
ModelScope Text-to-Video Technical Report
Video Diffusion model 중 Stable diffusion 모델을 바탕으로 확장한 논문에 관한 정리이다. 논문의 순서와 정리한 순서는 달라질 수 있다. 또한 자명한 내용은 정리하지 않았다.
Abstract
Stable Diffusion Model을 Video Generation Task로 확장한 논문이다. 이 논문의 목적은 Consistent Frame Generation과 Smooth movement transition 이다. 이를 위해서 Training 과정과 Inference 과정에서 다양한 Frame 수를 처리할 수 있는 구조를 채택했다는 것이 이 논문의 핵심인 것 같다. 이를 통해서 T2I T2V 데이터를 모두 활용할 수 있기 때문이다.
내가 알기로 기존의 Video Diffusion Models이나 Make-A-Video논문에서도 이미지와 영상 데이터를 모두 활용하여 학습이 진행되었는데, 어떤 차이점이 있는지 정리해보고자 한다.
Video Diffusion Models 논문에서는 Residual block에 대해서는 temporal 축으로의 차원 추가뿐이었지만, Transformer Block에서는 Temporal Attention Matrix의 diagonal로 처리해서 Image와 공동학습을 진행했던 것으로 기억하고, Make-A-Video논문에서는 먼저 T2I 이미지를 사용하여 학습을 진행하고 Temporal Conv Layer와 Temporal Attention Layer로 pre training을 진행했던 것으로 기억함.
1. Introduction
Video Generation Model은 훈련 과정에 어려움이 존재한다. 따라서 Fidelity와 Motion discontinuity와 같은 문제가 있었다. Stable Diffusion은 T2I에서 좋은 성능을 보여주었지만, 이 구조를 활용하여 Video generation을 촉진시킨 논문은 이전까지 없었다.
따라서 저자들은 LDM을 Temporal Block을 추가하는 방식으로 Video Generation Task로 확장하였고, Multi Frame Training Strategy를 사용하여 이미지와 영상 모두를 사용한 학습 방법을 제안했다.
2. Related Work
2.1 Diffusion Probabilistic Models
DPM 모델은 Diversity와 Fidelity 측면에서 다른 어떤 모델들보다 더 좋은 Image Synthesis 성능을 보였다. 다만, DPM 모델의 특성상 발생하는 Low-efficiency 문제가 존재했고, 이를 해결하기 위해 LDM, LSGM, RDM 등의 방법론들이 제안되어 더 낮은 dimension에서의 image generation을 진행했다. 저자들은 이 방식을 확장하여 Video generation model로 활용하고자 한다.
2.2 T2I synthesis via diffusion models
Diffusion Model은 텍스트 기반 이미지 생성으로 주로 활용되었다.
- LDM은 Unet Backbone과 Text Embedding을 Cross attention을 진행하여 이미지 합성을 진행했다.
- DALL-E2는 CLIP Encoder를 활용하여 Text Embedding으로부터 Image Embedding을 합성하는 Prior 모델과 해당 Image Embedding과 Text Embedding등을 활용하여 실제 이미지를 디코딩하는 부분으로 구성되었다.
이 모델은 Spatial 부분을 Stable Diffusion Model로 초기화하고, 이후 SpatioTemporal Block을 학습하는 방식으로 모델을 구성했다고 함.
3. Methodology
3.1 ModelScopeT2V
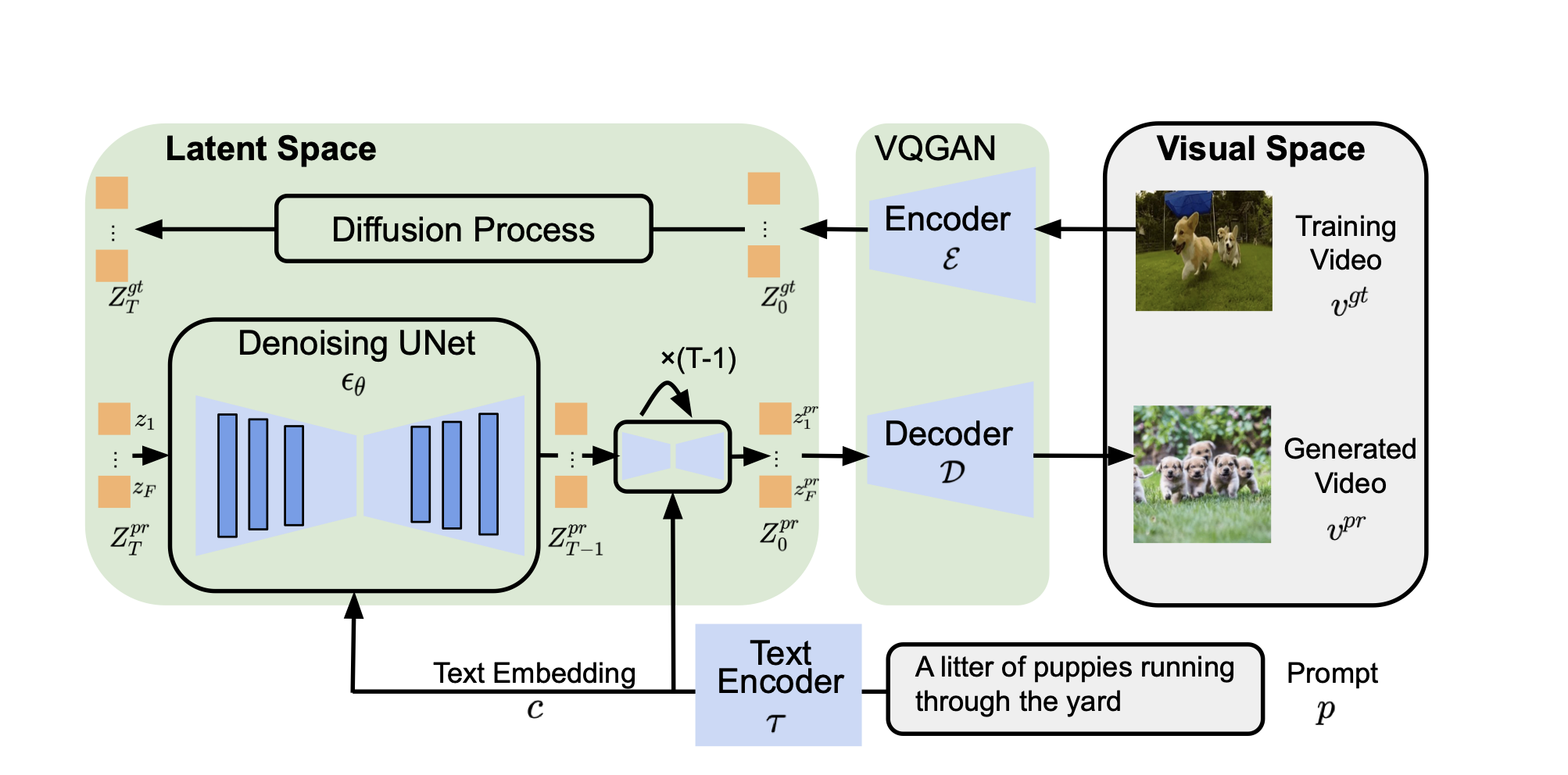
위 Figure를 바탕으로 정리해보면, 먼저 Encoder와 Decoder를 사용하여 Latent Space와 Pixel Space 간의 변환이 이루어진다. 이때 논문에서는 $Z_0^{gt} = [\mathcal{E}(f_1), \mathcal{E}(f_2)…]$로 표현하기 때문에, 각 Frame에 대해서 Encoder와 Decoder를 적용하는 것으로 이해할 수 있다.
이렇게 생성된 $Z_0^{gt}$값을 우리가 이전에 보았던 Diffusion Process를 Frame 개별에 대해서 각각 노이즈를 추가하는 방향으로 처리하면서 최종적인 $Z_T^{gt}$를 생성하고, Denoising UNet Process를 연속적으로 적용하면서 $Z_0^{pr}$를 생성하는 과정을 거친다. 이후 디코딩 과정을 각 Frame에 대해 적용하여 우리가 최종적으로 원하는 $v^{pr}$를 생성할 수 있게 된다.
정리해보면 인코더와 디코더 구조는 각 Frame에 대해서 개별적으로 진행하는 것이기 때문에 이전 Stable Diffusion과 다른 점이 없다.
3.2 Spatio-temporal Block
기본 Stable Diffusion 논문과 동일하게 이 논문 또한 UNet 구조를 바탕으로 확장을 진행했다. 논문에서는 UNet의 구조를 다음과 같은 4단계로 정리한다. Initial Block, Downsampling Block, spatio-temporal Block, Upsampling Block이다. 기존 논문에서는 Initial Block을 Encoder단에 포함시켰지만 이 논문에서는 따로 부르는 것으로 보인다.
이 논문에서는 기존에 우리가 BottleNeck이라고 불린 Layer에 대해 Temporal Information을 처리할 수 있도록 확장을 진행한다. Downsampling / Upsampling과정에 대해서는 별다른 언급이 없었기 때문에, 아래와 같이 Spatial Attention과 Text condition과의 Cross Attention으로 이해했다.
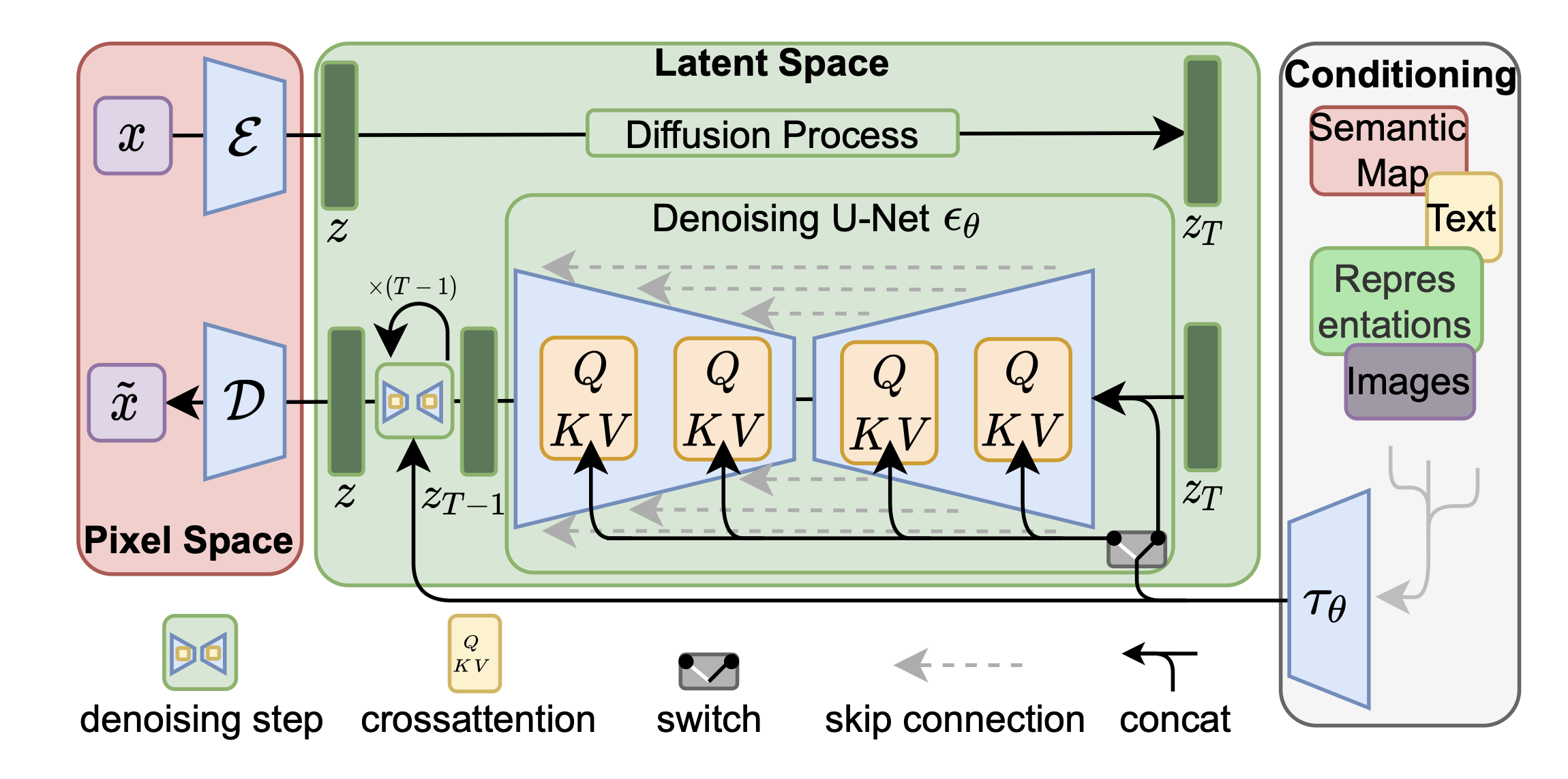
그렇다면 이 논문에서 중요하게 다룬 Spatio-temporal Block에 대해서 자세하게 살펴보아야 한다.
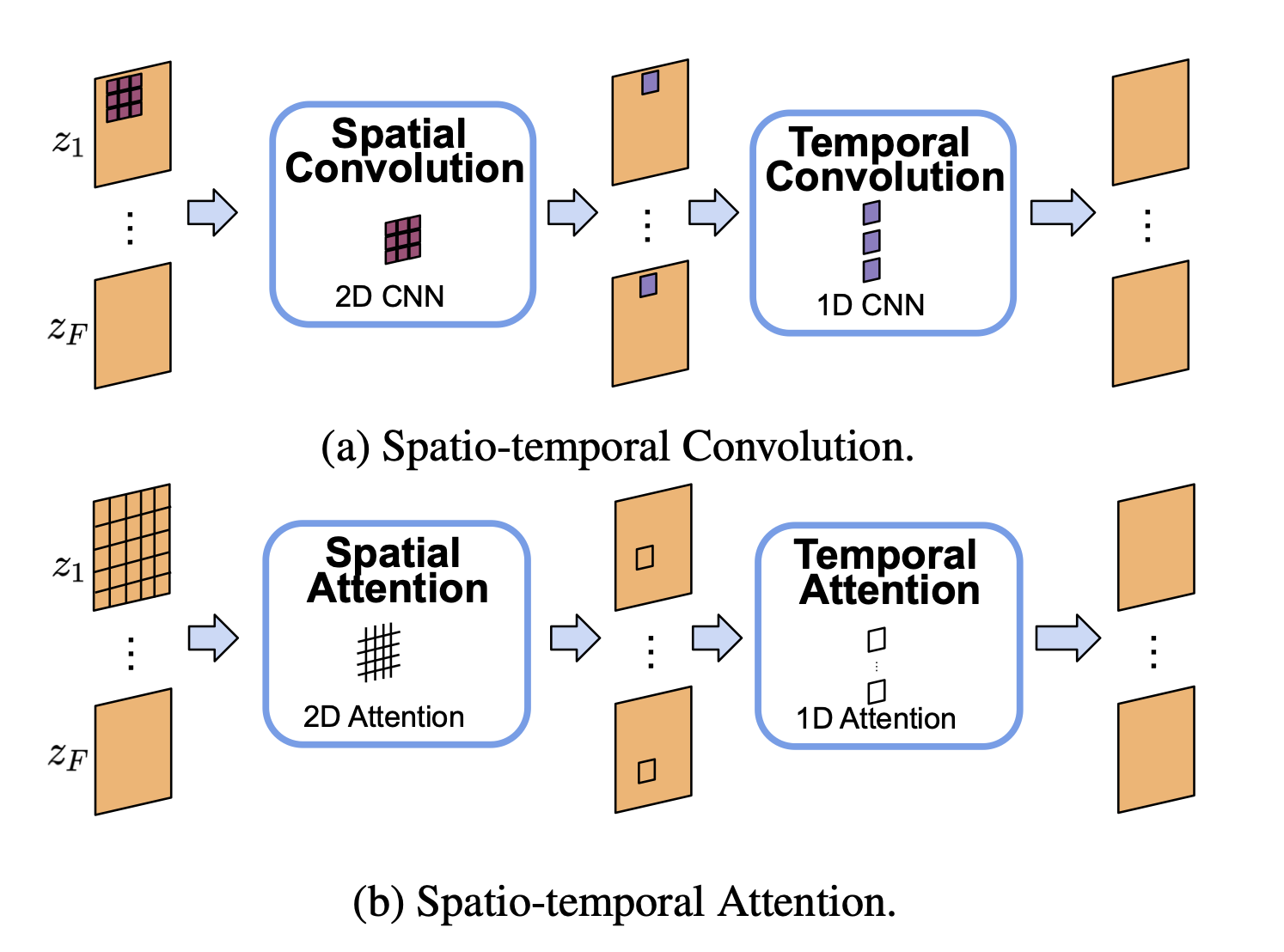
이 논문에서 BottleNeck 부분을 총 4단계의 Block으로 구분한다. Spatial Convolution -> Temporal Convolution -> Spatial Attention -> Temporal Attention 순서대로 진행하며, 각 Block은 연산 효율성과 정확도 간의 Tradeoff를 고려하여 (2,4,2,2)개의 Block을 중첩하여 사용했다고 한다.
Spatial Convolution 부분은 $1 \times 3 \times 3$의 conv unit을 사용하고, Temporal Convolution 부분은 $3 \times 1 \times 1$의 conv unit을 사용한다고 한다. 이 부분은 기존 Make-A-Video 논문과 완전히 동일한 것 같다. 추가로 Spatial, Temporal Attention도 한번에 두가지 정보를 보는 것이 아닌 Spatial / Temporal 축을 따로 처리해 연산 효율적이면서 Temporal information을 사용한 것으로 보인다.
기존 Stable diffusion과 다르게 Cross Attention을 진행하기 위해서 Text 정보를 Encoding하는 과정에서 CLIP Vit-H/14 Text-Encoder를 사용했다. 이는 이전 논문들이 Image와 Text 정보를 동일한 Latent Space로 표현하기 위해서 CLIP을 차용했던 것에 영향을 받은 것으로 보인다. 다만, 이 논문에서 Text를 Clip 인코더로 인코딩하는 것은 이미지와 동일한 Space로 변환하기 위한 것은 아닌 것으로 보인다. 그저 텍스트를 이미지 도메인에 더 적합한 방식으로 표현하는 데에 사용한 것으로 이해할 수 있다.
위와 같이 변환한 정보를 바탕으로 Cross Attention을 진행한다. 이 논문에서는 Temporal Attention 부분에서는 Text 정보와의 Cross Attention을 진행하지 않고, Spatial Attention 부분에 대해서만 Cross Attention을 진행한다고 한다. 더 자세하게는 Spatial attention의 첫번째 단계에서는 Cross Attention(Text Embedding을 K, V로 사용)을 진행하고, 두번째 단계에서는 Self Attention을 진행한다고 언급한다.
3.3 Multi Frame Training
이 논문에서 언급한 Contribution 중 하나가 바로 Image에 대해서 공동학습을 진행할 수 있다는 점이었다. 앞서 언급한 구조를 잘 살펴보면 Spatiotemporal Block에 Frame = 1로 설정하면 이미지에 대한 학습으로 자연스럽게 확장될 수 있기 때문에, 이를 반영하여 1/8 GPU에서는 Image에 대한 학습을 진행했다고 한다.
앞선 두 논문과 달리 Trained Stable Diffusion으로 Initialization을 진행해도 공동학습을 진행하는 과정에서 이미지 도메인에 대한 Forgetting문제나 Semantic Diversity를 해칠 수 있다는 점을 확실하게 다루고 있는 것으로 보인다.
4. Experiments
4.1 Implementation Details
Dataset
- LAION : T2I Dataset
- WebVid : T2V Dataset 1000만개 30초 길이 $336 \times 596$ 해상도 중에서 중간 부분을 잘라서 생성 1초에 3frame이 나오도록 생성
- MSR-VTT : T2V Dataset 10000개 하나의 영상에 대해서 20개의 자막이 존재함. 20개 중에서 랜덤으로 자막을 선택해서 영상을 생성하도록 하고, FID-vid / FVD 연산함.
Model Initialization and Hyperparameters 모델은 3개의 파트로 구성되어 있음. VQGAN / Denoising UNet은 Stable Diffusion에서 그대로 가져옴. 추가적인 Text Encoder는 우리가 알듯 Clip-Vit를 활용함.
Training Details VQGAN의 Compression Factor는 8을 사용한다. $256 \times 256$ 이미지를 $32 \times 32$의 Latent Vector로 표현하여 사용한다는 의미임. 추가적으로 Text Encoding 이후의 크기는 $N_p \times N_c$로 표현할 수 있는데, Prompt의 최대 크기에 해당하는 $N_p$의 값은 77을, $N_c$의 임베딩 크기는 768을 사용한다.
추가적으로 저자들은 Temporal Convolution과 Temporal Attention 중 하나만 사용해도 성능이 좋아진다는 점을 확인했고, 논문에서는 2가지를 모두 사용하여 성능을 더욱 극대화했다. 추가적으로 Temporal convolution의 층수를 늘린다면 시간적 지각 능력이 좋아질 수 있다는 점을 확인했다. 다만, 16 프레임에는 $3^4$의 Receptive Field면 충분하기 때문에 논문에서는 더 이상 늘리지 않았다고 함.
4.2 Quantitative Results

위 표를 통해서 확인할 수 있듯이 최고의 FID-vid 성능을 보인다. 저자들은 CLIPSIM 점수가 Make-A-Video보다 낮은 이유를 그들이 HD-VILA-100M 데이터셋에서 추가적인 학습을 진행했기 때문이라고 함.
4.3 Qualitative Results
Make-A-Video 논문의 방법론과 이 논문의 방법론을 적용했을 때, 둘 다 좋은 성능을 보이지만 특정 사례에서는 이 논문의 방법론이 더 좋다고 평가함. 추가적으로 Hyper-realistic photo of an abandoned industrial site during a storm이라는 조건이 주어졌을 때, Make-A-Video의 방법론은 프롬프트에 완전히 정렬되게, 산업 단지와 폭풍이라는 조건을 이미지로 표현했지만, 이 논문의 방법론은 더 동적인 정보를 담는다. 이는 Make-A-Video 논문에서 Video 생성 과정에 CLIP embedding을 사용하기 때문이며 동적인 능력이 떨어진다고 한다.
5. Conclusion
본 논문은 시간적 동역학 modeling 능력을 향상시키기 위해, spatio-temporal convolution과 spatio-temporal attention을 포함하는 spatio-temporal block을 설계하였다. 또한, 포괄적인 시각 콘텐츠-텍스트 쌍으로부터 의미 정보를 활용하기 위해, 텍스트-이미지 쌍과 텍스트-비디오 쌍 모두에 대해 multi-frame training을 수행하였다. ModelScopeT2V가 생성한 비디오와 다른 최신 방법들이 생성한 비디오의 비교 분석은 정량적 / 정성적으로 유사하거나 더 우수한 성능을 보여 준다.