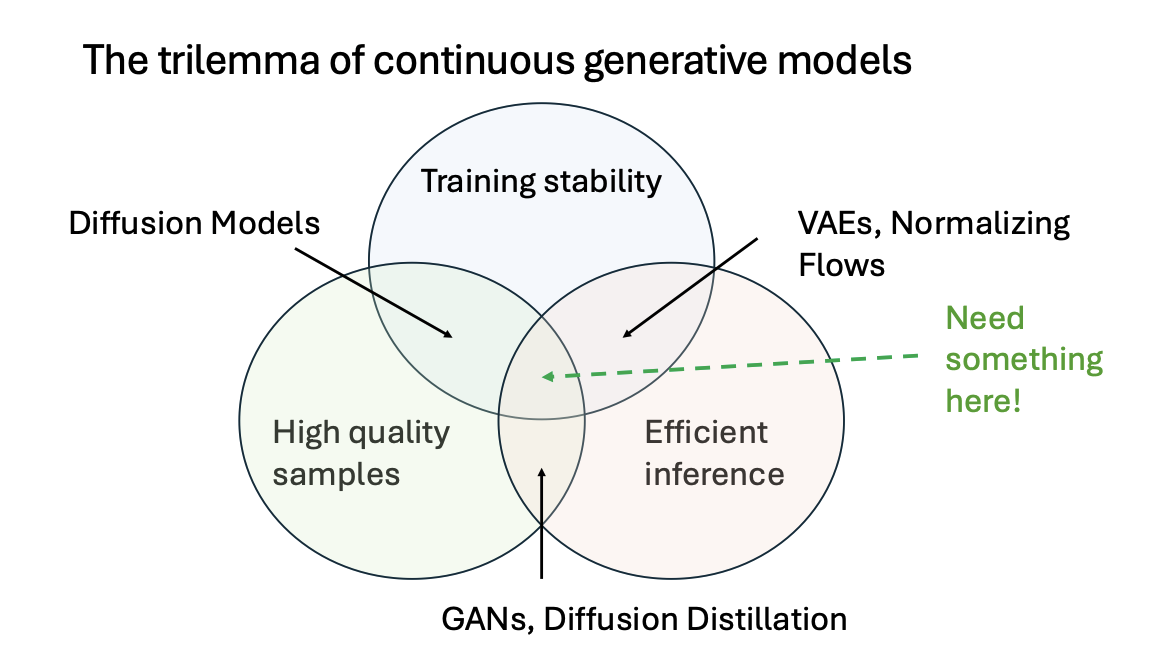
생성모델의 관점에서 봤을 때, 위와 같은 Trilemma가 존재한다. 과연 저 가운데 안에 있는 더 좋은 알고리즘이 무엇일까?
4.2 Two axes of inference scaling – sequence and refinement
Inference Scaling은 Token의 수를 늘리느냐 혹은 유지하느냐에 따라서 구분할 수 있다. 우리가 Token Sequence의 길이를 늘려서 성능을 올렸던 AR 방식 CoT-based Reasoning / RL 등이 사용될 수 있고, 반면 Token 수 자체는 유지하되, 동일한 토큰 길이를 여러번 정제하는 과정을 거치는 Diffusion / FM 계열 방법론들이 사용될 수 있을 것이다.
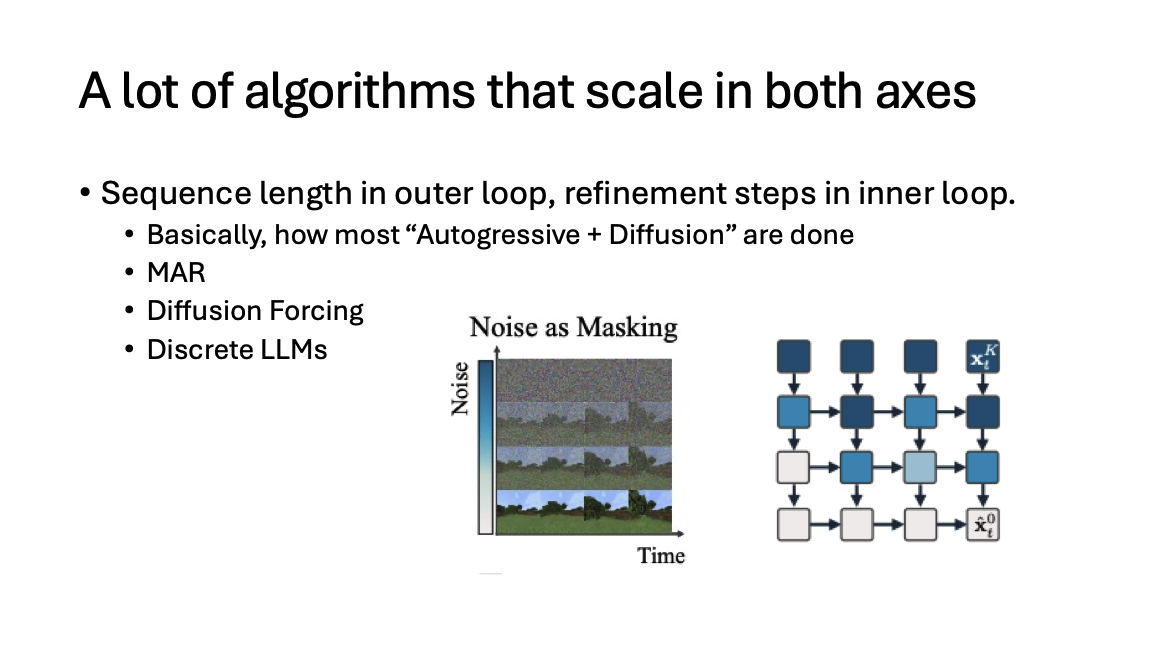
그렇다면 당연히 드는 생각이지만, Sequence를 늘리고, 정제하는 과정을 다시 한번 더 거치면 성능이 더 올라갈 것이다. 다만 가능한 것은 알지만 어떻게 효율적으로 달성할 것인가가 더 중요하다. 이 관점에서 본다면 아래와 같은 3가지 주장을 할 수 있다. 이를 continuous diffusion 관점에서 생각해보자.
-
The right inference algorithm should scale in both axes. Diffusion Model을 Refinement 축을 만족함 (O)
-
Assuming that the model has enough capacity (under universal approximation theorem), it should use as few steps as possible. Diffusion Model을 사용하더라도 한번에 완벽한 샘플을 생성할 수 없음(X)
-
Analyze the inference algorithm before the training algorithm!

기존의 방법이 현재 시점에서 방향 성분을 예측하여 s라는 미래 시점에 대한 값을 예측하는 문제로 바뀐 것이라는 시점으로 본다면 한 스탭에서는 꽤나 그럴듯한 결과를 보이지만 이것이 계속해서 중첩되다보면 굉장히 큰 오차가 발생할 것이다. 이를 해결하기 위한 방법으로 $u(\hat x_t ; s, t)$로 추가적인 $s$에 대한 정보를 제공하여 이 오차를 없애려는 방향도 존재한다.
IMM논문은 diffusion/flow처럼 local ODE update를 반복하는 대신, $\left(x_t, t, s\right)$를 조건으로 $q_t \rightarrow q_s$ 변환 자체를 학습하여 효율적인 few-step sampling을 가능하게 한다.
5. An Introduction to Kling and Our Research towards More Powerful Video Generation Models
Kling 회사에서 제안한 여러 Video Generation Model 기술 가운데 흥미로운 것들만 정리해보겠다.
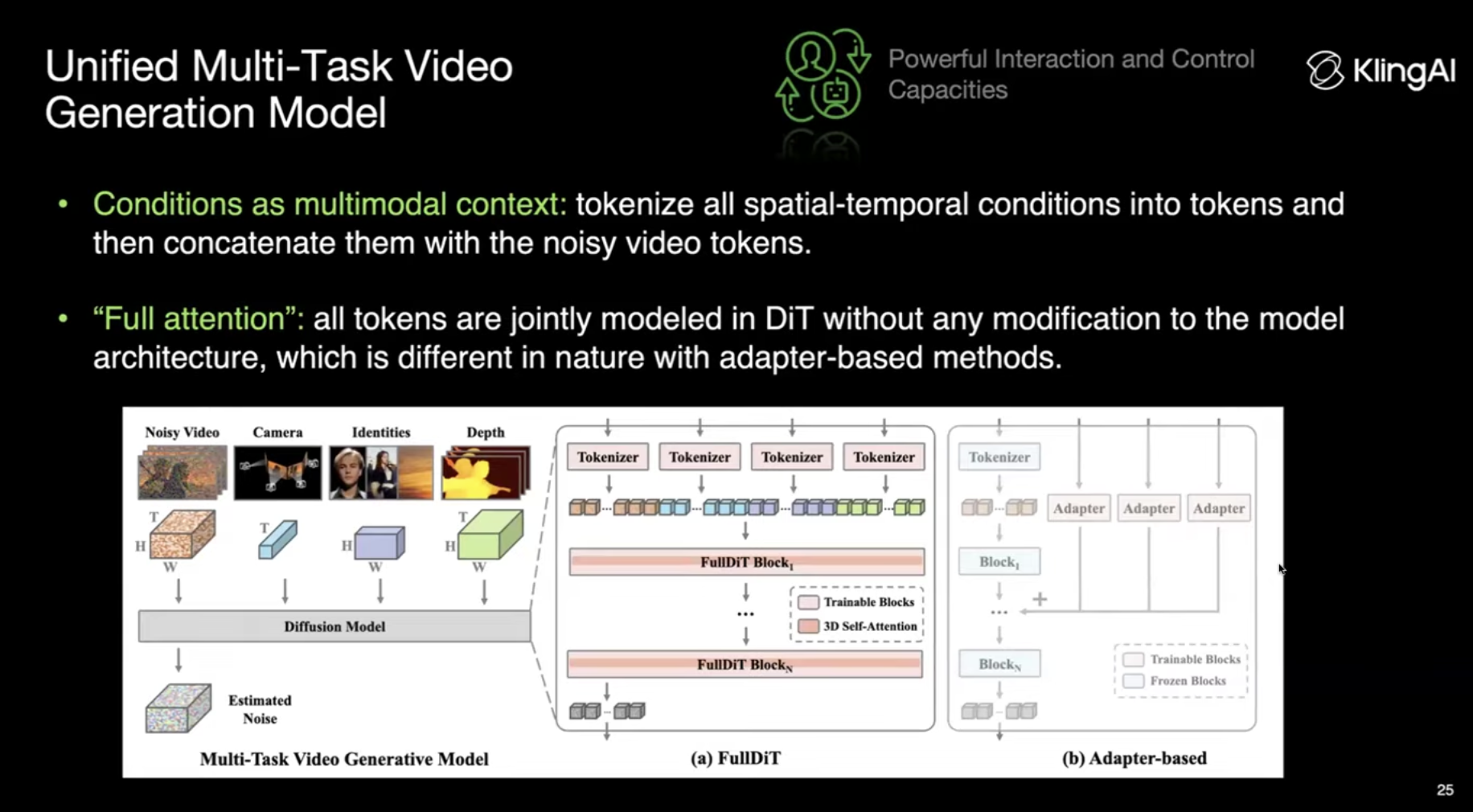
여러 Video generation Task가 존재하는데 각각의 Task에 대해서 서로 다른 모델을 생성하는 방식은 매우 비효율적이다. 이를 위해서 Unified Multi-Task Video Generation Model을 제안한다. Long-Context처리 방법이 많이 발달했기 때문에 Full Attention 방법으로 필요한 모든 Token들을 한번에 DiT Block에 집어넣는 방법을 제안한다. 이는 Condition을 AdaLN 방식으로 집어넣는 것과는 다른 맥락이다.
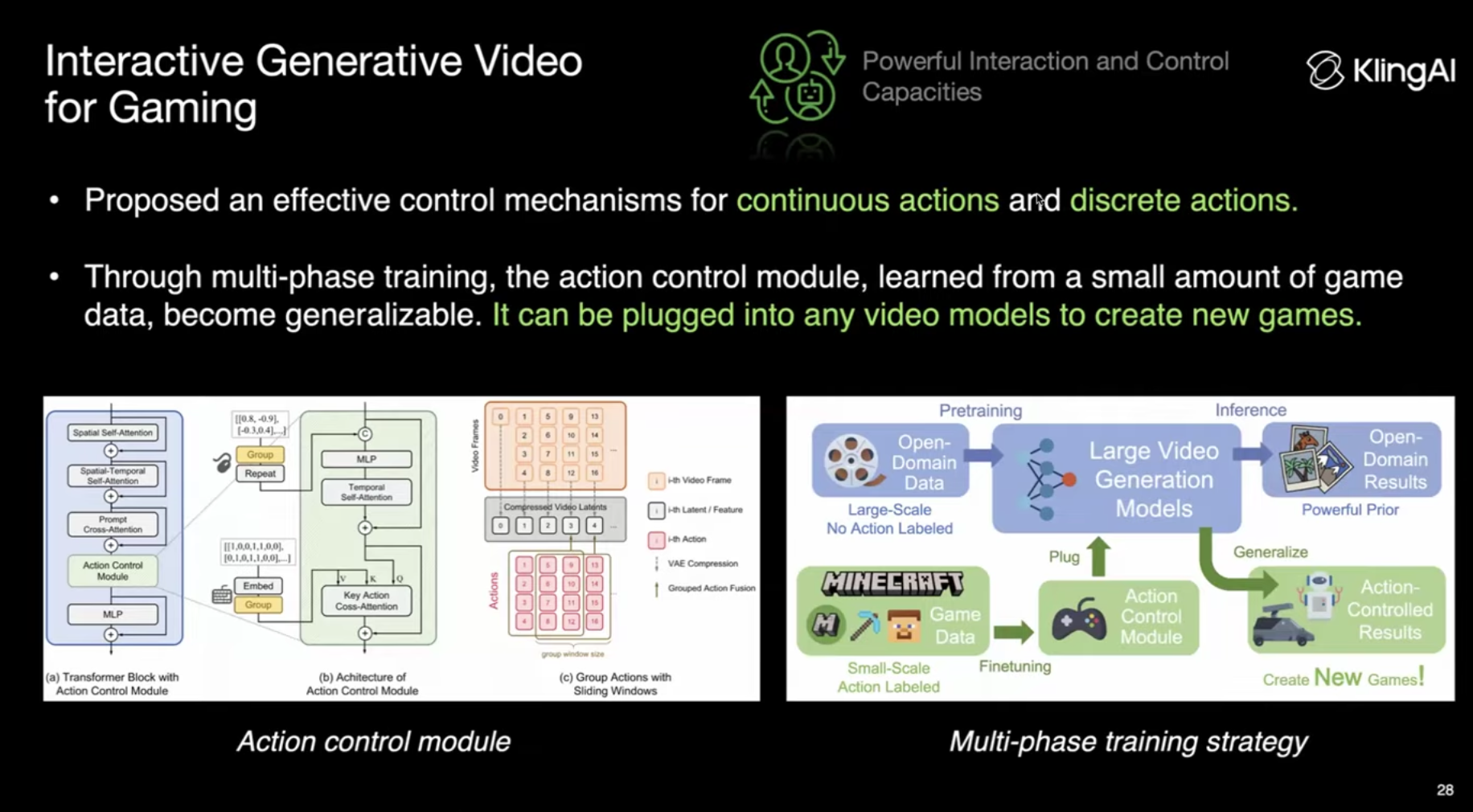
추가적으로 World Model 관점에서 Action 입력이 들어올 경우에 어떻게 처리할 것인지가 굉장히 중요한데, 이와 관련하여 Gaming을 위한 Interactive Video Generation을 다룬다. Genie와 비슷하게 Multi-phase Training을 통해서 Action Model을 학습하고 이것을 다양한 Video Model과 결합하여 사용할 수 있다.
또한, RLHF를 Video에 적용한 논문 Improving Video Generation With Human Feedback 또한 읽어볼만 할 것 같고 Flow-GRPO: Training Flow Matching Models via Online RL또한 Online RL을 사용하는 방식으로 읽어보아야 할 것 같다.
6. Streaming Perception : Towards Learning Structured Models of the World
4D World를 연구하는 목표는 현실 세계의 복잡한 구조를 비슷하게나마 이해할 수 있는 시스템을 만드는 것이다. 즉 물리 역학에서부터 사회적인 상호작용까지 세상의 인과적인 관계들을 이해하는 것을 목표로 한다. 이를 기존의 방법을 단순히 Scaling up해서 달성할 수 있을까? 이는 쉽지 않을 것이고 인간과 이를 비교해보자면 인간은 online으로 본인의 prior를 계속해서 수정하는 과정을 거칠 수 있다는 것이다. 다시 말해 새로운 Observation에 기초하여 연속적으로 본인의 추정치를 계속해서 Update하는 과정을 거치는 online data-driven model이 필요하다.
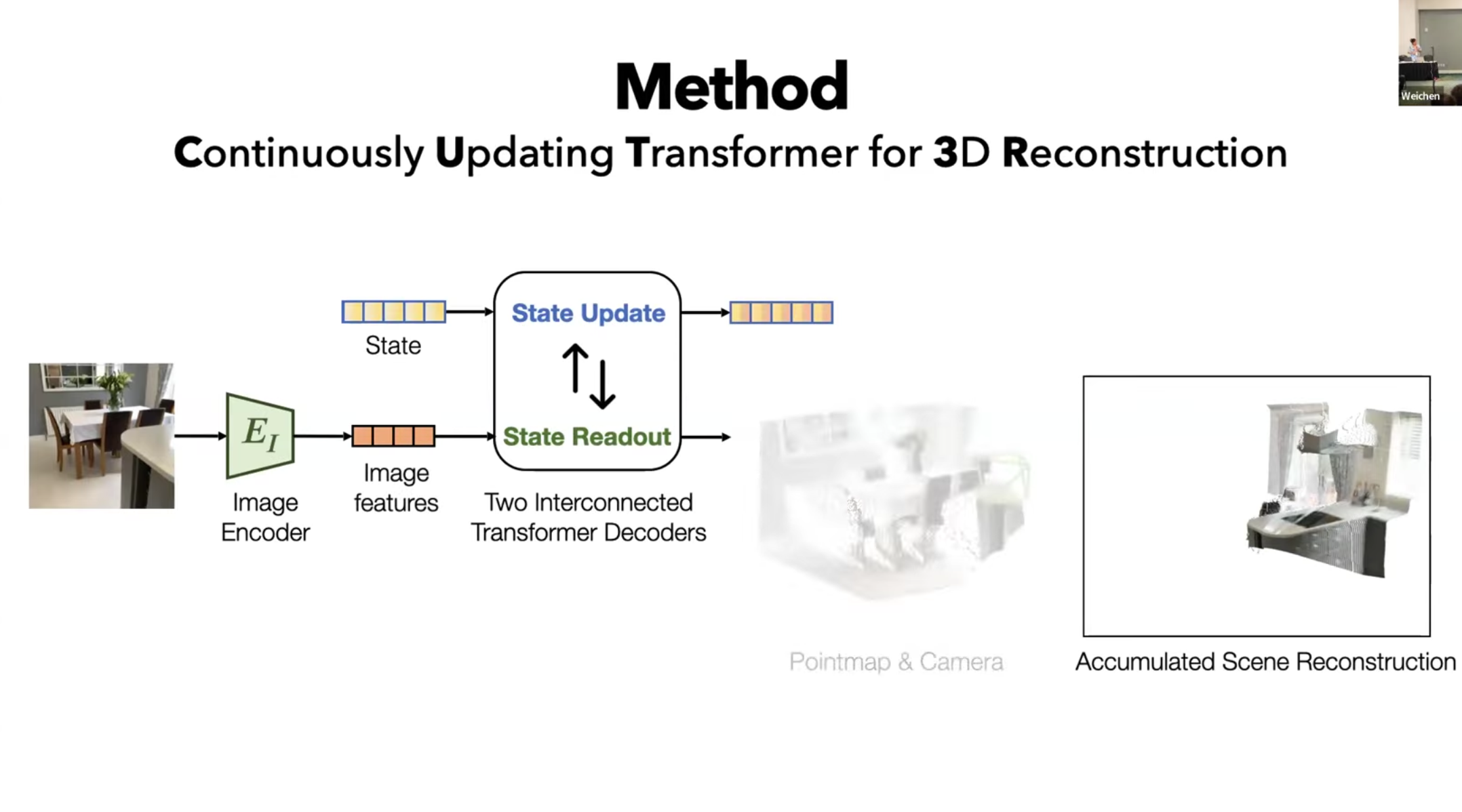
CUT3R 논문에서는 이 아이디어를 바탕으로 새로운 Image를 받아오면 State Update와 State Readout 방법을 적용하여 Scene Reconstruction 과정에 적용한다.
7. Scaling World Models for Agents
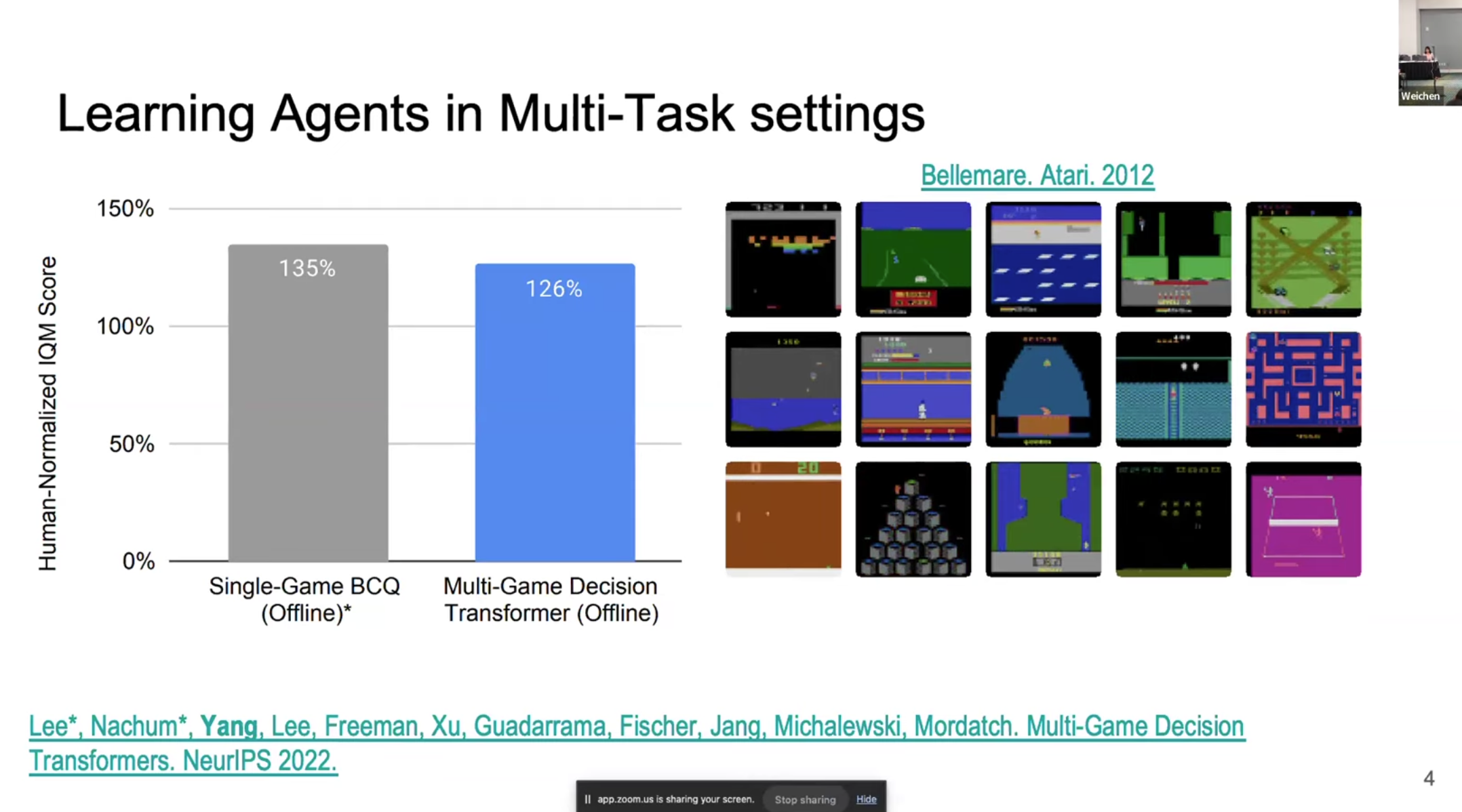
여러 Environment에서 잘 동작하는 Agent를 학습하기 위한 이전의 시도들이 존재했지만, Transformer Backbone을 사용했음에도 환경 다양성의 한계로 인해 단일 환경에 대해 학습한 단일 Agent에 비해 성능이 매우 좋지 않았었다.
7.1 Building World Models
사실 2018, 2020년에 제시된 world model과 현재 world model의 개념은 별반 다르지 않다.
\[o^{\prime} \sim \hat (o, a)\]위와 같은 간단한 수식으로 표현이 가능한데, 이전 Frame $o$와 Control Action $a$를 바탕으로 다음 Frame $o^{\prime}$을 생성하는 과정을 반복하는 것이다. 다만 이전과 달라진 점은 인터넷 상의 방대한 데이터를 바탕으로 Realistic World Simulator를 만들 수 있었고, Scalable Video Generation 아키텍쳐를 통해서 Single World Model이 여러 환경을 생성할 수 있게 되었다.
더 자세하게는 Video-Action Data를 사용할 수 있다는 점에서 많은 차이가 있는데, Text-Video, Camera Control - Video, Robot Control - Video, keyboard control - video 등의 다양한 데이터를 사용할 수 있다는 점이 큰 발전에 해당한다. 이 Action condition에 관해서도 어떻게 모델에게 줄 것인지에 대해 연구가 이루어졌는데, Text Embedding을 사용하는 것보다 원본 continuous vector를 사용하는 것이 효과가 좋았다고 한다.
7.2 Using World Models
7.2.1 Planning in a World Model
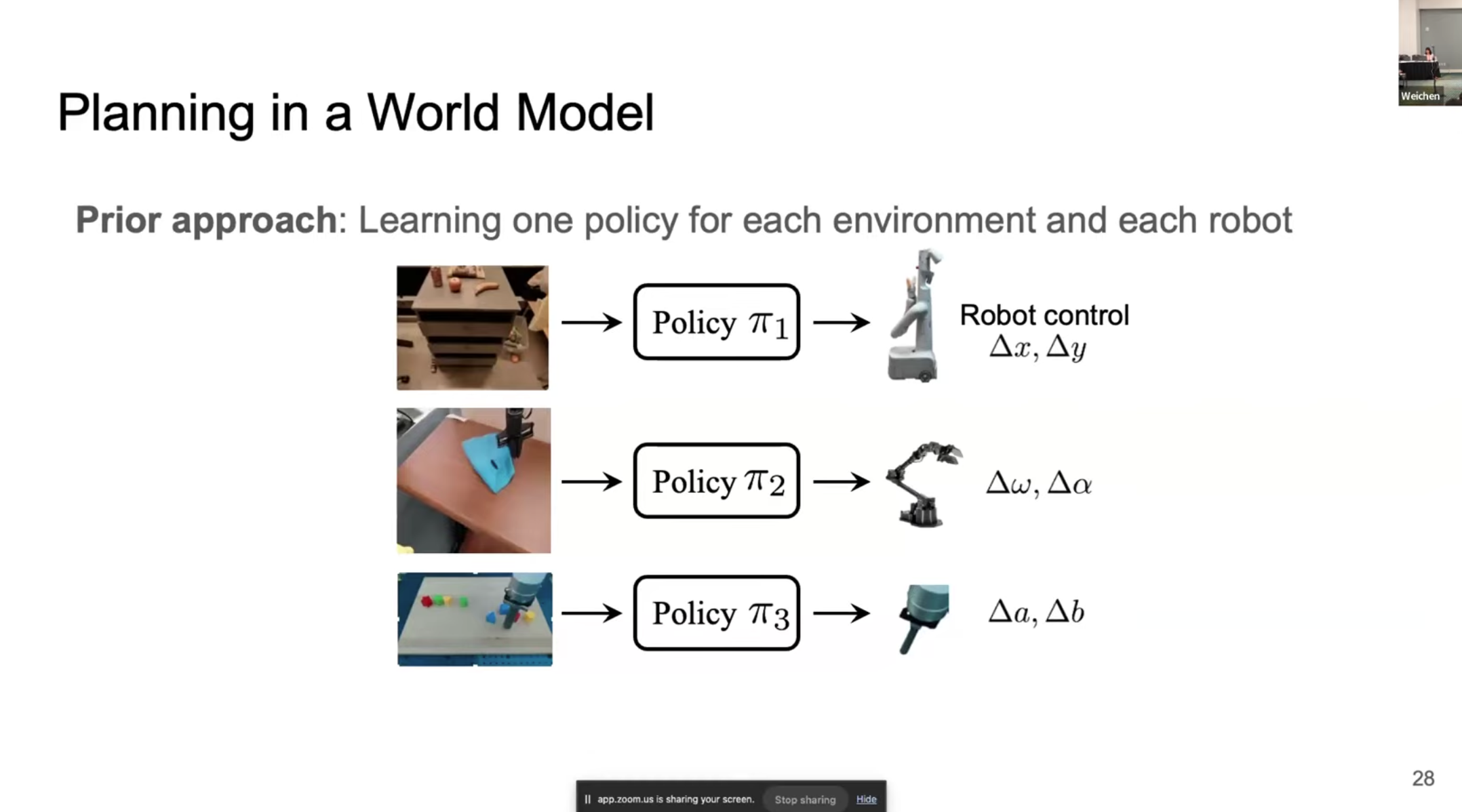
기존의 로봇만을 사용하는 방식의 한계점은 각 Environment에 대응하는 각각의 Policy를 사용하여 Robot을 조절해야 한다는 점이다. 로봇이 달라지거나 환경이 달라지면 동일한 policy $\pi$를 재사용할 수 없다는 문제점이 있다. 결국 Multi-environment을 처리할 수 있는 Policy를 사용하는 것이 필요하다.
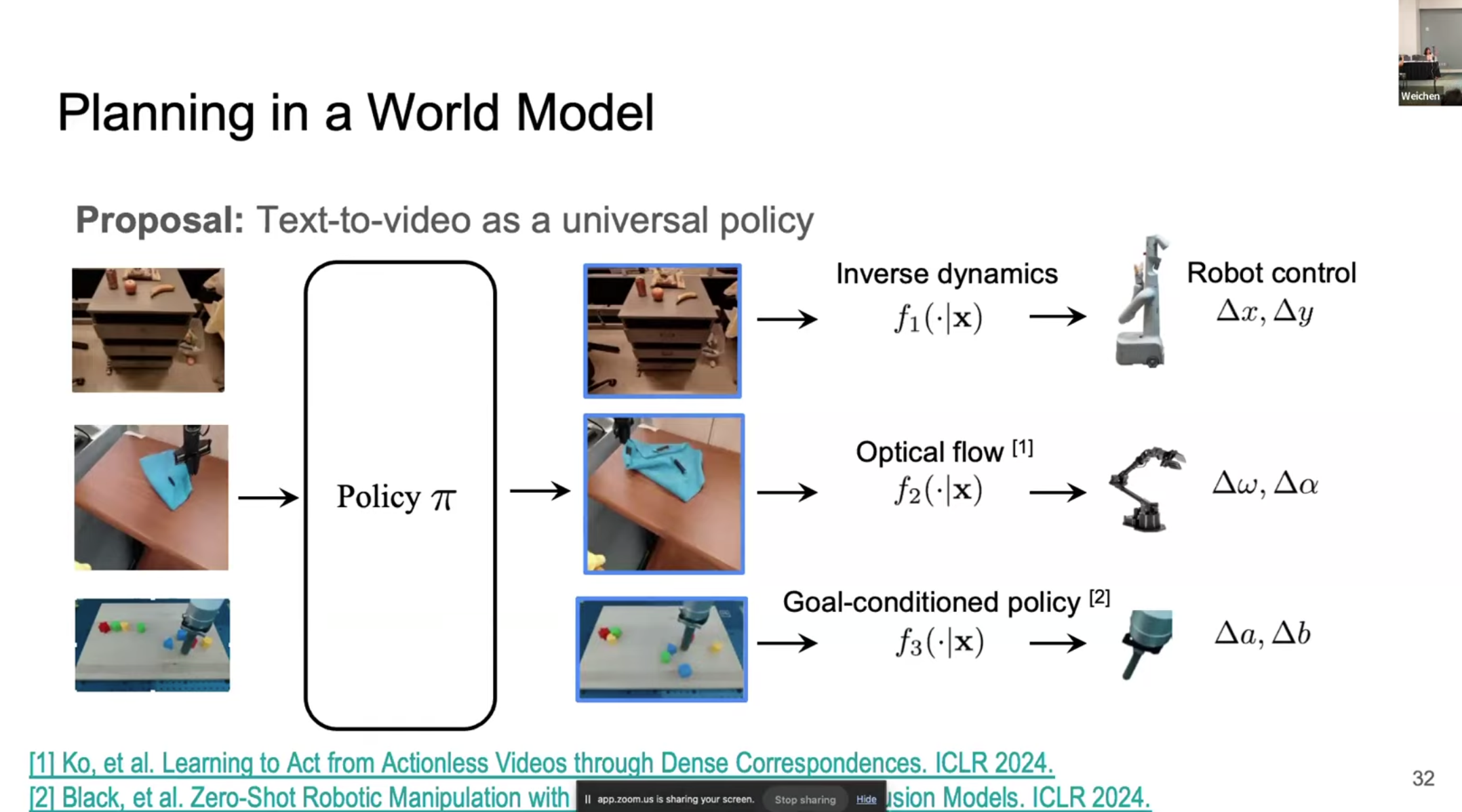
이것의 대안으로 World Model을 사용할 수 있다. 주어진 Text Action에 기반하여 영상을 생성하고, 이에 대응하는 dynamic을 생성하여 로봇을 조절하는 과정을 거친다는 것이다. 이렇게 되면 Universal Policy $\pi$를 사용할 수 있고, World Model을 활용한 Planning이 가능해진다.
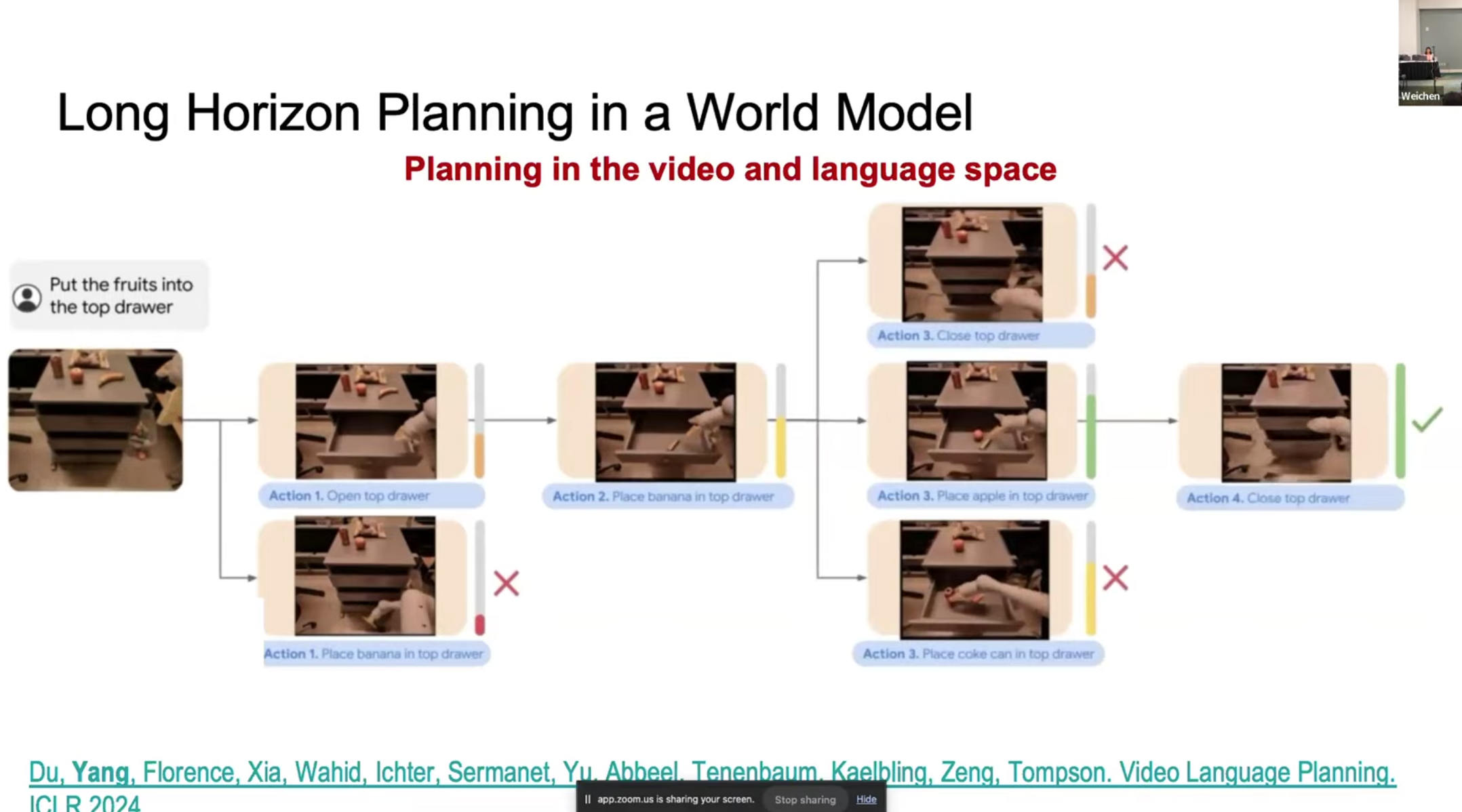
이의 또다른 장점은 굉장히 긴 지시문을 처리할 수 있는 파이프라인을 생성할 수 있다는 점이다. 실제로 로봇을 움직이지 않고 미리 여러 Beam을 사용하여 지시문을 처리하는 영샹을 만들고, 해당 영상의 정합성을 평가한 뒤, 이를 바탕으로 action을 생성하는 과정을 거친다. 따라서 World Model을 Multi Env를 처리할 수 있는 Policy로 활용이 가능하다.
7.2.2 Evaluating Policies in a World Model
그렇다면 7.2.1 과정을 통해서 World Model로 생성한 Policy를 어떻게 잘 평가할 수 있을까?
- Run on the Real Robot : 물리적인 실험 장비가 비싸고 한정됨.
- Run in Software simulator : 현실 세계와 Correlation이 굉장히 낮음.
앞에서 언급한 World Model Policy가 생성한 Action Sequence를 받아 Real World에서 동작시킨 것과 World Model 내에서 동작시킨 것의 차이를 보는 과정을 진행하면 World Model이 제대로 World Model Policy를 평가할 수 있는지를 확인할 수 있다.
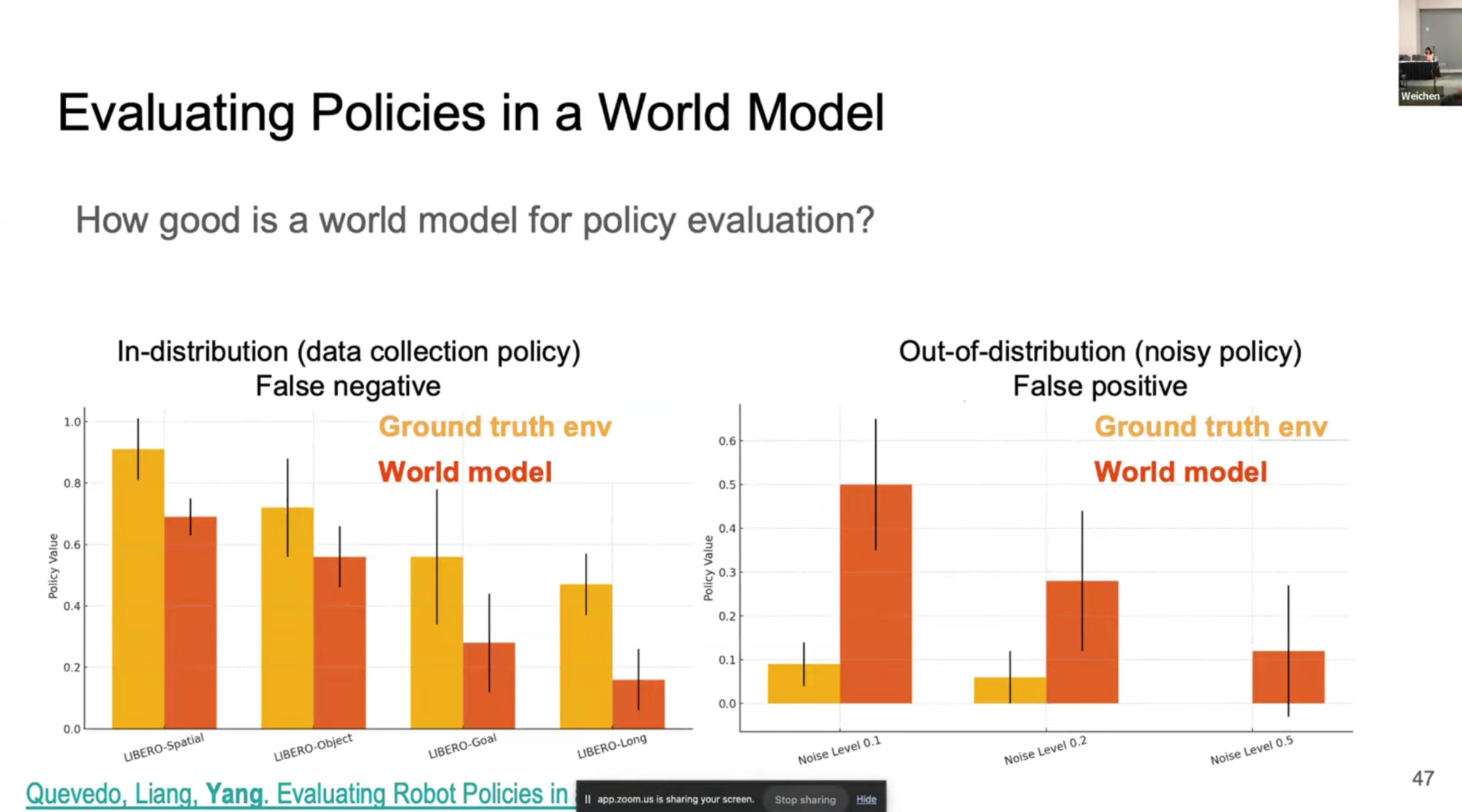
실제로 GT와 World Model을 비교한 결과 In distribution의 경우 Value를 과소평가하는 경향을 보였고 Out of Distribution의 경우 Value를 과대평가하는 경향성을 보였다. 따라서 WM을 사용한 정책 평가는 아직 완벽하지는 않다는 것을 확인할 수 있다.
7.2.3 Improve Policies in a World Model
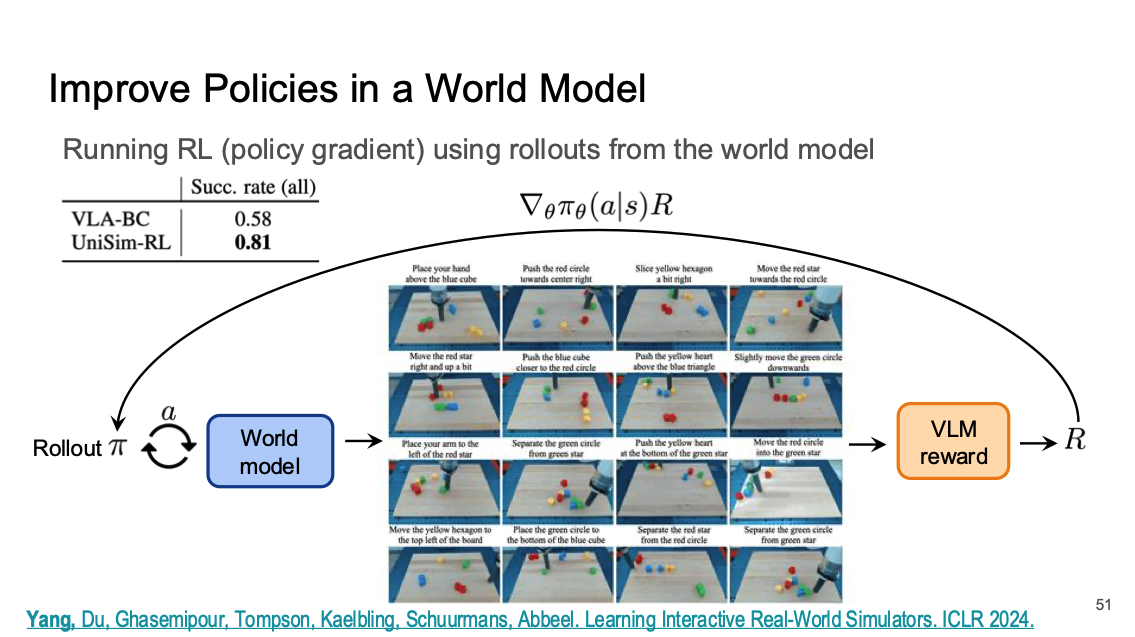
그렇다면 Policy Evaluation 과정 이후에 Policy를 Improve하는 과정을 진행할 수 있을까? 이전 RL 방식을 적용하여 우리는 쉽게 World Model이라는 Environment와 상호작용하며 정책을 평가하고 이를 바탕으로 수정하는 방식을 계속해서 반복할 수 있다. 즉 World Model에서 학습을 진행하고 Real World에서 Test를 진행했을 때 성능이 올라가는 것을 확인할 수 있다.
7.3 Improving world models
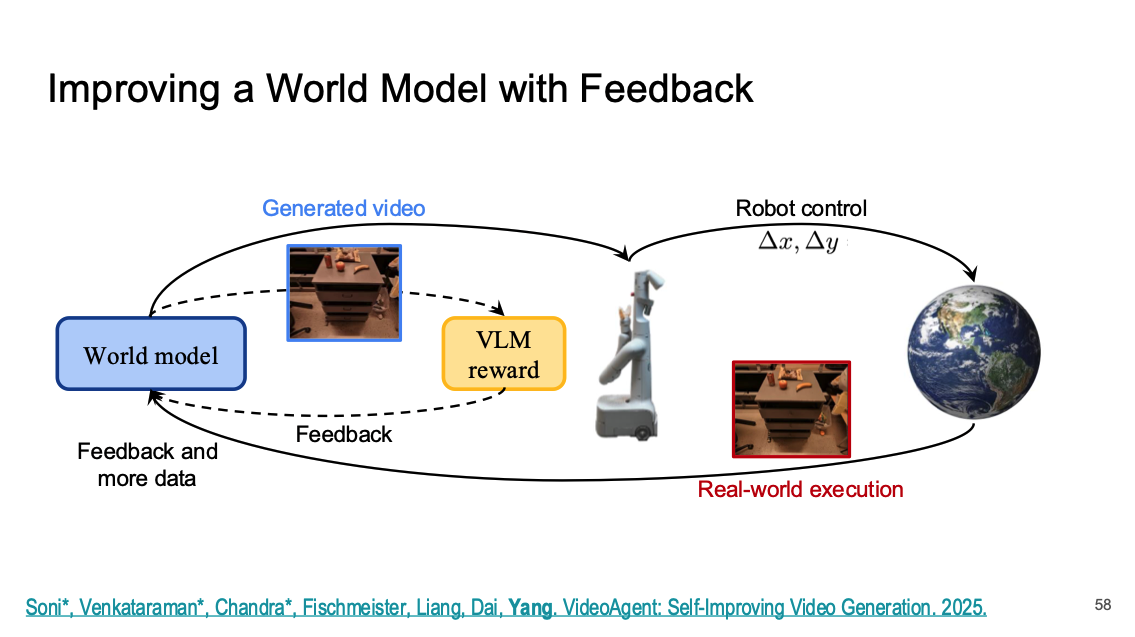
따라서 위에서 살펴본 WM Policy를 World Model과의 상호작용을 통해서 정책 업데이트를 진행하는 것 이외에도 World Model 자체에 대한 성능을 올려야 한다. 2가지 Feedback을 통해서 이를 진행할 수 있는데, 먼저 앞서 언급했던 GT Rollout과 WM Rollout 사이의 Feedback을 활용하여 WM을 업데이트하는 구조와 Policy를 통해서 실제로 동작시킨 결과를 바탕으로 World Model 자체를 향상시킬 수 있다.