
Lumiere: A Space-Time Diffusion Model for Video Generation
Abstract
기존의 Video Model이 Keyframe을 바탕으로 Temporal Super-resolution을 진행하지만, 해당 과정에서 global temporal consistency가 깨지는 문제가 발생한다. 따라서 저자들은 full frame rate, low resolution video에서 출발하여 Spatial Super-resolution을 진행하는 방법을 새롭게 고안한다.
1. Introduction
T2V 문제는 자연스러운 움직을 모델링하는 과정과 Temporal Data dimension을 추가하며 발생하는 연산 비용 문제가 있다. 기존의 방법론들은 저해상도 저프레임 KeyFrame을 바탕으로 Temporal SuperResolution(TSR) 과정과 Spatial SuperResolution(SSR)을 진행한다.
위와 같은 Temporal Cascade를 사용하는 방식은 3가지 문제가 존재한다.
- Base Model은 sub-sampled keyframe을 보간하는 방식이기 때문에, temporally aliased, ambiguous해진다.
- TSR 모듈은 temporal upsampling 과정에서 추가되는 aliasing을 해결하지 못함.
- 추가적으로 TSR 모델의 학습은 실제 데이터를 downsampling하여 사용하지만, 실제 데이터를 보간하는 과정에서는 노이즈가 포함된 데이터를 사용하기 때문에 이 과정에서 Domain Gap이 존재한다.
따라서 저자들은 space, time을 한꺼번에 Downsampling하는 과정을 통해 compact한 space-time 표현으로 만든 뒤, 전체 프레임을 한번에 생성한다. 저자들은 SSR에 대해서도 Upsampling 과정에서 서로 다른 window로 Upsampled Data를 합치는 과정에서 Inconsistent해진다는 문제가 있어 Multidiffusion을 사용한다고 한다.
3. Lumiere
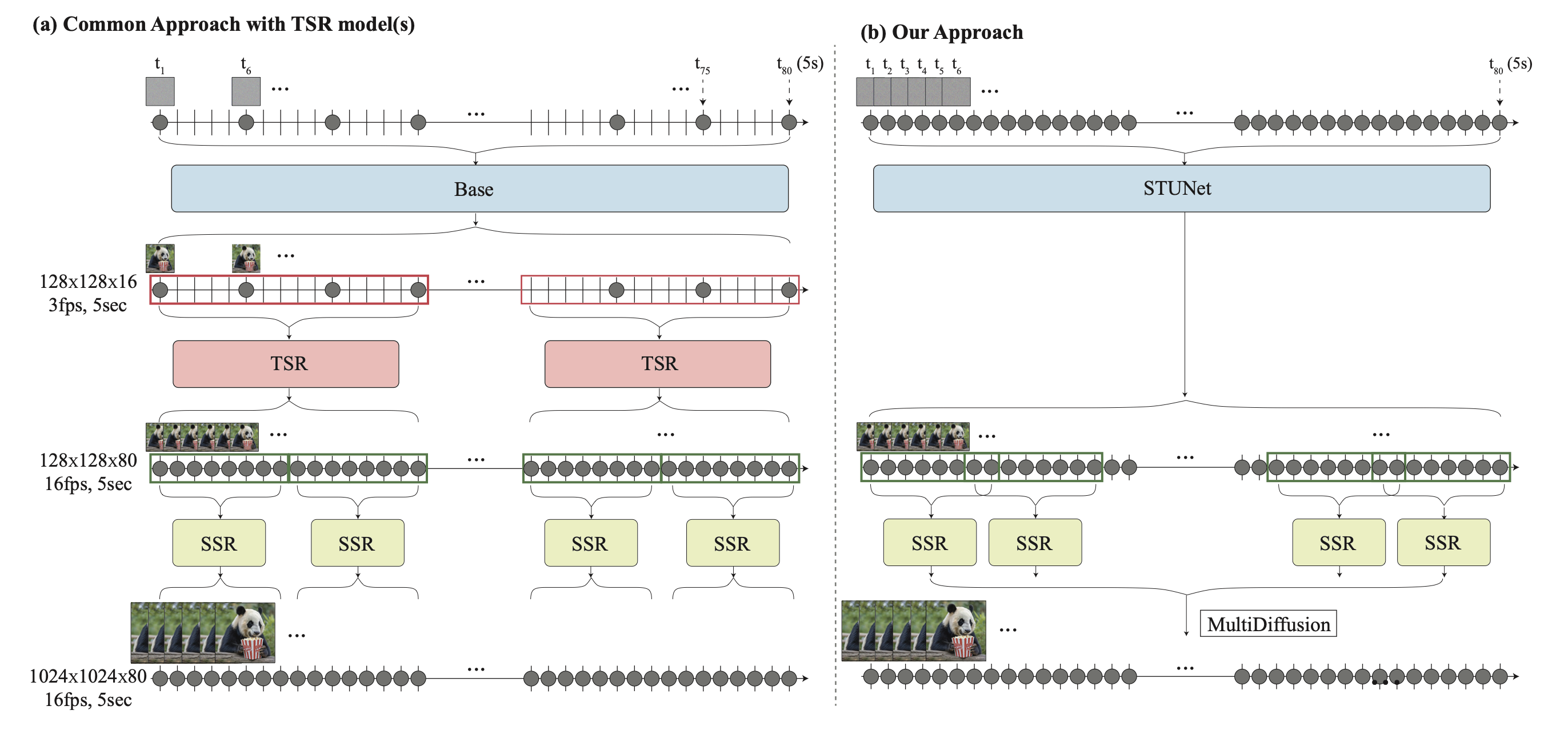
전체적인 과정은 위와 같다. 위 Figure를 통해서 확인할 수 있듯이 가장 중요한 점은 Temporal Super-resolution을 진행하는 과정이 빠져있다는 점이다.
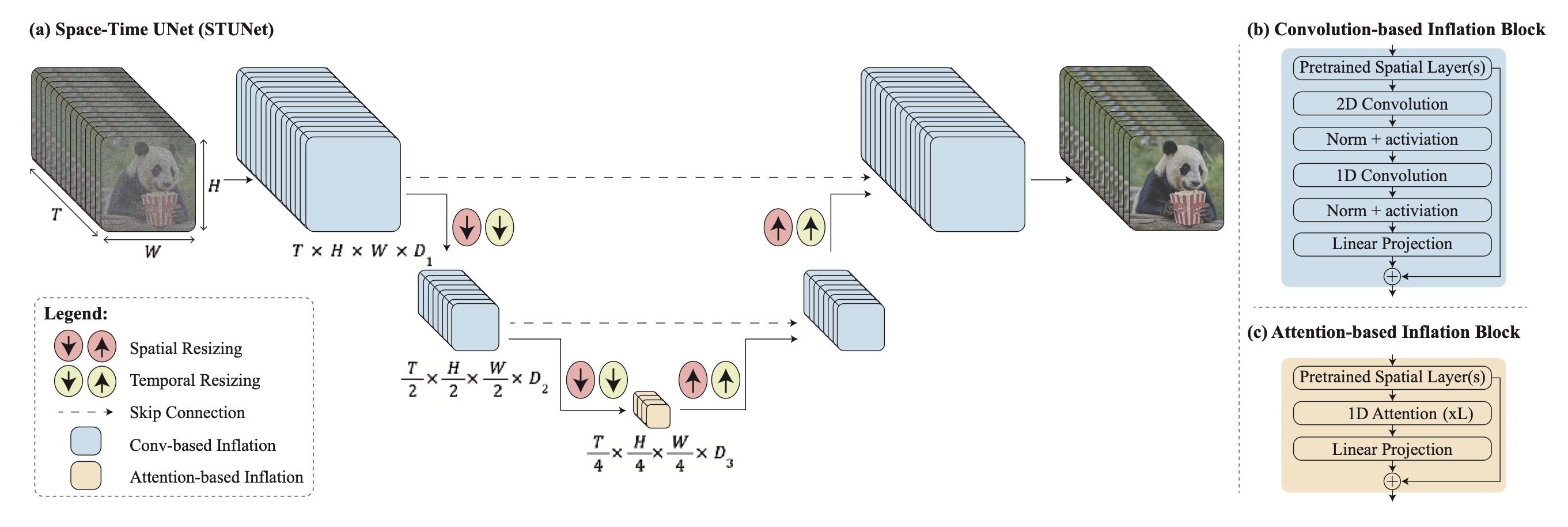
이 논문은 모든 Temporal Information을 한번에 처리하려는 과정이기 때문에 기존에 show 1에서 사용하던 방식을 사용하면 연산량이 너무 커진다. 따라서 이를 해결하기 위해서 Down/Upsampling 과정에서는 기존 Spatial Layer에 Temporal Conv만 추가하고 Bottleneck 과정에서는 Temporal Attention을 추가하는 식으로 수정해서 사용한다. Downsample되지 않은 과정에서 Attention을 사용할 수 없음에 주의하자.
이후 SSR 과정을 거치는데, 이는 Multidiffusion을 차용한다. 총 $J \in \mathcal{R}^{H \times W \times T \times 3}$ 의 전체 입력을 처리하기 위해서 ${J_i} \in \mathcal{R}^{H \times W \times T^{\prime} \times 3}$로 segment를 생성한다. 이때 $T^{\prime}$은 $T$보다 작은 과정이다 이후 이 Output을 잘 처리하기 위해서 저자들은 아래와 같은 Objective Function을 사용한다.
\[\arg\min_{J^{\prime}}\sum_{i = 1}^n ||J^{\prime} - \Phi(J_i)||^2\]결과적으로 여러 Overlapping window를 선형결합한 형태로 최종적인 J를 사용하게 된다.
4. Applications
4.1 Stylized Generation
Animediff의 방법론처럼 특정 스타일에 대해서 fine tune된 모델을 사용하여 해당 스타일의 비디오를 생성하는 과정이 존재한다. 이는 plug-and-play 방식으로 동작하지만, 결과가 왜곡되는 경우가 존재한다. 이는 학습된 temporal layer의 분포가 달라짐에 따라서 차이가 발생하는 것이라고 주장한다.
따라서 Original T2I Weight $W_{orig}$을 fine tune된 Weight $W_{style}$과 보간하여 사용한다고 한다.
4.2 Conditional Generation
영상을 생성하는 과정에서 조건을 입력받아 생성하는 경우가 훨씬 많다. $J \in \mathcal{R}^{H \times W \times T \times 3}$의 입력에 추가로 $C \in \mathcal{R}^{H \times W \times T \times 3}$라는 condition과 $M \in \mathcal{R}^{H \times W \times T \times 1}$ 마스크를 활용하여 조건부영상을 생성한다. 이 입력은 최초의 STUnet에도 적용하고 SSR에도 적용한다.
- image-to-video: C는 첫 프레임 + 나머지 blank frame, M은 첫 프레임만 unmasked.
- inpainting: C는 사용자 제공 비디오, M은 채워야 할 영역 마스크.
- cinemagraph: C는 입력 이미지를 전 프레임에 복제한 것, M은 유지/애니메이션 영역을 지정.