
Chapter 1 - Introduction
학습이라는 것은 주변 환경과 상호작용하며 진행되는 과정이다. 주변 환경과의 연결을 반복해서 경험하다 보면, 인과관계, 행동의 결과, 목적을 이루기 위해 해야 할 것들에 대한 정보가 쌓이게 된다. 주변 환경과 상호작용으로부터 배운다는 것은 학습에 관한 모든 이론의 기저에 깔린 개념이다.
1.1 Reinforcement Learning
강화학습은 주어진 State에서 어떤 Action을 취할 지를 학습한다. 결과적으로 Maximum Reward를 얻는 방향으로 학습이 주어지는데, 강화학습은 State $S_t$에 대한 Action $A_t$로부터 받는 즉각적인 Reward 뿐만 아니라, $t + 1$ 시점 이후의 Reward에도 영향을 미치는 지연된 보상 상황이 학습을 어렵게 하는 요인이다.
Reinforcement Learning은Supervised Learning이나 Unsupervisied Learning과는 다르다.
책의 내용을 따르자면 Supervised Learning은 시스템의 행동을 예측하거나 일반화함으로써 일반화 성능을 최대한으로 끌어올리는 학습 방식인데, 이는 환경과 상호작용하여 학습하는 강화학습과는 맞지 않는다고 한다. 아래는 내가 생각하는 추가적인 차이점이다.
- Supervised Learning은 어떤 data X에 대한 정답 label y가 반드시 존재한다. 반면, 강화학습에 사용하는 데이터는
StateS에 대한 정답 Action이라는 것이 주어져 있지 않다. 최종적인 Reward가 주어지고 이를 바탕으로 학습을 진행하는 것이므로 본질적으로 다르다. - Supervised Learning에서 사용하는 Data는 I.I.D 분포를 따르지만, Reinforcement Learning에서 사용하는 Data는 해당 분포를 따르지 않고 오히려 Agent의 Policy에 의해서 결정되기 때문에 dependent한 성질을 가진다. 따라서 학습에 사용되는 data는 policy에 따라 언제든지 바뀔 수 있다.
추가적으로 Unsupervised Learning과도 많은 차이점이 있다. Unsupervised Learning은 Data 내부의 숨겨진 구조를 찾는 것을 목적으로 하지만, 강화학습은 단지 Reward를 최대화하려고 할 뿐, 숨겨진 구조에는 관심이 없다.
앞에서 언급했던 것처럼, 강화학습은 현재 상태(State)에서 어떤 행동(Action)을 선택해야 장기적으로 얻을 수 있는 누적 보상(Return)이 최대가 되는지를 학습한다. 다만, 학습 과정에서의 데이터는 정적이지 않고, Policy에 따라서 다양하게 형성된다.
이 때문에 강화학습에서는 다음 두 과정이 중요하다:
- Exploitation: 지금까지의 경험을 바탕으로 현재 가장 높은 보상을 줄 것으로 예상되는 행동 선택
- Exploration: 아직 충분히 시도해보지 않은 행동을 선택하여 더 좋은 행동이 존재하는지를 탐색
이는 강화학습 데이터의 분포가 policy에 의해 결정되고 지속적으로 달라지기 때문이며, 에이전트는 스스로 만든 경험에 의존해 학습해야 하므로 두 요소의 균형이 매우 중요하다.
1.2 Components of Reinforcement Learning
강화학습의 구성요소는 아래와 같이 정리할 수 있다. 마지막 Model만 제외하고 나머지는 모두 필수적인 구성 요소들이다.
- Agent, Enviroment
- Policy
- Reward Signal
- Value Function
- Model
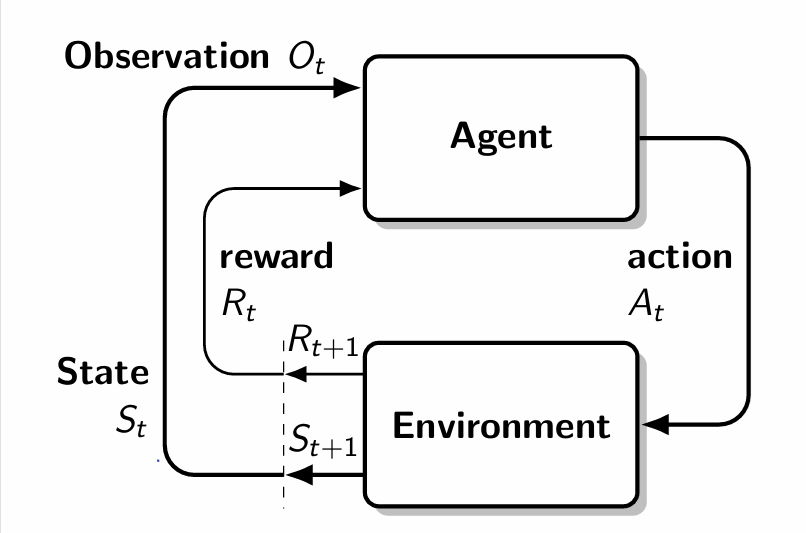
전체적으로 흐름을 살펴보면 위와 같다 $S_t$ 에 대한 $A_t$ 이후 $R_{t+1}$과 다음 state $S_{t+1}$이 나오고 이것이 terminal state가 될 때까지 반복하는 것이다.
1.2.0 Agent & Enviroment
Agent는 환경 안에서 State를 인식하고 Action을 취하는 객체를 의미한다. 간단한 환경에서는 Single Agent를 가정하지만, 축구와 같은 환경에서는 복잡한 환경에서는 Multi Agent를 사용하여 진행해야 할 수 도 있다.
Environment는 Agent가 상호작용하는 대상이다. 강화학습에서는 MDP(Markov Decision Process)를 가정하고 있으며 POMDP, FOMDP 등등으로 나눌 수 있다.
1.2.1 Policy
Policy는 State $S_t$에 대응하는 Action$A_t$를 결정하는 것을 의미한다. 간단한 경우라면 Loop up table과 같이 표현할 수 있지만, 복잡한 경우라면 많은 계산을 통해서 Action을 결정할 수 있을 것이다. Policy는 State에 Deterministic하게 Action을 결정할 수도 있고, Probablistic하게 Action을 결정할 수도 있다.
1.2.2 Reward Signal
Reward Signal은 모든 timestep $t$에 대응하여 즉각적인 보상인 Reward $r_t$를 Agent에게 전달한다. Agent의 목표는 장기간의 Reward의 총합이 최대가 되도록 하는 것인데, 이는 현실적인 연산을 위해 Decay Factor $\gamma$를 사용하여 표현하게 되고, 결국 장기적인 Reward sum = Return이 최대가 되도록 한다.
\[G_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \cdots\]위 식이 Return의 식이라고 볼 수 있다.
Agent는 현재 시점 $t$에서 Action $A_t$를 취했지만, 작은 $\gamma_t$를 받았을 때, 즉각적인 Reward에만 집중하는 policy를 가지고 있었다면, 다음에 동일한 State $S_t$를 만났을 때, 동일한 Action을 할 확률은 굉장히 낮아질 것이다. Reward Signal은 Environment’s State와 Action에 대해 stochastic하게 결정된다.
1.2.3 Value Function
Value Function, 가치함수란 Current state에서 Agent가 앞으로 얻을 수 있는 Return에 대한 기댓값을 연산하는 것을 의미한다. 이를 식으로 표현하면 아래와 같다.
\[G_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \cdots\]앞서 설명했듯, $G_t$라는 Return이라는 것은 현재 시점 $t$ 이후의 Reward의 weighted Sum이다. $t = 0$ 이라는 가정이라면 전체 Reward의 weighted sum이 될 것이다. 그렇다면, 시점 $t$에서의 Value는 아래와 같다.
State-Value Function
Action-Value Function
이는 실제 Reward의 Sum으로 이루어진 것이 아니라, 현재 Policy를 따랐을 때, Reward에 대한 기댓값을 구하는 것으로 정확하지는 않은 값이다. 하지만, 결정을 내리고 해당 결정을 평가하는 것 또한 단기적인 Reward가 아닌 Value를 통해 진행된다. 궁극적인 목적은 Return을 최대화하는 것이기 때문이다.
1.2.4 Environment Model
환경 모델은 실제 환경을 모사하는 역할을 한다. $(S_t,A_t)$에 대응하는 $(S_{t+1}, r_{t+1})$를 예측하는 것인데 이는 미래의 상황을 실제로 경험하기 이전에 가능성을 통해 다음 행동과 Reward를 결정하는 Planning에 주로 사용된다. Planning을 사용하지 않는 것은 오로지 Trial-and-Error만을 통해서 학습을 진행하는 것이다.
1.3 Limitations and Scope
강화학습은 State의 개념에 의존적이다. State는 환경이 어떤 모습을 하고 있는지에 대한 정보를 Agent에게 전달하는 신호라고 생각할 수 있다. Agent가 Environment의 모든 정보를 활용할 수 있는 경우는 매우 드문 환경이고, 대부분은 완전하게 파악할 수 없으며 이는 POMDP(Partially-Observable-MDP)라고 부른다. 다르게 생각하면 환경의 구성 요소인 Preprocessing system이 State를 Agent에게 제공한다고 볼 수 있다.
대부분의 강화학습 알고리즘은 Value Function을 추정하는 방식을 사용한다. Value Function을 직접적으로 활용하지 않는 방법도 존재하는데 Genetic Algorithm, Genetic Programming, Simulated Annealing과 같은 최적화 방법론들이 존재한다. 위 알고리즘들은 불연속적으로 상호작용하는 여러 정적 정책을 사용하고, 가장 큰 보상을 얻는 Policy와 해당 Policy에 대한 Mutation이 다음 세대 정책으로 활용되는 과정을 반복한다.
이런 Evolutionary 방법은 Policy의 수가 작거나, 탐색할 시간이 충분한 경우에는 효과적일 수 있고, Agent가 Environment의 완전한 상태를 감지할 수 없다는 문제를 해결하는 데 도움이 된다. 책에서는 Value function을 직접적으로 활용하는 것이 더 효과적인 학습이라 생각하여 진화론적 방법들은 다루지 않는다.
1.4 AN EXTENDED EXAMPLE: TIC-TAC-TOE
위와 같은 Tic-Tac-Toe 예시를 통해서 더 자세히 설명해보자. 이 게임에 숙달된 사람이라면, 무조건 이기도록 할 수 있기 때문에, 여기에서의 예시는 숙달되지 않은 플레이어와의 대결이다.
1.4.1 Traditional Approach
전통적인 방법으로는 Mini-Max Method와 Dynamic Programming Method를 떠올릴 수 있을 것이다.
Mini-Max Method는 항상 상대방이 최적의 선택을 한다는 가정 하에서 나는 어떤 선택을 해야할 지에 대한 결정을 내리는 방법으로, 이 예시의 가정과는 상충되어 사용할 수 없다. 또한 Dynamic Programming 방법으로 풀려고 해도, 상대방의 행동에 대한 정보($p_{\pi}(s, a)$)가 존재하지 않기에 사용할 수 없다.
최선의 방법은 상대방의 행동에 대한 모델을 학습하고, DP를 적용하여 문제를 푸는 것이다.
1.4.2 Evolutionary Approach
진화적 방법으로는 모든 X, O 조합에서 어떤 선택을 해야 하는지를 알려주는 규칙을 정책으로 삼고, 여러 정책들 중에서 실제로 무수히 많은 실행에서 좋은 성능을 보인 정책을 바탕으로 다음 번에 어떤 정책을 사용할 것인지를 결정할 수 있다.
1.4.3 Value Function Approach
가치함수를 사용하여 문제를 푸는 방식이 있다. 앞서 말한 강화학습의 기본 구성에 포함되는 Value function을 사용하는 것인데, 이런 간단한 문제에서는 Look Up Table을 활용하여 일어날 수 있는 모든 상태에 대한 숫자 하나씩을 부여할 수 있다. 여기에서의 숫자는 승리할 확률에 대한 추정값으로 가정한다.
이 LookUp Table을 활용하여 게임을 진행한다고 했을 때, 매 순간 Agent는 현재 State에서 Action을 취했을 때의 Value를 면밀하게 따져보고, Value를 Maximize하는 Action을 선택하게 된다. 이는 Greedy Policy라고 부른다. 하지만 내가 해보지 않은 Action이 더 좋은 성능을 보일 수 있기 때문에 Exploratory Action을 때때로 수행하며, 선택의 폭 또한 점점 넓혀간다. 이를 $\mathbf{\varepsilon}$-greedy Policy 라고 부른다.
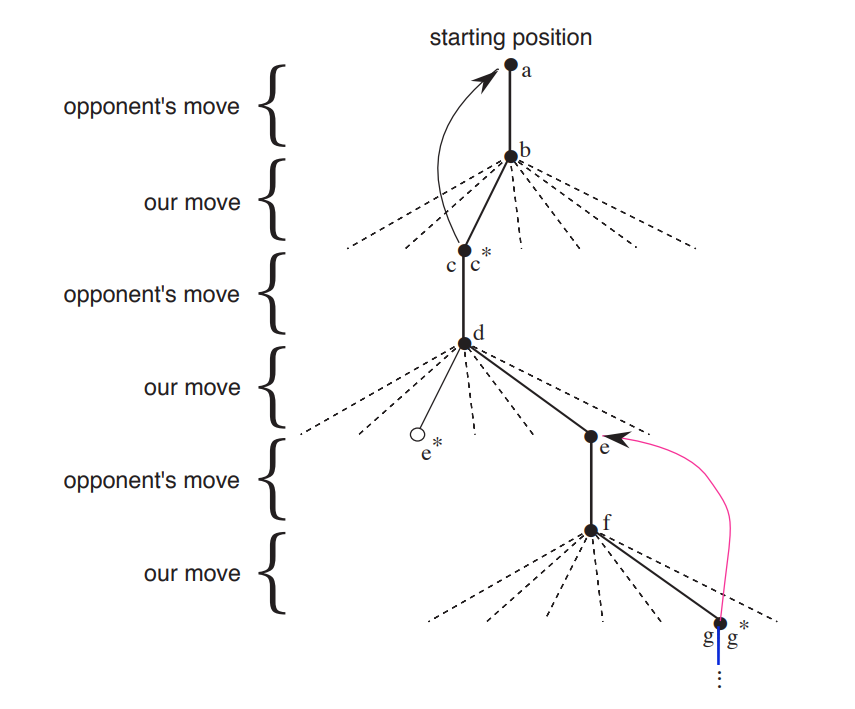
위 예시를 통해서 쉽게 이해할 수 있다. 매 순간 $\mathbf{\varepsilon}$-greedy Policy에 따라서 $Q(s, a)$가 최대가 되는 action을 파악한다. 이는 $*$를 통해 표현이 되었고, 두번째 선택에 대해서는 해당 Action을 따르지 않고 다른 Action을 따른 것을 확인할 수 있다. 이는 Exploratory Action을 수행한 것이고 이를 통해서 현재 Policy에 따르면 Greedy하지 않은 것일지라도 경험할 수 있게 된다.
Our second move was an exploratory move, meaning that it was taken even though another sibling move, the one leading to e∗, was ranked higher. Exploratory moves do not result in any learning, but each of our other moves does, causing backups as suggested by the curved arrows and detailed in the text.
위 설명에서 혼동할 수 있는 표현이 있다. Exploratory moves do not result in any learning but each of out other moves does... 책에서는 이렇게 표현하고 있지만 실제로는 Greedy policy 상, Policy Evaluation(Value function Estimation) 과정에서 사용되지 않는다는 의미이고, Policy Update 과정에는 사용한다. Policy Evaluation -> Policy Update를 반복하는 과정은 전통적인 Policy Iteration 과정이다.
Policy Evaluation은 각 State 별 Value 값을 정확하게 추정할 수 있도록 계속해서 Value 값을 Update해 나가는 것을 의미한다. 이전 상태의 가치를 다음 상태의 가치와 가까워지는 방향으로 일정 부분 경험하는 것인데, 최종 State에 가까워질수록 더 정확한 가치를 담고 있기 때문이다. 이는 아래와 같은 식으로 표현할 수 있으며, TD-Learning(Temporal-Difference Learning) 의 일종이다.
Policy Update는 $\underset{a}{\operatorname{argmax}} Q(s,a)$를 만족하는 Action을 찾는 과정이므로 Policy Evaluation 이후에 Policy Improvement를 통해 더 좋은 Policy를 가질 수 있도록 한다.
Evolutionary Approach와 Value Function Approach의 차이점을 정리해보면 아래와 같다.
Evolutionary Approach는 승리의 빈도수를 바탕으로 승리할 확률에 대한 Unbiased 추정값 사용.Evolutionary Approach는 게임의 최종 결과만을 사용.Value Function Approach는 게임 도중에 발생한 정보를 활용하여 학습을 진행.
1.5 Conclusion
강화학습은 여러 가지 변주가 있다.
- 보상의 관점에서
마지막 에피소드만vs언제든지 보상이 주어짐 - 시간 간격의 관점에서
DiscretevsContinuous - 상태의 관점에서
DefinitevsInfinite- 무한한 State를 사용하는 경우라면 인공 신경망을 결합하여 문제를 해결할 수 있다. 인공신경망을 사용하여 과거의 경험을 잘 일반화하여 Infinite State를 적절히 Compress할 수 있다.
- 모델의 관점에서 모델 유무도 구분할 수 있다.