
Chapter 4 Dynamic Programming
Dynamic Programming을 RL에 적용하기 위해서는 MDP와 같은 완전한 환경 모델이 주어져야 한다. 다만 고전적인 DP 알고리즘은 굉장히 많은 연산량이 필요하기 때문에 현실적으로는 진행하지 못할 가능성이 크다. 책의 뒤에서 다루는 MC나 TD 방법론들은 적은 연산으로도 동일한 효과를 얻기 위한 과정이라고 볼 수 있다.
책에서는 DP를 소개할 때의 환경을 Finite MDP로 가정한다. 즉, State나 Action이 유한개이고, Transition Probability $P(r, s’ \mid s, a)$가 주어져 있다고 가정하는 것이다. Continuous space 또한 근사나 양자화를 통해서 finite하게 다룰 수 있으므로 Finite MDP가 기본이다.
DP는 3장에서 다룬 Value function을 구하고 value를 maximize하는 행동을 선택하도록 policy를 구하는 과정을 거친다. 결국 Optimal Value Function을 구하는 과정이 DP라고 생각할 수 있다. 3장에서 다루었던 것처럼 최적 가치함수는 아래의 수식을 만족한다.
\[\begin{align} v_*(s) &\doteq \max_{a\in\mathcal{A}(s)} \mathbb{E}\!\left[ R_{t+1} + \gamma v_*(S_{t+1}) \mid S_t=s,\; A_t=a \right] \\[8pt] &= \max_{a\in\mathcal{A}(s)} \sum_{s'\in\mathcal{S}}\sum_{r\in\mathcal{R}} p(s',r\mid s,a)\, \Bigl[r + \gamma v_*(s')\Bigr]. \end{align}\] \[\begin{align} q_*(s,a) &= \mathbb{E}\!\left[ R_{t+1} + \gamma \max_{a'} q_*(S_{t+1},a') \;\middle|\; S_t=s,\; A_t=a \right] \\[8pt] &= \sum_{s'\in\mathcal{S}} \sum_{r\in\mathcal{R}} p(s',r\mid s,a)\, \left[ r + \gamma \max_{a'} q_*(s',a') \right]. \end{align}\]DP의 큰 두 축은 위 Bellman Equation을 Assignment Rule로 변경하는 과정으로 이해할 수 있다.
4.1 Policy Evaluation
4.1.1 Iterative Policy Evaluation
임의의 정책 $\pi$에 대한 정확한 가치함수를 계산하는 과정을 Policy Evaluation / Prediction Problem이라 한다. 정책에 대한 정확한 가치함수를 알고 있다면 아래의 수식이 성립한다.
\[\begin{align} v_\pi(s) &= \sum_{a\in\mathcal{A}(s)} \pi(a\mid s)\; q_\pi(s,a) \\[4pt] &= \sum_{a\in\mathcal{A}(s)} \pi(a\mid s) \sum_{s'\in\mathcal{S}}\sum_{r\in\mathcal{R}} p(s',r\mid s,a)\; \Bigl[r + \gamma v_\pi(s')\Bigr]. \end{align}\]모든 환경 정보를 알고 있다면 $\mid S \mid$개의 선형연립방정식을 푸는 것이기에 풀 수 있지만 Iterative Method을 사용하여 해결하는 것이 가능하다. $v_k$의 존재를 보장한다면, 아래와 같은 Update 식을 $\infty$번 반복하여 최종적으로 정확하게 $v_{\pi}$로 성립하게 된다. 아래와 같은 반복적인 방법을 사용하는 것을 Iterative Policy Evaluation이라 한다.
\[\begin{align} v_{k+1}(s) &= \mathbb{E}_{\pi}\!\left[ R_{t+1} + \gamma v_k(S_{t+1}) \mid S_t = s \right] \\ &= \sum_{a} \pi(a \mid s) \sum_{s', r} p(s', r \mid s, a) \left[ r + \gamma v_k(s') \right]. \end{align}\]위 수식을 생각해보면, One step transition으로 발생할 수 있는 즉각적인 Reward와 다음 state의 가치의 기댓값을 활용하여 현재 state의 가치를 갱신하는 것으로 이해할 수 있다. 따라서 이를 Expected Update(기댓값 갱신)이라고 부른다. 기댓값을 어떻게 활용하여 사용하느냐에 따라 다양한 기댓값 갱신이 존재한다.
4.1.2 Synchronous & Asynchronous backup
$v_k$를 구현하는 과정을 자세히 살펴보면, value function 변경을 즉각적으로 반영하느냐 아니냐에 따라서 나눌 수 있다. 두 개의 배열을 사용하여 이전의 step의 value function만을 사용하는 synchronous backup 또한 존재할 수 있지만, 하나의 배열을 사용하여 업데이트된 최신 value function을 활용하는 일종의 asynchronous backup도 활용할 수 있기 때문이다. 다만, 비동기적 갱신 방법을 사용하는 경우 상태 공간에 대한 sweep(일괄처리) 순서가 순서에 큰 영향을 미친다.
$v_k$ 가치를 업데이트하는 과정에서 이전 $v_{k - 1}$번째 가치만을 사용하여 update하는 것이 바로 Synchronous Backup이므로 update 순서는 전혀 의미가 없다. 하지만, $v_k$의 값이 아니라 그냥 $v$로 단일 공간에 값을 저장하게 된다면, $k$번째 update하는 과정에 사용되는 value가 사실은 $k$보다 적거나 더 많은 횟수의 update 이후의 값일 수도 있기 때문이다. 비동기적 Update를 하나 동기적으로 Update를 하나 Converge는 언제나 보장되어 있기 때문에, 비동기적으로 Update하는 경우의 수렴 속도가 동기적 Update보다 빠르다.
4.1.3 Pesudo code Implementation
아래는 비동기적 Policy Evaluation을 진행하는 경우의 의사코드를 나타낸다. Policy Evaluation 과정은 Policy를 따랐을 때의 Value를 파악하는 Prediction Task에 해당하기 때문에, Input으로는 Policy $\pi$가 들어가고, 최종적으로 모든 state에 대한 $v(s)$를 결과값으로 내놓는다.
\[\begin{aligned} &\textbf{Input:}\ \pi,\ \text{the policy to be evaluated}\\ &\textbf{Initialize:}\ V(s)=0,\ \forall s\in \mathcal{S}^{+}\\[2mm] &\textbf{Repeat:}\\ &\quad \Delta \leftarrow 0\\ &\quad \textbf{for each } s\in \mathcal{S}:\\ &\qquad v \leftarrow V(s)\\ &\qquad V(s) \leftarrow \sum_{a}\pi(a\mid s)\sum_{s',r}p(s',r\mid s,a)\bigl[r+\gamma V(s')\bigr)\\ &\qquad \Delta \leftarrow \max\!\bigl(\Delta,\ |v - V(s)|\bigr)\\[1mm] &\textbf{until}\ \Delta < \theta \quad (\theta>0\ \text{is a small positive number})\\[1mm] &\textbf{Output:}\ V \approx v_{\pi} \end{aligned}\]위 의사코드를 통해서 확인할 수 있듯이, $v_k(s)$와 $v_{k+1}(s)$가 모든 state에 대해서 동일한 경우에 Bellman Expectation Equation이 성립하여 완전한 $v_{\pi}$를 구할 수 있지만, 현실적으로는 의미가 크지 않기 때문에, 일정 threshold $\theta$ 보다 차이가 작다면 그냥 수렴했다고 가정한다. 이는 현실적인 제약조건으로 후에 MC나 TD에서도 동일한 과정으로 수렴했다고 가정한다.
4.2 Policy Improvement
4.1에서 특정 Policy $\pi$를 따르는 value function을 구하는 방법에 대해서 다루었다. 이 Value function을 바탕으로 새로운 Policy를 생성 해내는 것이 가능한데, 이를 우리는 Policy Improvement라고 부른다. Policy Improvement는 Policy가 어떤 것이냐에 따라서 다르게 정의될 수도 있지만, Deterministic하든, Stochastic하든 $\pi(a\mid s) = \arg \max_a v(s)$의 수식이 성립하도록 새로운 policy를 생성하는 것이라고 보면 된다.
위와 같이 value function에 대한 argmax를 취한 것이 왜 기존보다 더 좋은 Policy가 되는지를 수식적으로 증명할 필요가 있다. 새로운 Policy $\pi ‘$를 처음에는 a $\neq$ $\pi(a \mid s)$ 를 취하고 나서 다음부터는 기존과 동일하게 $\pi$를 따른다고 가정해보자. 이때 새로운 $\pi ‘$에 대한 action value function은 아래와 같이 표현할 수 있다.
\[\begin{align} q_{\pi}(s, a) & = \sum_{r \in\mathcal R} \sum_{s' \in\mathcal S} P(r', s' \mid s, a)\{r + \gamma\sum_{a' \in\mathcal A(s')} \pi(a' \mid s') q_{\pi}(s', a')\} \\ & = \mathbb{E}_{\pi}[R_{t+1} + \gamma v_{\pi}(S_{t+1}) \mid S_t = s, A_t = a] \end{align}\]Action Value function이고, $\pi$에 대한 action value이기 때문에 위와 같이 표현할 수 있게 된다. $q_{\pi}(s, \pi(s))$와는 다른 결과를 보이는데, $q_{\pi}(s, \pi(s))$는 사실 $v_{\pi}(s)$와 동일하기 때문에, $q_{\pi}(s, a \neq \pi(s))$인 Action Value의 값이 실제로 State Value보다 더 좋은 결과를 가져온다면 새로운 Policy를 따는 것이 옳다고 생각할 수 있고, 결국에 동일한 state s를 다시 마주했을 때, 계속해서 a를 선택하는 것이 결과적으로 옳기 때문에, 새로운 Policy로 Update할 수 있게 된다.
이는 정책 개선 정리(Policy Improvement Theorem)라고 부르며 현재 정책 $\pi$를 기준으로 한 가치함수보다 모든 state에서 더 좋거나 동일한 action을 취하는 policy $\pi’$는 가치함수가 모든 state에서 $v_{\pi}$보다 좋거나 같을 수 밖에 없다는 것을 의미한다. 결국 수식으로 표현하면 $q_{\pi}(s, \pi’(s)) \ge q_{\pi}(s, \pi(s)) = v_{\pi}(s)$를 만족한다는 것을 의미한다. 이를 수식으로 증명하면 아래와 같다.
\[\begin{align} v_{\pi}(s) & \le q_{\pi}(s, \pi'(s)) \\ & = \mathbb{E}[R_{t+1} + \gamma v_{\pi}(S_{t+1}) \mid S_t = s, A_t = \pi'(s)] \\ & = \mathbb{E}_{\pi'}[R_{t+1} + \gamma v_{\pi}(S_{t+1}) \mid S_t = s] \\ & \le \mathbb{E}_{\pi'}[R_{t+1} + \gamma q_{\pi}(S_{t+1}, \pi'(S_{t+1})) \mid S_t = s] \\ & = \mathbb{E}_{\pi'}[R_{t+1} + \gamma \mathbb{E}_{\pi'}[R_{t+2} + \gamma v_{\pi}(S_{t+2}) \mid S_{t+1}] \mid S_t = s] \\ & = \mathbb{E}_{\pi'}[R_{t+1} + \gamma R_{t+2} + \gamma^2 v_{\pi}(S_{t+2}) \mid S_t = s] \ (\because \text{Tower Property})\\ & ... \\ & \le \mathbb{E}_{\pi'}[R_{t+1}+\gamma R_{t+2}+ \gamma^2 R_{t+3}+ ... \mid S_t = s] \\ & = v_{\pi'}(s) \end{align}\]결국에 $q_{\pi}(s, \pi’(s)) \ge q_{\pi}(s, \pi(s)) = v_{\pi}(s)$ 조건이 성립한다면 새로운 정책 $\pi’$에 대해 $v_{\pi’}(s) \ge v_{\pi}(s)$가 성립한다는 것이 당연해진다. 위 식의 전개 과정에서 Tower Property가 쓰였다. 이에 대한 것은 Tower Property 정리에 따로 정리해두었다.
그렇다면, 새로운 Policy는 어떻게 만들 수 있을까? 이는 앞에서 설명한 것처럼 기존 정책 $\pi$를 따랐을 때의 Value function을 바탕으로 가장 좋은 가치를 가질 수 있도록 하는 Greedy Policy를 찾으면 된다.
\[\begin{align} \pi'(s) & \doteq \underset{a}{\arg\max} q_{\pi}(s, a) \\ & = \underset{a}{\arg\max} \sum_{r \in \mathcal R} \sum_{s' \in \mathcal S}P(s', r \mid s, a) \{r + \gamma v_{\pi}(s')\} \end{align}\]결국 위와 같은 Greedy Policy를 설정하게 되면 앞에서 본 Policy Improvement Theorem이 자동으로 성립되기 때문에 기존 정책의 가치함수에 대해 Greedy가 되게 함으로써 기존 정책을 향상시키는 과정을 정책향상(Policy Improvement)이라고 부른다. 정책 향상 이후에 새롭게 생성된 정책 $\pi’$의 가치함수에 대해서 아래와 같은 수식이 성립한다고 가정하자.
\[\begin{align} v_{\pi'}(s) & = \max_{a}\,\mathbb{E}\!\left[ R_{t+1} + \gamma v_{\pi'}(S_{t+1}) \,\middle|\, S_t = s,\ A_t = a \right] \\ & = \max_{a}\,\sum_{s',\,r} p(s',r \mid s,a)\,\bigl[ r + \gamma v_{\pi'}(s') \bigr]. \end{align}\]위와 같은 식이 성립하면 더이상 정책 향상이 이루어지지는 않지만, 위 식 자체로 Bellman Optimality Equation이기 때문에 최상의 결과를 의미한다. 위와 같은 과정은 Deterministic Policy가 아닌 Stochastic Policy에 대해서도 동일하게 성립한다는 점을 기억해야 한다.
4.3 Policy Iteration
\[\pi_{0}\xrightarrow{\mathrm{E}} v_{\pi_{0}} \xrightarrow{\mathrm{I}} \pi_{1} \xrightarrow{\mathrm{E}} v_{\pi_{1}} \xrightarrow{\mathrm{I}} \pi_{2} \xrightarrow{\mathrm{E}} \cdots \xrightarrow{\mathrm{I}} \pi_{*} \xrightarrow{\mathrm{E}} v_{*},\]위에서 본 Policy Evaluation을 통해서 policy $\pi$에 대한 가치함수를 찾고, 해당 $\pi$를 개선시키기 위해서 policy Improvement를 진행하다보면, 최적 정책으로 수렴하게 된다. 이 과정을 정책반복(Policy Iteration) 이라고 부른다. 일반적으로 최적 Policy를 찾는다고 해서 해당 Policy에 대한 Value function이 크게 차이가 나지 않기 때문에 각 $E/I$ 단계의 속도는 점차 증가하는 양상을 보인다.
\[\begin{array}{l} \textbf{1. Initialization}\\ \quad V(s)\in\mathbb{R}\ \text{and}\ \pi(s)\in\mathcal{A}(s)\ \text{arbitrarily for all}\ s\in\mathcal{S}\\[6pt] \textbf{2. Policy Evaluation}\\ \quad \textbf{Repeat}\\ \quad\quad \Delta \leftarrow 0\\ \quad\quad \textbf{For each}\ s\in\mathcal{S}:\\ \quad\quad\quad v \leftarrow V(s)\\ \quad\quad\quad V(s) \leftarrow \sum_{s',\,r} p(s',r\mid s,\pi(s))\,[\,r+\gamma V(s')\,]\\ \quad\quad\quad \Delta \leftarrow \max\big(\Delta,\lvert v - V(s)\rvert\big)\\ \quad \textbf{until}\ \Delta < \theta\ \ (\text{a small positive number})\\[6pt] \textbf{3. Policy Improvement}\\ \quad policy\mbox{-}stable \leftarrow \textit{true}\\ \quad \textbf{For each}\ s\in\mathcal{S}:\\ \quad\quad a \leftarrow \pi(s)\\ \quad\quad \pi(s) \leftarrow \arg\max_{a}\ \sum_{s',\,r} p(s',r\mid s,a)\,[\,r+\gamma V(s')\,]\\ \quad\quad \textbf{If}\ a \neq \pi(s),\ \textbf{then}\ policy\mbox{-}stable \leftarrow \textit{false}\\ \quad \textbf{If}\ policy\mbox{-}stable,\ \textbf{then stop and return}\ V\ \text{and}\ \pi;\ \textbf{else go to 2} \end{array}\]앞서 봤듯이 Evaluation 과정에서 일정 수준 이하의 차이만을 보인다면 수렴으로 간주하고, Improvement 과정에서는 하나라도 바뀌는 state가 없다면 Optimal Policy이기 때문에 iteration을 중단한다.
4.4 Value Iteration
실제로 Policy Evaluation을 끝까지 진행하고 Policy Improvement를 진행하면 시간이 굉장히 오래 걸린다. 사실 Policy Evaluation을 끝까지 진행하지 않아도 수렴할 수 있다. 특수한 경우로 Value Iteration이라고 부른다. Policy Evaluation step을 한번만 밟고 바로 Improvement를 진행하는 과정이다.
Value Iteration의 식을 자세히 살펴보면 그냥 Bellman Optimality Equation을 update 식으로 변형한 형태로 생각할 수 있다. 각 state에서 얻을 수 있는 최대한의 가치를 가지고 Update해 나가는 과정으로 별도의 Policy Improvement 과정이 필요하지 않다.
\[\begin{align} v_{k+1}(s) & = \max_{a}\,\mathbb{E}\!\left[ R_{t+1} + \gamma v_{k}(S_{t+1}) \,\middle|\, S_t=s,\ A_t=a \right] \\ & = \max_{a}\,\sum_{s',\,r} p(s',r\mid s,a)\,\bigl[\, r + \gamma v_{k}(s') \,\bigr], \end{align}\]Value Function에 대해서만 Bellman Optimality Equation으로 업데이트를 진행하고, 별다른 policy는 구하지 않는다. 따라서 최종적인 결과는 Optimal Value Function을 만들어내고, 위 Optimal Value Function을 바탕으로 Optimal Policy를 생성해낸다. 위 과정은 아래 알고리즘 표로 표현할 수 있다.
\[\begin{array}{l} \textbf{Initialize}~\text{array}~V~\text{arbitrarily}~(\text{e.g., }V(s)=0~\text{for all }s\in\mathcal{S}^{+})\\[6pt] \textbf{Repeat}\\ \quad \Delta \leftarrow 0\\ \quad \textbf{For each } s\in\mathcal{S}:\\ \quad\quad v \leftarrow V(s)\\ \quad\quad V(s) \leftarrow \max_{a}\ \sum_{s',\,r} p(s',r\mid s,a)\,[\,r+\gamma V(s')\,]\\ \quad\quad \Delta \leftarrow \max\big(\Delta,\lvert v - V(s)\rvert\big)\\ \textbf{until } \Delta < \theta\ (\text{a small positive number})\\[10pt] \textbf{Output}~\text{a deterministic policy, } \pi,\ \text{such that}\\ \quad \pi(s) = \arg\max_{a}\ \sum_{s',\,r} p(s',r\mid s,a)\,[\,r+\gamma V(s')\,] \end{array}\]4.5 Asynchronous Dynamic Programming
DP의 가장 큰 문제점은 물론 MDP 성질을 모두 알아야 한다는 점이지만, 더 중요한 것이 바로 연산량이다. 모든 state와 action들에 대해서 Update를 계속해서 진행해 나가야 하기 때문에, 한번 sweep에도 굉장히 많은 연산이 필요하다.
Asynchronous DP 알고리즘은 Sweep 순서는 상관없이 개별적으로 Update하는 과정을 거치는 알고리즘이다. 갱신순서도 정해진 것이 없이 그냥 가능한 Update가 존재하면 바로 업데이트를 하는 방식으로 진행되며, 갱신대상도 $k$, $k+1$과 같이 sweep step이 정해진 것이 아니기 때문에 Single Array를 사용하여 Value Function을 기록하는 과정을 거친다. 이 비동기 DP에서 중요한 것은 모든 State에 대한 Update를 진행해야 한다는 점이다. 처음에는 특정 State에 대한 Update만 진행하더라도, 최종적인 Value Function으로 수렴하기 위해서는 모든 State에 대한 Update가 필수적이다.
Asynchronous DP은 굉장히 유연한 알고리즘으로, 심지어 Policy Evaluation 과정과 Value Iteration 과정을 섞어서 중단된 Policy Iteration 등으로 바꿔버릴 수 있는 알고리즘이다.
Asynchronous DP를 사용하면 계산량을 줄일 수 있다는 보장은 없다. 다만, 최적 행동과 관련이 없는 State에 대한 Update를 건너뛰거나 갱신의 순서를 마음대로 조정할 수 있다는 장점이 있다. 추가적으로 Asynchronous DP를 통해서 Online Learning이 가능해지는데, State Set 중에서 가장 관련 있는 State에 대해서만 초점을 맞추어 학습이 가능해진다.
4.6 Generalized Policy Iteration (GPI)
앞에서 다룬 알고리즘들을 정리하면 아래와 같다.
Policy Evaluation: Value function이 Policy를 따르도록 계속해서 UpdatePolicy Improvement: Policy가 Value function에 대해서 Greedy하도록 UpdateValue Iteration: Policy Evaluation 한 단게 이후, Policy ImprovementAsynchronous DP: Evaluation과 Improvement가 더 촘촘하게 반복된다.
따라서 정책 평가나 정책 향상의 주기에 관련없이 서로 상호작용하는 과정을 거치게 되는데, 이를 통합적으로 표현하기 위해서 Generalized Policy Iteration이라는 통합적 명칭으로 부른다.
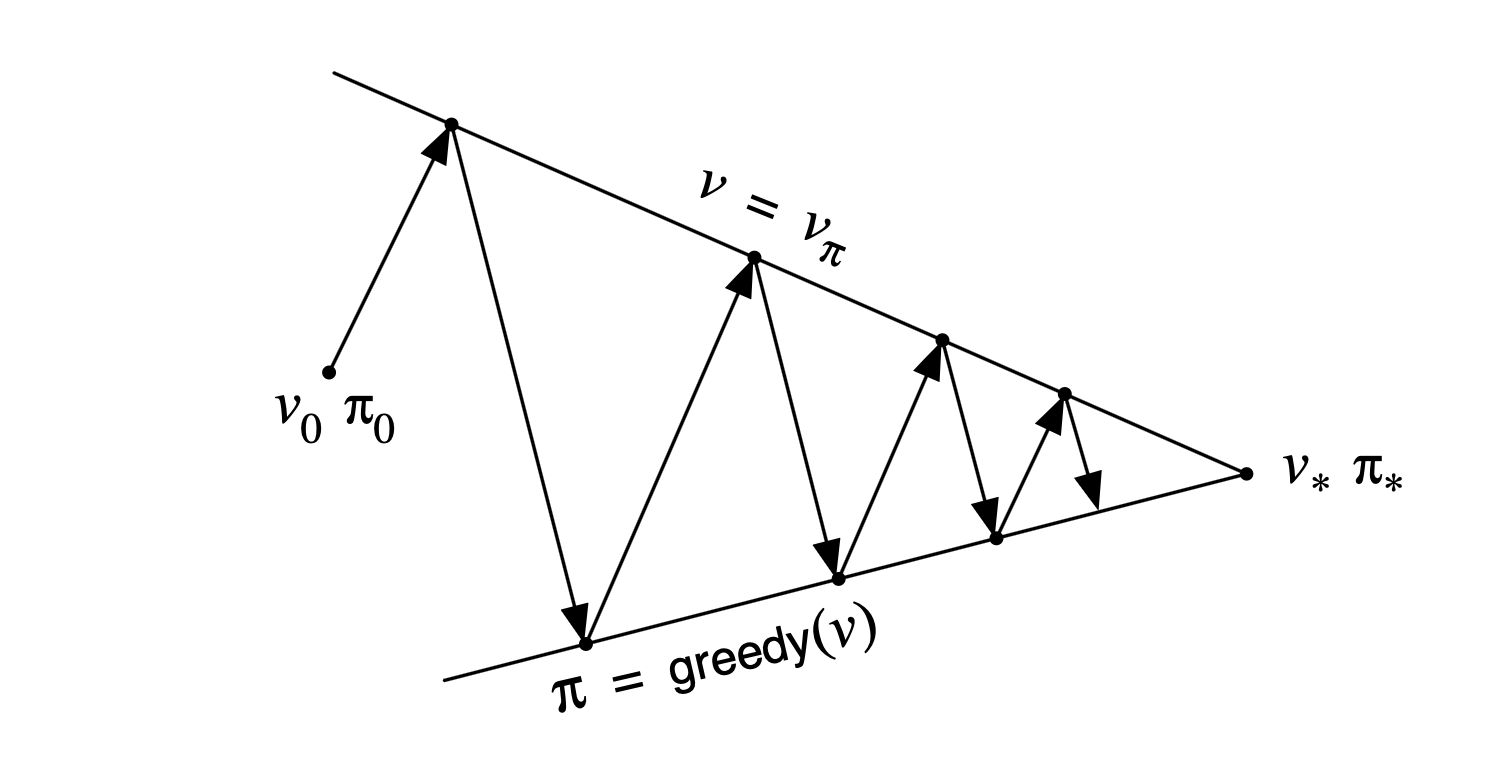
위 다이어그램을 통해서 더 정확하게 이해할 수 있다.
Value FunctiondlPolicy를 따르도록 만들면 Policy가 부정확해지고,Policy가Value Function을 따르도록 만들면 Value function이 부정확해진다. 위 상호작용이 계속해서 일어나 최종적으로 최적 가치함수와 최적 정책을 찾게 된다.- 혹은
Value Function과Policy가 서로 상호보완적으로 최종적인 $v_\star$나 $\pi_\star$에 가까이 가도록 하는 것으로 이해할 수 있다.
GPI는 DP뿐만 아니라, MC, TD와 같은 과정에서도 Control 문제를 풀기 위한 근간이 된다.
4.7 Efficiency of Dynamic Programming
DP는 규모가 매우 큰 문제에 대해서 모든 State와 Action을 다루어야 하기 때문에 비효율적으로 보일 수 있다. 하지만 DP는 상태가 $n$개이고, Action이 $d$개인 문제에 대해서 Deterministic Policy $d^n$개 중 하나를 결정하는 문제에 대해 Polynomial Time Bound 안에 처리할 수 있다. 이는 다항식을 직접 푸는 방법보다 훨씩 효율적이로 동작한다.
추가적으로 State/Action의 변수의 개수에 따라서 처리해야 하는 연산량이 굉장히 많아지는 차원의 저주는 문제 자체의 어려움이지 DP의 어려움은 아니다. 오히려 Brute-Force Search나 Linear Programming보다 더 효율적인 알고리즘으로 문제를 풀 수 있다.
Policy Iteration 방법이나 Value Iteration 방법 중 무엇이 효율적인지는 문제에 따라 다르다. 추가적으로 State 개수가 굉장히 많은 경우라면 Async DP가 훨씬 더 효율적이다. 다음 장부터는 DP를 사용하지 않고 비슷한 성능을 낼 수 있도록 하는 MC나 TD에 대해서 공부할 것이다.