
1. Abstract & Introduction
- LLM이 AGI로 가는 초석을 다진 만큼 학계나 산업계 전반에서 상당한 탄력을 받았다.
- 효율적인 자원 관리를 위해서
Multi-Tenant LLM Serving프레임워크가 등장했다. Multi-Tenant LLM Serving프레임워크는 여러 사용자의 입력을 동시에 처리해주는 것으로 SGLANG이나 vLLM과 같은 프레임워크가 이에 해당한다. 여러 사용자들 사이에서 동일한 Token Sequence가 발생햇을 때KV-Cache를 공유하는 방식으로 효율성을 높인다.
이 논문에서는 현재 사용되고 있는 KV Cache Sharing 메커니즘을 사용하는 경우 side channel attack vector가 생성되어 Prompt Reconstruction이라는 보안 위협이 발생한다고 주장한다.
저자들은 PromptPEEK 방법론을 제안하여 3가지 시나리오에서 다른 사용자의 Prompt를 복원하는 Reverse-Engineering 성능을 평가했다고 한다. 각 시나리오는 다른 사용자의 Prompt를 얼마나 알고 있는가를 바탕으로 단계 별로 평가를 진행한다.
LLM을 적용하는 분야가 날이 갈수록 많아지다보니, 동시간대의 요청을 효율적으로 처리하는 것이 중요해졌다. 사실 단일 LLM 요청은 그 자체로 매우 연산 복잡도가 크다. 추론 단계에서 다음 Token을 예측하기 위해서 계속해서 KV-Cache를 생성하는 과정을 거치기 때문이다. 추론이 길어짐에 따라서 KV Cache가 차지하는 메모리의 크기가 커지게 되고, 결국에 Gpu를 통해 한번에 처리할 수 있는 배치 사이즈가 줄어들어 동시간대의 요청을 처리하는 능력이 저하되게 된다.
해당 문데를 해결하기 위해서 vLLM이나 SGLang과 같은 방법론이 제안되어 KV-Cache를 효율적으로 공유하는 방식에 대해서 집중했다. (이는 자연스럽게 연산과 메모리 사용량을 줄일 수 있다.)
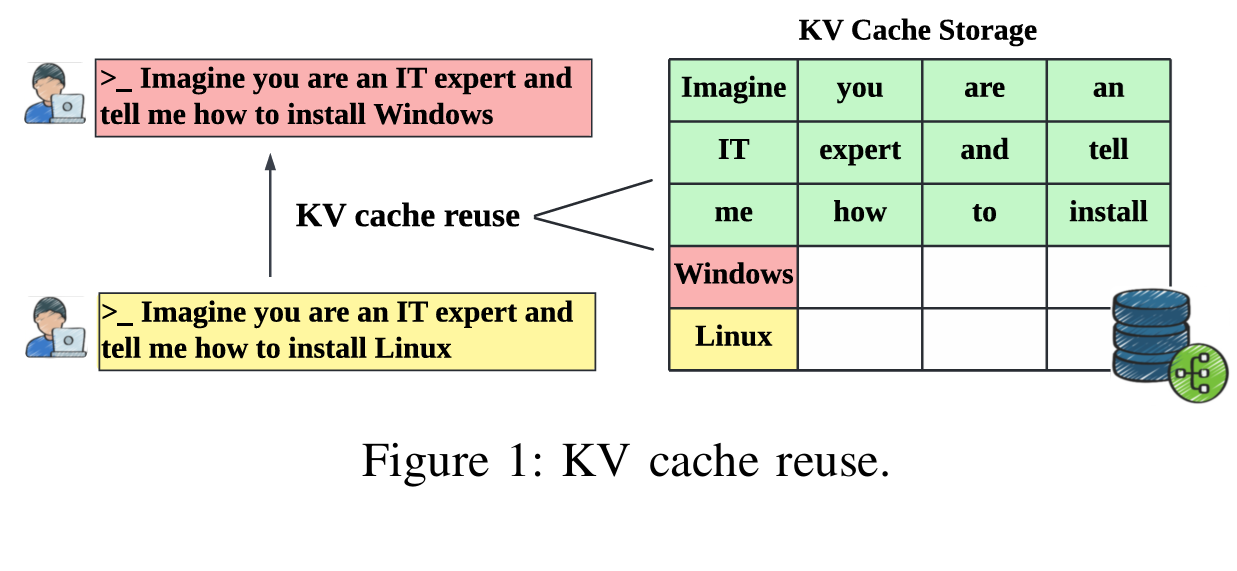
위 Figure를 통해서 쉽게 이해할 수 있다. Imagine you are and IT expert and tell me how to install Windows와 Imagine you are an IT expert and tell me how to install Linux 두가지 프롬프트는 매우 유사하며 마지막 Windows와 Linux토큰을 제외하고는 전부 동일한 KV 값을 가진다. 이 경우 겹치는 부분을 최대한 유지하고 겹치지 않는 부분부터 새롭게 생성하는 방식을 사용하는 것이 유리하다. 다만 이 논문에서 저자들은 이러한 KV Sharing 방식이 안전하지 않다는 점을 주장하며 Side Channel Information을 생성하여 사용자 프롬프트 복원에 사용될 수 있다고 한다.
이 논문에서 고안하는 PromptPEEK 방법론은 Serving Order가 바뀌는지 여부를 활용하여 Side Channel Information으로 활용한다고 한다. 이는 KV Cache의 Cache Hit 정보를 활용하여 한 번에 한 Token씩 복원하는 과정을 거치는 것이다. 해당 방법론의 평가를 위해 제안한 3가지 시나리오는 아래와 같다.
-
- Knowledge of the prompt template
-
- Knowledge of the prompt input
-
- No background Knowledge
실험 결과 prompt input을 일부 혹은 전체 복원하는 과정은 99% 성공률을 보였고 prompt template를 복원하는 것은 98%성공률, additional background없이 복원을 진행했을 때에는 95%의 성공률을 보인다고 한다. 저자들이 실험을 진행했을 때 성공에 영향을 미치는 요인은 Memory Capacity, Concurrent user’s requests, attack requests로 총 3가지이다. Memory Capacity는 공격의 실현 가능성을 보이고 User와 Attack Requests들은 메모리 고갈을 야기한다고 한다. 반면 공격자의 Background Knowledge는 Prompt를 복원하는 대에 사용하는 request의 수를 줄이는 효과가 있다고 한다.
2. LLM Serving
이 장에서는 LLM Serving에 관련된 내용을 설명한다. 특히 Multi-Tenant환경을 주로 다루는 것으로 보이는데, PagedAttention를 공부했다면 간단하게 이해가 된다. LLM Serving을 위해 다양한 framework가 제안되었고 vLLM, SGLang, LightLLM등등이 있다.
2.1 LLM Inference
LLM Serving의 핵심은 Multi-head Attention과 FFNN으로 이루어진 Transformer Block과 연관성이 높다. LLM은 Autoregressive Process로 초기 token을 바탕으로 계속해서 token을 생성하는 과정을 거치는데 이때 과거에 생성된 모든 token을 전부 사용하여 Decoding을 진행한다.
추론 과정에서 각각의 Token은 KV Cache를 생성하는데 이는 추후 Token decoding이나 Computational overhead를 줄이는 데에 큰 역할을 한다. 아래는 KV Cache의 특징들이다.
- 동일한 Token이라고 할지라도
How do you do?의 앞do와 뒷dotoken을 다른 KV cache를 가진다. 이는 동일한 토큰이라도 나오는 위치에 따라 다른 KV값을 가진다는 의미이다. - 반대로, 처음
<SOS>토큰에서부터 시작해 동일한 Token들이 생성된다면 해당 Sequence들은 동일한 Token값을 가지게 된다. - KV Cache는 LLM Serving에 심각한 bottleneck로 작용하며 Inference가 길어짐에 따라서 모델 자체의 크기보다 커질 수 있어, OS의 Memory Management와 비슷하게 Cpu mem이나 Disk에 저장하고 필요에 따라 다시 불러오는 과정을 거친다.
2.2 Mutl-tenant LLM Serving
Multi-tenant 시스템에서 KV Cache의 크기로 인해서 Batch를 줄일 수 밖에 없는 문제를 해결하기 위해서 여러 사용자의 요청 간에 KV Cache를 공유하는 방법이 제안되었다. 이 방식을 사용하여 자연스래 throughput과 serving time 모두 개선이 된다.

다만 위 Figure 2에서 확인할 수 있듯이, KV Cache가 공유되는 경우는 <SOS>토큰에서부터 시작하여 sequence가 완전히 동일한 경우만 가능하다. 다만 Automatic KV Cache sharing은 vLLM과 SGLang과 같은 state-of-art framework에 사용되어 왔다.
vLLM에서 사용하는 Cache Block은 Hash of previous tokens, last accessed time, reference count등의 정보를 담고 있으며 Gpu 메모리가 한계에 다다르면 Reference count가 0인 block 중 가장 오래된 KV block을 다른 곳에 저장하고 새로운 KV를 저장한다. vLLM은 새로운 요청이 들어오면 기존 Cache와 Hash 비교를 통해서 KV Cache를 재사용할지 결정한다.
3. Overview
Multi-tenant시스템이라고 하더라도 실제로 서빙 환경이 다르기 때문에 각 시나리오엣의 독특한 도전 과제들이 있을 것이다. 저자들은 논의를 위해 먼저 모든 시나리오에 대한 unified system model을 수립하고 threat model을 설명하고 저자들의 고안한 PromptPEEK에 대한 overview를 제공한다.
3.1 System Model
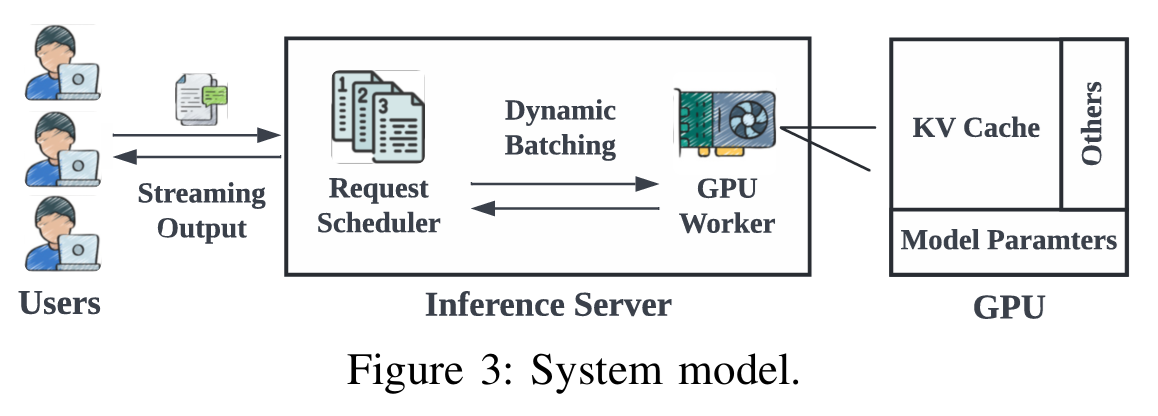
Figure 3는 이 논문에서 가정하는 Unified System Model에 대한 개요도를 보여주고 있다. User들은 개별적인 request를 보내고, Request Scheduler는 대기열 내의 요청을 배치로 집계하고 Gpu Worker에게 분배하여 추론을 진행한다. 이후 추론 결과를 다시 사용자에게 Streaming한다.
저자들이 고안한 모델은 세 객체로 구성된다. User, Scheduler, GPU Worker이다.
USER
$N$명의 사용자가 각각의 요청 $r$을 $f$주기로 LLM Service에 보낸다는 가정이다. $N$과 $f$는 설정에 따라 매우 많이 달라질 수 있다. 아래는 각 용어의 정의이다.
- $r = {t_1, t_2, … t_i}$ $i$는 Input prompt의 token 길이이다.
- 사용자는 ${t_{i+1}, t_{i+2}, … t_{i + j}}$의 Token sequence를 받으며 이때 $j$는 사용자 설정에 따라 달라질 수 있는데 output sequence의 길이이다.
Scheduler
스케줄러는 request들을 정렬하고, 처음 $m$개의 request ${r_1, r_2, …, r_m}$들을 $b$의 Batch size로 Gpu Worker에 할당한다. 추론 과정에서 KV cache를 관리하는 것 또한 스케줄러가 담당하며, 최종적인 output을 다시 사용자에게 보낸다.
- $P_S$: 사전에 정의된 Scheduling Policy로 request를 정렬하는 데에 사용한다.
- $P_B$: $m$개의 request를 batch size $b$로 처리하고 GPU에게 할당하는 Batching Policy이다.
- $P_{KV}$: KV Cache를 관리하는 Policy
- $P_O$: output을 적절한 사용자에게 반환하는 policy이다.
GPU Worker
Gpu는 내부 메모리로 load된 LLM을 사용하여 $b$개의 request를 한 번에 처리한다. 이 논문의 설정은 단일 Gpu에 단일 LLM을 Load하는 가정이다. GPU 메모리의 구성은 아래와 같다.
- $M_{Model}$: 모델 자체의 파라미터이므로 정적이다.
- $M_{others}$: Activation등의 부가적인 값을 저장하며 적은 memory를 사용한다.
- $M_{KV}$: GPU의 나머지 부분을 차지한다.
$M_{KV}$의 경우 요청이 진행되는 동안 각 요청이 필요로 하는 KV값을 끊어서 할당하는데, 각 Token의 크기를 $m_{t_{i}}$라고 가정한다면 최대 토큰 개수는 당연히 $T_{max} = \frac {M_{KV}}{m_{t_{i}}}$의 상한을 가지게 될 것이다. KV Cache를 사용한다면 GPU에 충분한 메모리가 남을 때까지 계속해서 보존되다가, 상한선에 다다르게 된다면 Eviction Policy $P_E$에 맞추어 KV Cache Eviction이 진행된다.
Policy Specification
1. Scheduling Policy $P_S$
$P_S$는 incoming request들을 어떻게 처리할 것인지를 다루는 정책인데, 저자들은 Longest Prefix Match를 사용했다고 한다. 이 정책은 이전에 입력된 KV Cache를 바탕으로 겹치는 Token Sequence Length를 가중치로 하여 정렬하는 정책이다.
2. Batching Policy $P_B$
$P_B$는 GPU Processing을 위해서 요청을 어떻게 묶는지를 결정하는 정책이다. 이 논문에서는 Continuous Batching 방법을 도입했다고 한다. 이는 GPU에 충분한 메모리가 있을 때 request batch를 올려서 추론을 진행한다고 하는데, 각 batch는 batch가 만들어질 때 free한 메모리마다 달라진다고 한다. Static Batching을 사용하면 전체 배치가 다 끝날 때까지 나머지 free 메모리가 낭비된다는 문제점이 있기 때문에 Continuous하게 사용한다.
또한 Batch는 max_num_seqs와 같은 값에 의해서 상한이 정해지기도 하고, Batch와 Latency를 둘 다 챙길 수 있는 Balance한 수치로 설정하는 것이 일반적이다.
3. KV Cache Policy $P_{KV}$
KV Cache 정책은 SGLang의 KV Cache sharing mechanism을 따른다고 한다. 이전에 읽은 PagedAttention 논문에서는 디테일하게 작성되어 있지 않았는데, SGLang 논문에서는 자세하게 기술되어 있다고 한다. 이때 KV Cache를 저장하기 위해서 Radix Tree를 사용한다.
SGLang 논문 또한 읽어볼 계획이다.
4. Output Policy $P_O$
$P_O$는 결과를 어떻게 사용자에게 반환하는지에 대한 정책이다. OPENAI 회사에서 사용하는 것과 동일한 방침으로 사용자에게 실시간으로 생성된 token을 전송하는 방식을 사용한다.
5. Eviction Policy $P_E$
$P_E$는 GPU가 전부 사용되었을 때 어떤 KV Cache 값을 다른 저장소로 옮길 지를 결정하는 정책인데, 이는 LRU 방식을 사용한다. 현재 참조되지 않는 KV 중에서 사용된 지 가장 오래된 KV를 Evict하는 정책이다.
3.2 Threat Model
공격자의 목표는 side channel information을 사용하여 다른 사람이 보낸 prompt를 복원하는 것이다. 이 논문은 다양한 시나리오에서 실험을 진행했으며 각 시나리오마다 target이 되는 것을 다르게 설정했다고 한다.
적대자는 일반 사용자와 동일하게 inference server에 대한 직접적인 권한이 없다는 가정이고, 공격자가 LLM Server의 내부 매커니즘을 알고 있다는 가정이다. 여기에서 내부 매커니즘이란 $P_S$. $P_E$ 등등의 정책이다. 추가적으로 LLM에 대한 배경 지식은 Tokenizer 정보를 알고 있다는 것에만 국한되는데 이 정보는 close source 모델이어도 Tokenizer는 공개하기 때문에 사용할 수 있다.
3.3 Attack Overview
이 논문에서 제안하는 PromptPEEK 방법론은 하나의 tenent request의 상태가 다른 요청에 의해 영향을 받을 수 있기 때문에 의도치 않게 cross-tenant side channel을 생성할 수 있다는 것이다.
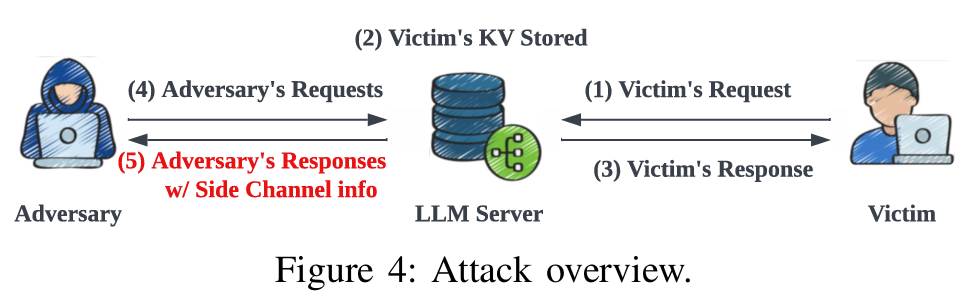 먼저 Victim의 request가 전송되고 KV cache가 연산되어 유지된다. 이후에 공격자가 제작한 요청들을 LLM Server에 전송한다. 응답을 통해 생성된 side channel 정보를 활용하여 공격자는 자신의 prompt가 Victim의 Prompt를 통해 생성한 KV Cache를 재사용했는지를 알 수 있다. 즉 Victim의 초기 토큰에서부터 시작하는 연속적인 토큰 시퀀스를 공유하는지 여부를 알 수 있다는 의미이다. 이 과정을 통해서 그들의 input token이 victim과 match되는지를 확인할 수 있어 Prompt 재구성이 가능해진다.
먼저 Victim의 request가 전송되고 KV cache가 연산되어 유지된다. 이후에 공격자가 제작한 요청들을 LLM Server에 전송한다. 응답을 통해 생성된 side channel 정보를 활용하여 공격자는 자신의 prompt가 Victim의 Prompt를 통해 생성한 KV Cache를 재사용했는지를 알 수 있다. 즉 Victim의 초기 토큰에서부터 시작하는 연속적인 토큰 시퀀스를 공유하는지 여부를 알 수 있다는 의미이다. 이 과정을 통해서 그들의 input token이 victim과 match되는지를 확인할 수 있어 Prompt 재구성이 가능해진다.
4. PromptPEEK
PromptPEEK의 아이디어는 두 단계로 설명할 수 있다. Token Extraction과 Prompt Reconstruction이 이것에 해당한다.
4.1 Token Extraction
Token Extraction과정은 Attack primtive로 볼 수 있다. 이는 Candidates Generation phase와 Token Selection phase로 나눌 수 있다. Candidates Generation phase에서는 다음 token의 후보를 생성하고 Token Selection에서는 side channel information을 활용하여 해당 토큰이 실제 target token인지를 판단한다.
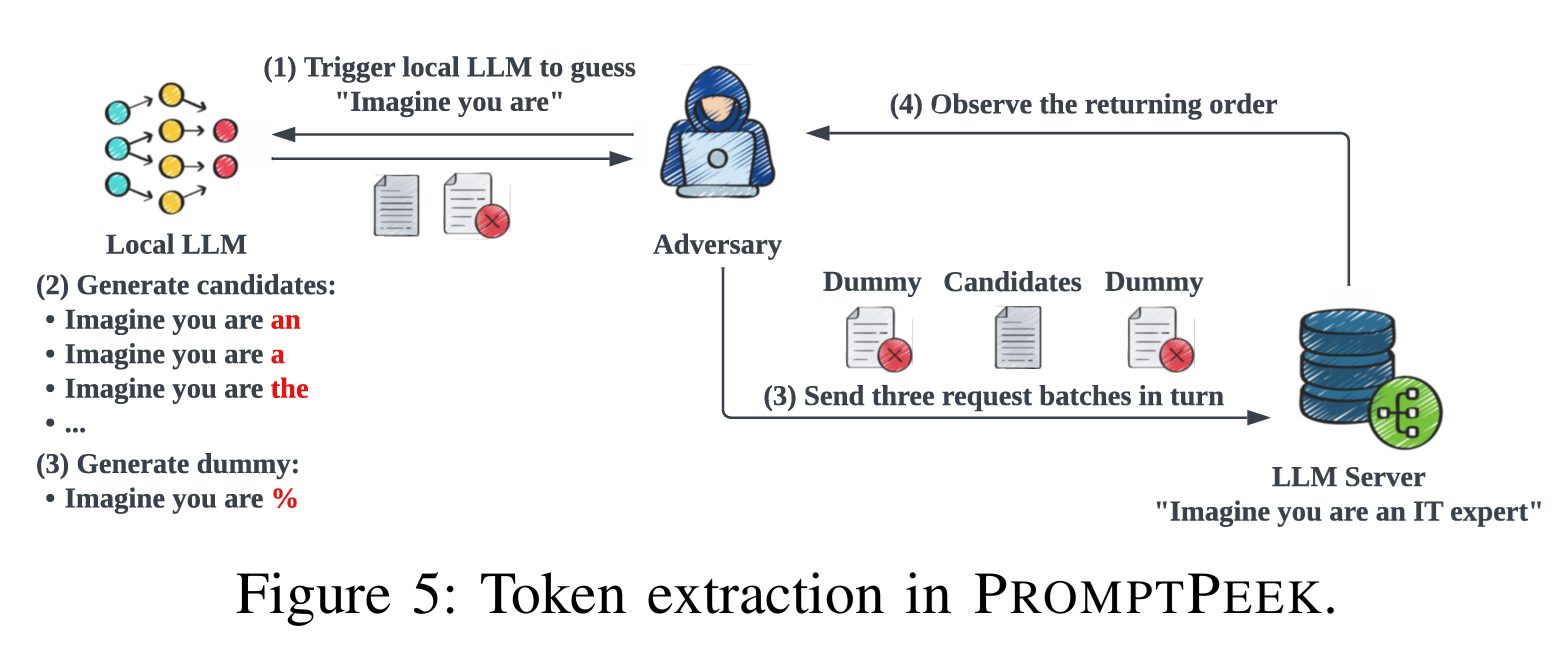
논문에서는 Imagine you are an IT expert,라는 prompt를 복원하는 과정을 예시로 들고 있다. Figure 5은 Imagine you are까지는 복원이 완료되었고 an이라는 token을 복원하는 과정을 예를 들어 설명하고 있다.
4.1.1 Candidate Generation
저자들은 후보 토큰을 생성하기 위해서 JailBreaking Attack에서 주로 사용하는 방식을 차용했다. 이는 LLM을 학습해 LLM을 공격하는 방법인데, 이전까지의 추론 결과를 바탕으로 Local LLM을 활용하여 후보가 될만한 토큰들을 $k$개 생성한다. Figure 5의 가정에서는 an, a, the등의 토큰이 이 후보가 될 것이다.
이 Local LLM이라는 것은 공격 대상 LLM과 동일한 tokenizer를 사용하는 LLM이어야 한다. 다른 Tokenizer를 사용한다면 같은 문자열이라도 다른 토큰이 생성될 것이기 때문에 동일한 것을 사용한다는 가정은 지켜야 한다.
이 과정에서 추가로 생성하는 것이 하나 더 있는데, dummy token이라고 다음 token이 될 가능성이 매우 낮은 토큰을 하나 생성하는 것이다. 이 예시에서는 %이 해당한다. 해당 token은 side channel information을 생성하는 데에만 사용한다.
4.1.2 Token Selection
이 과정은 dummy request과 candidate request을 전략적으로 보내 return order를 수집하고 이를 사용하여 후보 토큰들 중에서 단 하나라도 맞는 것이 존재하는지를 파악하는 단계이다. PromptPEEK 방법은 $P_S$의 LPM 정책을 활용한다. Victim의 KV cache과 겹치는 token이 가장 많은 순서대로 priority를 부여하는 정책은 만약 성공적으로 매치된 후보가 존재한다면, 나머지들보다 먼저 처리될 것이다라는 전략을 사용할 수 있게 해준다.
Candidates sending strategy
단순하게 모든 후보 request를 동시에 전송하고 return order를 파악하는 것은 먼저 나온 reqest가 우연히 일찍 도착한 것인지, LPM에 의해 의도적으로 순서가 바뀐 것인지 모르기 때문에 정확한 판단이 불가능하다.
따라서 저자들은 Figure 5에 작성한 것처럼 dummy candidate dummy 순서로 request를 전송한다. pre-candidate dummy는 대기열을 가득 채워 후보들이 반드시 대기열에서 LPM 정책으로 정렬되도록 하고 post-candidiate dummy는 정렬 효과를 증폭해 실제로 순서가 바뀐 것인지를 확실하게 구별 가능하도록 해준다. 이때 output token length는 항상 1로 고정시켜두는데, GPU 메모리를 낭비하는 것을 방지해 공격을 성공시킬 수 있도록 하는 것이다.
Side Channel Information

Figure 6을 통해 더 확실하게 이해할 수 있다. 이전에 언급한 것과 같이 현재 실행 중인 batch를 dummy request들로 채워넣고, 나머지 requests들이 queue에서 LPM 정책을 따를 수 있도록 한다. 이 과정을 거치면 Imagine you are %이라는 Dummy 문장과 Imagine you are an IT expert라는 victim의 문장이 KV Cache에 저장되어 있을 것이다.
이후에 대기 queue에 저장된 requests들을 LPM 정책을 따라서 KV Cache과 겹치는 token이 많은 순서대로 requests들을 정렬하게 된다. 이 예시에서는 dummy requests와 target request는 4개의 token이 겹치고, 나머지 requests는 3개의 token만이 겹치게 되어 결과적으로 dummy requests들 사이에 matched request가 분포하게 된다.
결론적으로 만약 Match가 되었다면, pre dummy - target - post dummy - rest의 순서가 될 것이고, 실패했다면 pre dummy - post dummy - candidate와 같은 순서가 된다.
Request batch size
한 번에 시도할 배치 크기에 관하여 어떤 문제는 적은 $k$ 값으로도 예측이 가능한 반면, 굉장히 큰 값도 필요한 경우가 존재하기 때문에 무조건 batch size를 늘리는 것은 낭비가 될 수 있고 너무 작게 하는 것은 시간의 낭비가 될 수 있다.
다만 pre-candidate와 post-candidate dummy requests들의 경우 모두 LLM Server의 최대 배치 크기보다 커야 한다. pre-candidate의 경우, 현재 진행중인 배치를 모두 채워야 하기 때문에 더 커야하고, post-candidate의 경우 매칭되지 않은 후보들이 post-candidate와 같은 배치에서 처리되지 않아 정보가 혼동되지 않아야 하기 때문이다.
4.2 Prompt Reconstruction
4.1에서 다룬 Token Extraction 방법을 사용하면 공격자는 점진적으로 프롬프트를 재구성할 수 있지만, 언제 재구성을 멈추어야 하는지는 알 수 없다. Prompt Reconstruction 단계에서는 언제 재구성을 멈추어야 하는지를 최적화 전략과 함께 소개한다.
4.2.1 Prompt Switching
공격자는 진행하던 재구성을 멈추고 다른 프롬프트를 시도해야 하는 경우가 있는데, 바로 Target Prompt가 GPU에서 Evict되는 경우이다. 이 경우는 단순하게 gpu에 존재하지 않기 때문에 당연히 추적이 불가능하고, 따라서 재구성을 멈추어야 한다.
이는 과거에 실패했던 후보를 한번 더 보내보는 것을 통해 확인할 수 있다. Imagine you are an IT Expert라는 문장 중에서 Imagine you are까지는 복원이 완료되었고 an이라는 토큰을 복원하는 과정에서 이전 단계에 Imagine you were이 후보에 있었고 이것이 실패했다면 Cache에 해당 내용이 존재할 것이기 때문에 Imagine you %를 앞 뒤로 감싸 Imagine you were을 다시 시도한다면 샌드위치 구조가 나와야 한다. 만약 이것이 깨지면 해당 프롬프트가 flush되었다고 판단할 수 있는 것이고, 다른 prompt를 시도해야 한다는 것이다. 이 체크 과정은 매 round나 몇 개의 round마다 시도한다.
4.2.2 Optimization
공격을 성공적으로 수행하려면 targe KV값이 최대한 flush되지 않아야 한다. 이를 위해서는 GPU에 남은 메모리가 많아야 하기 때문에 의도적으로 eviction을 일으켜 GPU를 한번 초기화 해준다.
즉, non identical dummy request를 대량으로 보내 gpu를 포화 상태로 만들고 prompt switching에서 사용했던 기술처럼 주기적으로 dummy가 flush되었는지 확인해 해당 최적화 과정이 종료되어야 하는 시점을 정한다. Cache가 flush된 것이 확인되면 $t$ 시간 동안의 대기를 거친다. $N \times f \times t$ 정도의 새 프롬프트가 쌓이게 될 것이고 이를 바탕으로 다시 복원 가정을 거친다. 이후 정상 요청과 공격자의 요청이 함께 처리되고 GPU를 사용하다가 target prompt가 flush된다면 종료하는 과정을 반복한다. 이는 SGLang 방법을 사용하여 KV cache를 관리하기 때문에 가능한 것으로 현재 배치가 쓰는 KV Cache만 남기고 나머지 Ref count가 0인 KV들은 Evict한다. 따라서 이 방법이 효율성을 극대화할 수 있다.
5. Attack Scenarios
5.1 Whole Prompt Reconstruction
이 가정은 victim의 prompt에 대한 아무런 사전 정보가 없는 설정이고 대부분의 공격이 이 경우에 해당한다. 이 경우 3번에서 설명한 threat model과 4번에서 설명한 공격 기법을 사용하여 한 토큰씩 재구성을 진행한다.
5.2 Input Reconstruction
이 시나리오는 공격자가 victim의 prompt template를 알고 있다는 가정이다. 이 Template는 사용자 간에 공유되는데 답변을 더 잘 받기 위해서 이런 프롬프트를 사용해라 라는 것이 Template에 해당한다.
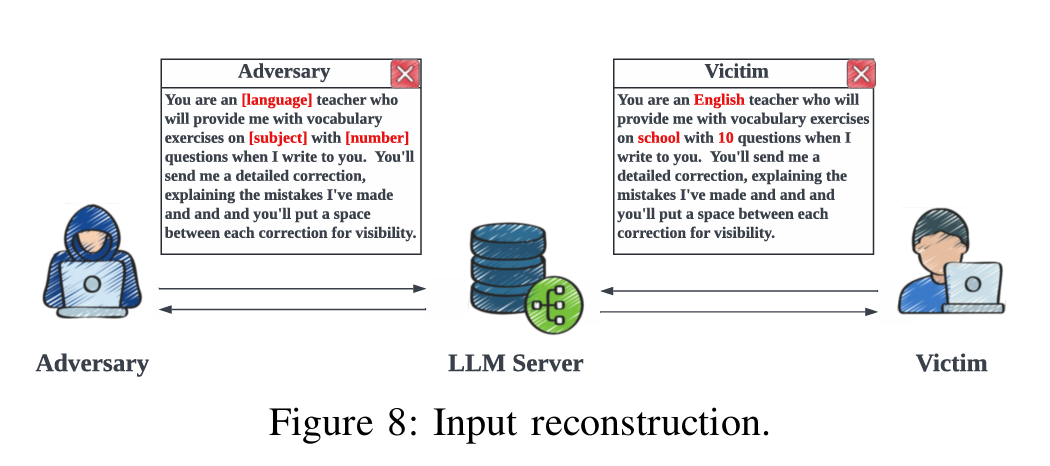
위 사진과 같이 [language]나 [subject]와 같은 placeholder들 사이에는 victim의 민감한 정보 토큰이 담겨있기 때문에 이를 복원하는 과정을 거친다.
- Cloze-style prompt: 중간에 placeholder를 통해서 문장 구조를 유지시키는 구조, 해당 자리에 민감한 개인정보를 넣어 제출할 수 있다.
- Prefix-style prompt: 이런 prompt들은 사용자 정답의 방향을 정해준다.
Specific role을 부여하는 role-based prompt와 명령을 제공하는 Instruction-based prompt가 이에 해당한다.
Threat model: 3번에서 제안한 모델에서 이 경우 전체 prompt를 복원하는 것이 아니라 민감한 Input reconstruction만을 진행한다.
Methodology
- Cloze-Style Prompt
Local LLM에게 프롬프트를 주고 placeholder에 해당하는 detailed input을 예측하라는 과정을 거쳐서 후보 토큰을 생성한다.
“Give you a template: ‘cloze-template’. Sequentially guess the detailed input:”의 템플릿을 사용한다. - Prefix-Style Prompt
Role-based prompt의 경우
“Here’s a template for your role: role-based template, based on your role, guess what I will give you:”의 방식을, Instruction-based prompt의 경우“Below is an instruction that describes the task, please infer the most likely paired inputs:”의 탬플릿을 적용하여 Local LLM의 후보 토큰을 생성한다.
5.3 Template Reconstruction
이 시나리오에서는 Input이 알려져 있지만 Tempate은 알 수 없는 경우에 해당한다.
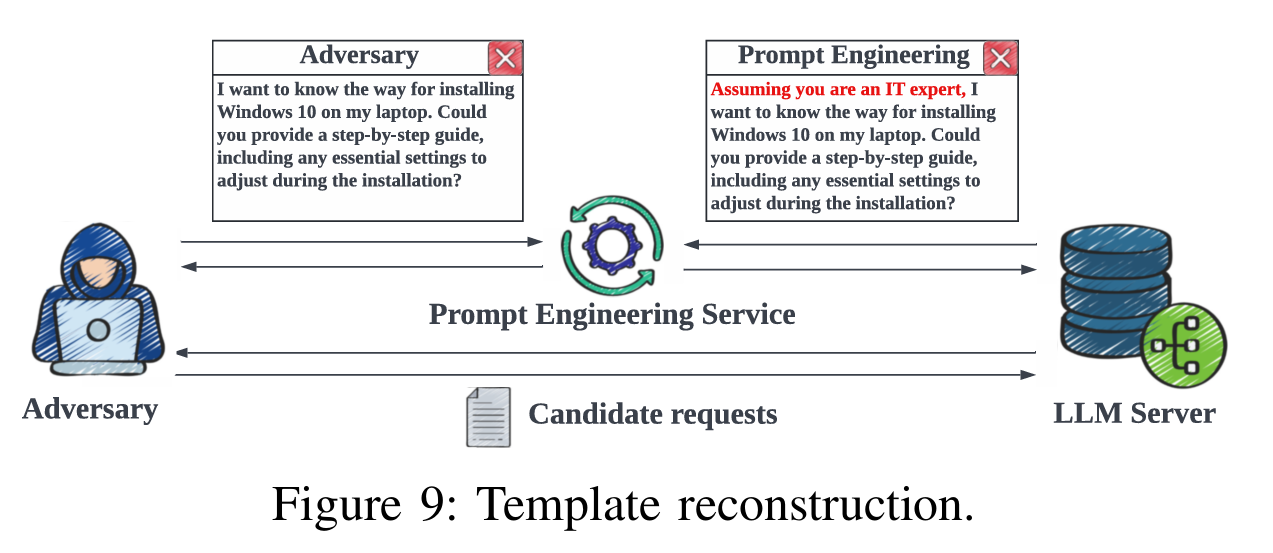
이 방식은 사용자가 입력한 내용은 완전히 알고 있지만, 서비스가 백엔드에서 자동으로 붙여넣는 프롬프트 템플릿은 모른다는 가정에서 숨겨진 템플릿 자체를 복원하는 것이 목표이다.
Threath model: 1과 2번 시나리오와 달리 공격 대상이 일반 사용자의 프롬프트가 아니라 prompt engineering service가 사용하는 템플릿이 된다.
Methodology 시나리오 2번과 비슷하게 cloze style 과 prefix-style 프롬프트를 고려하며 prompt engineering을 활용하여 후보 토큰을 생성하고 차례로 프롬프트 template를 복원한다.
Insturction Based:“Below are a pair of input and out corresponding to an instruction which describes the task: Please inferring the instruction:”
role-based: “Here’s the input and output based on your role: Guess the prompt that defines your role:”
Cloze-style: “Here’s the input and output: Guess the prompt:”