Chapter 5. Monte Carlo Methods
이번 장에서는 Value function을 찾고 최적 Policy를 찾는 첫번째 방법인 MC 방법론을 다룬다. DP 방법론이 MDP의 완전한 성질을 알아야 진행이 가능했던 것과 다르게, MC 방법은 $S_{t}, A_t, R_{t+1}$로 이루어진 경험들의 집합들만 필요하다. 즉, 한 상태에서 다른 상태로의 전이를 완벽하게 알 필요가 없이 본인이 경험한 것들로 학습이 가능하다는 장점이 있다.
이를 위해서 MC방법론은 Sample Return의 표본평균을 직접적으로 Value Function에 활용하기 때문에 MC에서 다루는 방법들은 전부 Episodic Task이다. Sample Return의 표본평균을 직접 활용하는 방식을 Chapter 2에서 살펴본 Multi armed Bandit과도 비교해볼 수 있다. 다만 Bandit 문제에서는 Return이 아닌 Reward를 바탕으로 Exploration / Exploitation을 구분했고, MC에서는 Return의 분포가 Nonstationary하고, State나 Action이 하나가 아닌 차이점이 있다.
정리해보자면, DP에서는 Model을 통해서 Value Function을 연산한다는 의미가 있지만, MC에서는 Value Function을 학습한다는 점에서 차이점이 존재한다. 다만 Value Function과 Policy가 서로 상호작용하며 최적의 Policy를 찾아간다는 점에서는 동일하다.
5.1 MC Prediction
5.1.1 MC Prediction (Every vs First)
Prediction(Value function 구하기) 문제를 먼저 생각해보자. $v_{\pi}(s)$를 구하기 위해서 State s를 방문한 경우에 Return의 값을 계속해서 수집하여 평균을 구하는 방법으로 동작할 것이다. 다만, Value function을 count하는 경우는 2가지가 존재하는데, 각각 Every-Visit MC와 First-Visit MC를 의미한다.
Every Visit MC는 단순하게 이전에 기댓값을 Update하던 방식에서 차용하여 $N(s)$를 State s를 방문한 횟수, $G_t$를 하나의 Return값, 그리고 추정하는 State s의 가치를 $V(s)$라고 가정했을 때, 아래와 같이 간단하게 표현할 수 있을 것이다.
\[\begin{array}{l} \textbf{Initialize:}\\ \quad \pi \leftarrow \text{policy to be evaluated}\\ \quad V \leftarrow \text{an arbitrary state-value function}\\ \quad N(s) \leftarrow \text{the number of State s visited}\\ \quad \forall s, N(s) \leftarrow 0 \\[6pt] \textbf{Repeat forever:}\\ \quad \text{Generate an episode using } \pi\\ \quad \textbf{For each occurence of } s\\ \quad\quad G_t \leftarrow \text{return following the occurrence of } s\\ \quad\quad N(s) \leftarrow N(s) + 1 \\ \quad\quad V(s) \leftarrow V(s) + \frac{1}{N(s)} \{G_t - V(s)\} \end{array}\]다만, First Visit MC를 사용하는 경우에는 Trajectory 상에서 이전 time step에 내가 원하는 state가 존재하지 않는다면 Update를 진행해나가는 방식을 사용해야 하므로, 아래와 같은 알고리즘으로 동작한다.
\[\begin{array}{l} \textbf{Initialize:}\\ \quad \pi \leftarrow \text{policy to be evaluated}\\ \quad V \leftarrow \text{an arbitrary state-value function}\\ \quad N(s) \leftarrow \text{the number of State s visited}\\ \quad \forall s, N(s) \leftarrow 0 \\[6pt] \textbf{Repeat forever:}\\ \quad \text{Generate an episode using } \pi\\ \quad \textbf{For each state } s \textbf{ appearing in the episode}\\ \quad\quad G_t \leftarrow \text{return following the first occurrence of } s\\ \quad\quad N(s) \leftarrow N(s) + 1 \\ \quad\quad V(s) \leftarrow V(s) + \frac{1}{N(s)} \{G_t - V(s)\} \end{array}\]두 MC 방법 모두 표본의 수가 무한히 많아진다면 수렴성을 보장할 수 있다.
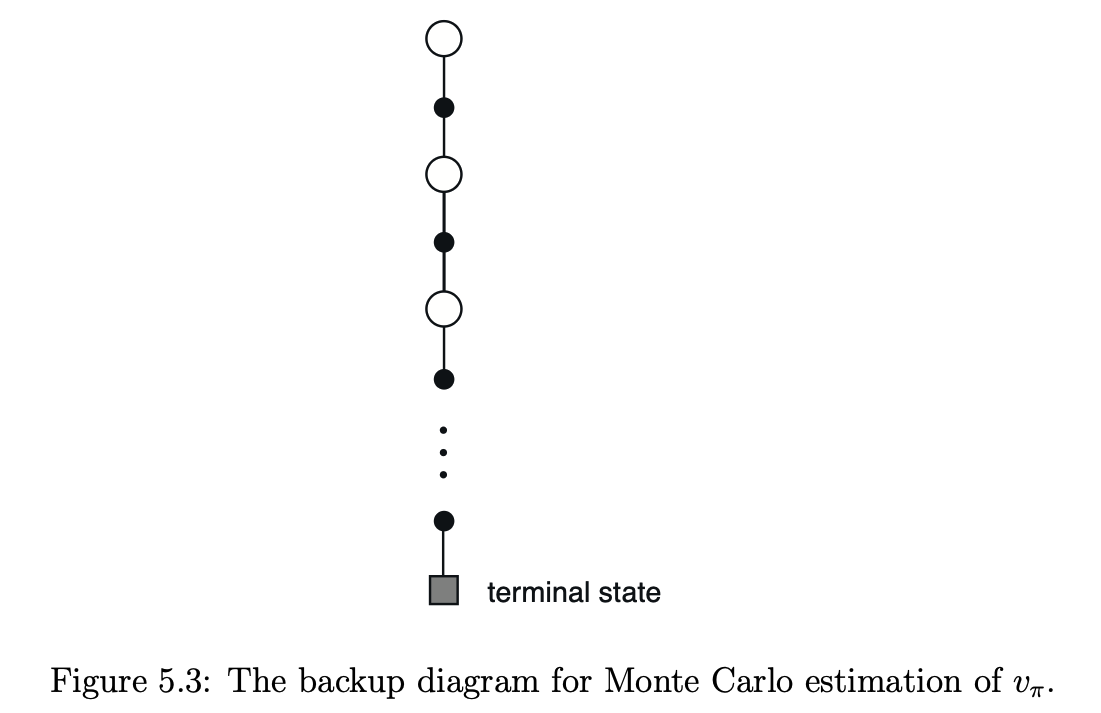
MC의 Backup Diagram을 그려보면 아래와 같을 것이다. Agent가 경험한 Trajectory만을 참조할 수 있기에 이런 한 Sequence로 된 Diagram이 그려진다.
5.1.2 BlackJack Example
우리가 흔히 아는 BlackJack Example을 활용하여 MC와 DP의 차이점을 더 확실하게 알 수 있다. 생각해 볼 지점을 크게 3가지이다. (BlackJack 문제에 대해서는 굳이 자세하게 설명하지 않겠다.)
A. Enviroment Dynamic을 확실하게 알 수 있는가?
환경의 동역학을 알고 있다는 의미는 Finite MDP를 기준으로만 해도 모든 state, reward, action 쌍들에 대해서 $P(s’, r \mid s, a)$를 전부 완벽하게 알고 있다는 것을 의미한다. 이는 미래에 대한 모든 정보를 알고 있어야 하므로, 실제로 이를 근사하는 방법을 사용해도 오히려 오차만 키우는 불상사가 발생할 수 있다.
다만 DP가 아닌 MC를 사용하는 경우, 위와 같은 자세한 정보는 필요가 없다. 경험을 토대로 Bias가 없는 정확한 Return 정보만을 사용하기 때문에 바로 Value function을 학습하는 것이 가능하고, DP에서 사용한 기댓값을 활용하여 기댓값을 Update하는 Bootstrapping 방법을 사용하지 않는다는 것이 특징이다.
B. Curse of Dimension 문제를 해결할 수 있는가?
DP 방법론을 적용하려면 순서에 차이는 있겠지만 결국 Bootstrap 방식을 사용하는 것이기 때문에, 모든 State에 대한 Value function이 필요하다는 것은 변하지 않는다. 다만 MC 방법론은 위에서 언급했듯이 완전한 Return만을 사용하여 Update를 진행하므로 필요에 따라서는 내가 원하는 State에 대해서만 정확한 Value function을 구하는 것이 가능하다.
따라서 MDP의 정보를 전부 알고 있는 경우라도 MC 방법을 사용하면 Target state에 대한 연산만 집중할 수 있다는 장점도 있다.
C. Exploration vs Exploitation
결국 MC의 정의를 다시 한번 떠올려보면, 경험을 통한 Value 구하기였다. 따라서 내가 경험하지 않은 State나 Action에 대해서는 Update하지 못하는 것이 당연하다. 이 기점에서 어떤 경험을 할 것인지를 결정하는 것이 중요해진다. 내가 현재 최상의 결과를 낸다고 알고 있는 행동을 계속 지속할 것인지, 혹시 모를 더 좋은 결과를 위해서 탐험적 행동을 할 것인지 결정하는 딜레마에 빠지게 된다.
5.2 Monte Carlo Estimation of Action Values
DP에서 보면 $v(s)$ 정보를 알면 $q(s, a)$에 대한 정보도 바로 구할 수 있기 때문에 Action Value Function을 바로 구하는 것이 반드시 필요한 과정은 아니다. 하지만, MC 방법에서는 둘을 연결할 수 있는 방법이 없기 때문에 결국 $v(s)$를 점증적으로 구해 나갔던 것과 유사하게 $q(s, a) \leftarrow q(s, a) + \frac{1}{N(s, a)}{G_t - q(s,a)}$ 형태로 업데이트 해나가면 된다.
하지만 앞서 언급했던 것처럼 MC는 경험에 기반한 방법론이기 때문에 직접 경험하지 않은 것들에 대한 정확한 판단이 불가능하다. 따라서 탐험을 계속해서 진행시킬 수 있는 장치가 분명히 필요하다. 책에서는 이 과정을 해결하는 데에 2가지 방법을 제안한다. 첫번째가 Exploring Starts이고 두 번째가 Stochastic Policy이다.
Exploring Starts는 각 첫번째 (State, Action) pair로 선택될 확률을 모두 0이 아니도록 설정하여 계속해서 모든 조합에 대한 Value Function을 구해 나가겠다는 의미이다. 다만 이 가정은 실험용으로만 의미가 있는 가정이다. 실제로 시작 지점은 어떤 실험 상황이나 정책에 따라서 집중되어 있는 것이 맞고 실제 상호작용에서는 불가능한 가정일 경우가 많다.
Markov Property가 성립하기 때문에 언제 State s가 오든지 상관이 없다고 생각할 수 있지만, 해당 State를 어떻게 얼마나 자주 등장할 수 있도록 하는지는 별개의 문제이다.
Stochastic Policy를 사용하는 방법은 결정론적 정책이 아닌 모든 Action을 선택할 Prob를 0보다 큰 값으로 설정하면서 Episode가 많아짐에 따라서 비최적행동에 대한 Value도 정확하게 연산할 수 있도록 하는 것이다. ($\epsilon$-greedy, GLIE)
5.3 Monte Carlo Control
5.3.1 MC + GPI
MC에서 Control 문제를 어떻게 해결하는지 살펴보자. 기본적으로 4장에서 살펴본 Generalized Policy Iteration과 동일한 기조로 진행된다. 불완전한 Value Function과 Policy가 서로 상호작용하면서 Optimal 값들을 찾아가는 방식으로 진행된다.
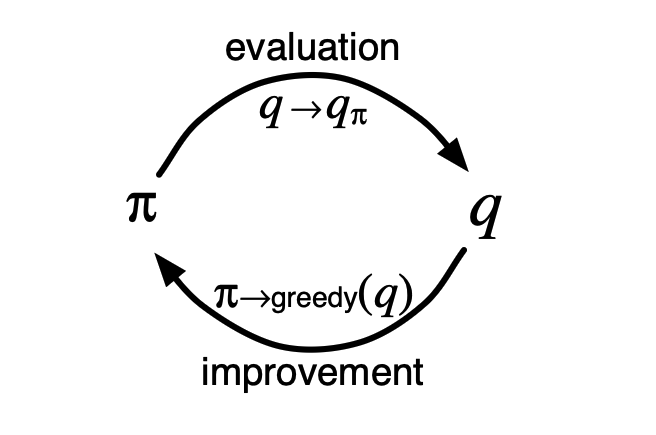
먼저 진행을 위해서 Agent가 Infinite Episode 관찰과 Exploring Start를 사용한다고 가정한다.
위와 같은 E/I의 연속적인 반복을 통해서 결국에 최적의 Value Function과 Policy를 생성할 수 있다. Evaluation 과정은 표본의 개수가 늘어남에 따라서 정확한 값으로 수렴한다는 것을 통해 쉽게 알 수 있다. Improvement 또한 이전에 진행했던 것과 동일하게 현재 State에서 할 수 있는 가장 좋은 Action을 파악하는 것이 목표인데, 이전 장에서 진행했던 것과 동일하게 새롭게 찾은 Policy $\pi’$가 실제로 기존의 $\pi$보다 좋은 결과를 나타낼 수 있다는 점을 보일 수 있다.
\[\begin{aligned} q_{\pi_k}\!\bigl(s,\pi_{k+1}(s)\bigr) &= q_{\pi_k}\!\left(s,\arg\max_{a}\, q_{\pi_k}(s,a)\right)\\ &= \max_{a}\, q_{\pi_k}(s,a)\\ &\ge q_{\pi_k}\!\bigl(s,\pi_k(s)\bigr)\\ &= v_{\pi_k}(s). \end{aligned}\]5.3.2 Monte Carlo ES
이제 앞선 가정을 상쇄할 수 있는 방법에 대해서 생각해보겠다. 먼저 Infinite Episode를 가정했었는데, 실제로 무한히 많은 에피소드를 사용하는 것은 불가능하다. 이 가정을 상쇄할 수 있는 방법은 크게 두가지인데, 먼저 충분한 과정을 거쳐서 일정한 오차범위보다 작아지도록 하는 것이다. 이 방법은 현실적으로 매우 큰 연산량을 필요로 한다. 두번째 방법으로는 완전한 Evaluation 과정을 거치지 않는 것이다. 기존 DP 방법론을 기준으로 보면 Value Iteration이나 Async Sweep등등을 진행해도 최적 정책으로 수렴하는 것이 가능하기 때문에 MC에도 비슷한 과정을 거쳐도 된다. 두번째 방법을 적용한 것이 Monte-Carlo ES 방법이다.
Monte-Carlo ES 방법은 Episode마다 Evaluation과 Improvement를 반복하는 과정이다. 다만 ES는 Exploring Start를 의미하기 때문에 이에 대한 의사 코드를 아래와 같이 표현할 수 있다.
다만, 위 Monte Carlo ES 방법은 완전히 수렴한다는 것은 증명되지 않았지만, Value Iteration과 마찬가지로 Value function과 Policy가 서로 상보적으로 동작하고, 점점 Q Function의 변화량이 줄어듦에 따라서 최적 정책으로의 수렴이 가능하다고 본다.
5.4 Monte Carlo Control without Exploring Starts
위 5.3 절에서 MC Control을 설명하기 위해서 비현실적인 가정 2가지를 진행했다. Infinite Episode문제는 현실적으로 2가지 방안으로 해결했었다. 이제 남은 Exploring Start문제를 해결하는 방법에 대해서 파악해야 한다. 근본적으로 Exploring Start를 사용하지 않으려면 Agent가 모든 행동을 계속해서 사용할 수 있도록 해야 한다.
이를 가능하게 해주는 것이 On-policy방법과 Off-policy방법이다. On-policy방법은 Agent가 Evaluation과 Improvement를 진행하는 정책과 데이터를 생성하는 정책이 동일한 Policy를 기준으로 진행하는 것이고, Off-policy방법은 E/I를 진행하는 정책과 데이터를 생성하는 정책이 다른 경우이다. 이 절에서는 먼저 On-policy 방법을 사용하여 ES를 제거하는 방법에 대해서 다룬다.
On-Policy에서 다루는 Policy들은 대부분 Soft하다는 가정을 가진다. 모든 Action에 대해서 $\pi(a \mid s) \gt 0$을 만족하면서 점진적으로 Deterministic한 정책으로 진행하는 정책을 Soft하다고 한다.
이전에 살펴 본 Policy 중에서 $\varepsilon$-greedy 정책이 이 Soft하다고 볼 수 있다. 엡실론 그리디 정책은 아래와 같이 정리될 수 있다.
MC ES에서는 GPI를 사용하여 Policy Improvement를 진행했다. 이때 Greedy Policy를 사용했었는데, GPI에서는 실제로 꼭 Greedy할 필요는 없고, Greedy한 방향으로 진행하기만 하면 된다. 즉 $\varepsilon$-greedy Policy를 사용해도 된다는 의미인데, $\varepsilon$-soft한 Policy $\pi$의 Value Function을 $q_{\pi}$라고 했을 때, 해당 Value function에 대한 $\varepsilon$-greedy Policy가 항상 $\pi$보다 좋거나 같다는 것이 보장되기 때문이다.
아래는 동일한 $q_{\pi}$에 관한 엡실론 소프트 정책 $\pi$과 엡실론 그리디 정책 $\pi’$에 대해서 정책 $\pi’$를 따르는 경우의 가치가 더 높다는 것을 Policy Improvement Theorem으로 증명할 수 있다.
\[\begin{aligned} q_{\pi}\!\bigl(s,\pi'(s)\bigr) &= \sum_{a}\pi'(a\mid s)\,q_{\pi}(s,a)\\ &= \frac{\varepsilon}{|\mathcal{A}(s)|}\sum_{a} q_{\pi}(s,a)\;+\;(1-\varepsilon)\max_{a} q_{\pi}(s,a)\\ &\ge \frac{\varepsilon}{|\mathcal{A}(s)|}\sum_{a} q_{\pi}(s,a)\;+\;(1-\varepsilon)\sum_{a} \frac{\pi(a\mid s)-\frac{\varepsilon}{|\mathcal{A}(s)|}}{1-\varepsilon}\,q_{\pi}(s,a)\\ &= \frac{\varepsilon}{|\mathcal{A}(s)|}\sum_{a} q_{\pi}(s,a)\;-\;\frac{\varepsilon}{|\mathcal{A}(s)|}\sum_{a} q_{\pi}(s,a)\;+\;\sum_{a}\pi(a\mid s)\,q_{\pi}(s,a)\\ &= v_{\pi}(s).\\ & \therefore v_{\pi'}(s) \ge v_{\pi}(s) \end{aligned}\]또한 책의 증명 과정을 통해서 결국 단조 증가하는 과정을 거치다가 수렴하게 된다면 해당 수렴 지점이 엡실론 소프트를 따를 때의 최적 정책임을 확인할 수 있다. 따라서 입실론 소프트 정책, 그 중에서 엡실론 그리디 정책을 사용하여 Policy Improvement를 한다면 결과적으로 엡실론 소프트 정책을 사용했을 때의 최적 정책으로 수렴할 수 있다는 것을 보였다. 이를 통해서 비현실적인 Exploring Starts가정을 제거할 수 있게 되었다. 따라서 On-Policy Control 문제를 ES 없이 해결하는 알고리즘은 아래와 같다. ES 조건만 제거한 것이고 Episode 단위로 Update하는 과정은 유지한다.
\[\begin{array}{l} \textbf{Initialize, for all } s\in\mathcal{S},\ a\in\mathcal{A}(s):\\ \qquad Q(s,a)\leftarrow \text{arbitrary}\\ \qquad \forall s, a \quad N(s, a) \leftarrow 0 \\ \qquad \pi(a\mid s)\leftarrow \text{an arbitrary }\varepsilon\text{-soft policy}\\[6pt] \textbf{Repeat forever:}\\ \qquad\text{(a) Generate an episode using }\pi\\ \qquad\text{(b) For each pair }(s,a)\text{ appearing in the episode:}\\ \qquad\qquad G \leftarrow \text{return following the first occurrence of }(s,a)\\ \qquad\qquad N(s, a) \leftarrow N(s, a) + 1\\ \qquad\qquad Q(s,a) \leftarrow Q(s, a) + \frac{1}{N(s, a)} \{G - Q(s, a)\}\\ \qquad\text{(c) For each }s\text{ in the episode:}\\ \qquad\qquad a^* \leftarrow \arg\max_{a} Q(s,a)\\ \qquad\qquad \text{For all }a\in\mathcal{A}(s):\\ \qquad\qquad\qquad \pi(a\mid s)\leftarrow \begin{cases} 1-\varepsilon+\dfrac{\varepsilon}{|\mathcal{A}(s)|}, & a=a^*,\\[6pt] \dfrac{\varepsilon}{|\mathcal{A}(s)|}, & a\neq a^*. \end{cases} \end{array}\]다만, 이는 완전한 Optimal Policy가 아니라 Epsilon Soft 가정 하에서의 Optimal Policy라는 점에 주의해야 한다. 완전한 Optimal Policy를 위해서는 GLIE(Greedy in the Limit with Infinite Exploration) 와 같은 특수한 방법론을 사용해야 한다. 이는 간단히 말해서 time step $t$가 증가함에 따라서 엡실론의 값이 점점 0으로 다가가는 경우를 의미한다.
\[\varepsilon_t = \frac{1}{t}\]5.5 Off-Policy Prediction via Importance Sampling
5.5.1 Target Policy vs Behavior Policy
Control 과정에서의 문제점은 Optimal Action에 따라서 Value를 학습하길 원하지만, Optimal Action이 무엇인지 찾기 위해서 Optimal Action의 Value에 대한 학습을 포기해야 한다는 점이다. 이에 대한 답은 On-Policy로 처리하려는 경우 Near-Optimal Policy를 사용하여 탐험과 학습 사이의 적절한 조화를 이루어 낼 수도 있을 것이다. 하지만 Off-Policy로 서로 다른 Policy를 바탕으로 데이터 생성과 학습을 진행할 수 있다.
Off-Policy방법은 크게 2가지의 Policy를 사용한다. 먼저 최적 정책에 해당하는 Target Policy가 있고, 행동 생성을 위해서 Target Policy와는 다른 Behavior Policy가 존재한다. 어떻게 보면 On-Policy가 Off-Policy의 특수한 경우로 이해할 수 있을 것이다. Behavior Policy == Target Policy인 특수한 경우를 만족하는 경우가 이에 해당한다.
먼저 Prediction 문제와 Control 문제를 다시 정리해보면, Prediction문제는 제공된 Policy $\pi$를 기반으로 $v_{\pi}$나 $q_{\pi}$를 찾아나가는 문제이고, Control 문제는 최적 정책을 찾는 문제이다. 일반적으로 Control 문제에 Prediction 문제가 함께 들어있는 경우가 대부분이다. 먼저 Off-Policy에서의 Value function을 찾는 과정인 Prediction 문제에 대해서 다루게 된다.
이 책에서는 Target Policy를 $\pi$로, Behaivor Policy를 $\mu$로 잡고 설명한다. Target Policy에 대해서 가능한 행동에 대해서 Behaivor Policy 또한 행동할 수 있어야 하기 때문에 $\pi(a \mid s) \gt 0$인 Action에 대해서 $\mu(a \mid s ) \gt 0$을 만족시켜야 한다. 이를 Assumption of Coverage라고 부른다. 다시 말해서 Target Policy와 Behaivor Policy가 같지 않아야 한다는 조건이 있다면, Behavior Policy는 반드시 Stochastic Policy가 되어야 한다. (Target이 Deterministic해도 동일하면 안되기 때문에 최소한 0 이상의 확률을 가지는 행동이 2개 이상은 존재하기 때문이다.)
따라서 정리해보자면 Behavior Policy의 경우에는 언제나 확률론적인 정책을 사용해야 한다. Target Policy의 경우에는 확률론적 정책과 결정론적 정책 모두 사용이 가능하지만, 대부분 현재 Value function에 대해서 탐욕적인 정책을 사용하게 된다. 따라서 $\pi$로는 Greedy Policy, $\mu$로는 $\varepsilon$-Greedy Policy를 사용하는 것이 대부분이다.
5.5.2 Importance Sampling
Importance Sampling 이라는 것은 다른 분포의 기댓값을 통해서 내가 원하는 분포의 기댓값을 연산하는 기술을 의미한다. Off-Policy Learning에서는 Trajectory에 대한 상대적인 확률을 사용하여 Return 값을 가중시키는 방법으로 적용한다. 이때 사용하는 상대적인 확률이라는 것이 Importance-Sampling Ratio이다. $A_t, S_{t+1}, A_{t+1}, …$ 등의 Trajectory에 대한 발생 확률은 아래와 같이 정의될 수 있다.
위 식에서 P로 주어진 확률은 Finite MDP에서의 동역학을 표현하는 바로 그 확률이다. 다만 해당확률은 어떤 정책을 따르던지 동일한 값을 가지는 것이 일반적이다(환경이 달라지지 않는다면). 따라서 Importance Sampling Ratio는 아래와 같이 표현할 수 있다.
\[\rho_t^{T} =\frac{\prod_{k=t}^{T-1}\pi(A_k\mid S_k)\,p(S_{k+1}\mid S_k,A_k)} {\prod_{k=t}^{T-1}\mu(A_k\mid S_k)\,p(S_{k+1}\mid S_k,A_k)} =\prod_{k=t}^{T-1}\frac{\pi(A_k\mid S_k)}{\mu(A_k\mid S_k)}.\]$\mu$정책 하에서의 이득의 기댓값을 $\mathbb{E}[G_t \mid S_t = s]$라고 한다면 $\pi$정책 하에서의 이득의 기댓값은 $\mathbb{E}[G_t \times \rho_{t : T-1} \mid S_t = s]$ 로 표현될 것이다. 추가적인 논의를 위해서 책에서는 아래의 가정을 사용한다.
Time Step유지 : 한 에피소드가 $t = 100$에서 끝났다면 다음 Episode의 첫 Timestep은 $101$.- $\mathcal{J}(s)$ : 상태 s를 마주하는 Timestep 집합
Every Visit MC의 경우 방문한 모든 Timestep을 저장Once Visit MC의 경우 처음의 Timestep만 저장
- $T(t)$: $t$ 시점 이후에 처음으로 Terminate한 시간을 의미함.
- ${G_t}_{t \in \mathcal{T}(s)}$ : s와 관련된 Return 집합을 의미함.
- ${\rho_t^{\,T(t)}}_{t \in \mathcal{T}(s)}$ : 각 Terminate할 때까지의 Importance Sampling Ratio를 의미.
그러면 $v_\pi(s)$를 최종적으로 추정하기 위해서는 결국 Importance Sampling Ratio와 Return 값의 곱에 대한 표본 평균을 구하는 것과 동일할 것이다. 다만, 이를 구하는 데는 2가지 방식이 존재한다.
A. Ordinary Importance Sampling (기본 중요도 추출법)
\[V(s)=\frac{\sum_{t\in\mathcal{T}(s)} \rho_t^{\,T(t)}\,G_t}{\lvert \mathcal{T}(s)\rvert }.\]위 수식은 앞서 생각한 것과 완전히 동일하게 일반적인 표본평균을 구하는 방법이다.
B. Weighted Importance Sampling (가중치 중요도 추출법)
\[V(s)=\frac{\sum_{t\in\mathcal{T}(s)} \rho_t^{\,T(t)}\,G_t}{\sum_{t\in\mathcal{T}(s)} \rho_t^{\,T(t)}}.\]위 수식은 가중치로 나누어 중요도를 추출하는 방법이다.
Ordinary와 Weighted 가중치 추출법은 사실 큰 차이가 존재한다. 마치 머신러닝의 Bias와 Variance와 마찬가지로 Bias의 유무와 Variance의 정도를 고려해야 한다. Weighted Importance Sampling의 경우 사실 $v_{\pi}$가 아닌 $v_{\mu}$를 구하는 과정이라고 볼 수 있기에 Bias가 존재한다. 하지만, Ordinary Importance Sampling의 경우에는 정의에 따라서 식이 구성되어 있기 때문에 Bias가 존재하지 않는다.
하지만 분산 관점에서 봤을 때 Ordinary 방법은 매우 취약하다. 사실 Importance Sampling Ratio로 Target과 Behavior의 상대적인 비율을 나타내었다고 하지만 이 값에 제약이 없기 때문에 Ratio가 굉장히 커지게 된다면 비현실적인 Return을 가진다고 간주하게 될 것이다. 반면에 Weighted Sampling의 경우에는 전체의 합으로 분할하기 때문에 결국 $\rho$가 1로 Bound되었기 때문에 현실적인 Return을 다룰 수 있다. 사실 Return의 값이 Bounded되어 있다면 $\rho$의 분산이 무한대에 가깝더라도 실제 분산은 0에 가깝기 때문에 현실적으로는 Weighted Sampling이 더 선호된다.
5.5.3 Example - Infinite Variance
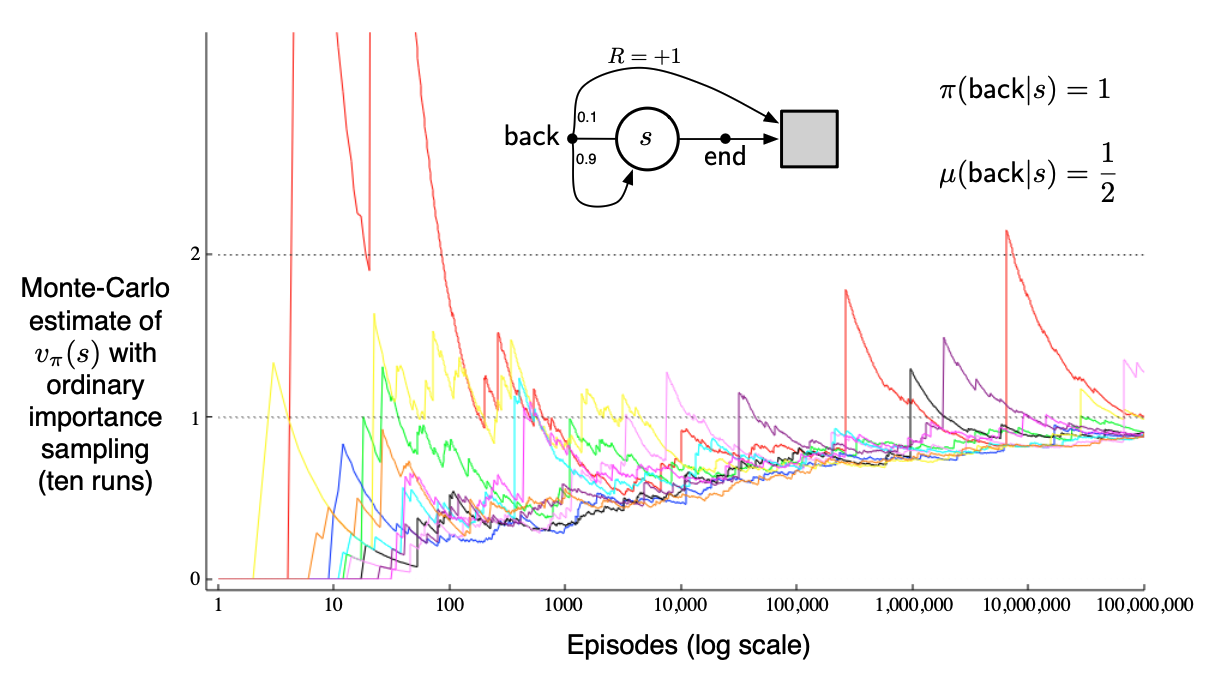
위 예시를 통해서 Ordinary와 Weighted의 차이를 확실하게 알 수 있다. 최종적으로 State $s$의 Value를 찾는 것이 목표이다. MC는 결국 경험을 통해서 Value를 점점 더 정확하게 파악할 수 있는 방법이기 때문에 Trajectory의 구조를 확인해보아야 한다. Behavior Policy $\mu$를 바탕으로 파악해보면, 아래와 같다.
- $\mu(end \mid s ) = \frac{1}{2}$의 확률로 Return이 0을 가지면서 종료
- $\mu(back \mid s) = \frac{1}{2}$의 확률로 Back
- $\frac{1}{2} \times 0.1 = \frac{1}{20}$의 확률로 Return 1을 가지면서 종료
- $\frac {1}{2} \times 0.9 = \frac{9}{20}$의 확률로 다시 State로 복귀
따라서 $\rho$를 생각해보면 아래와 같다.
- $\mu(end \mid s ) = \frac{1}{2} , \mu(end \mid s ) = 0$ 이기 때문에 무시해도 됨.
- $\rho_t^{T}=\prod_{k=t}^{T-1}\frac{\pi(A_k\mid S_k)}{\mu(A_k\mid S_k)}$를 만족하기 때문에 State로 복귀하는 경우가 많은 Episode인 경우 Ratio가 지수적으로 폭증하게 된다.
따라서 $\rho$의 분산을 아래와 같이 계산할 수 있고, 결과적으로 무한대로 발산함을 확인할 수 있다.
\[\operatorname{Var}[X] =\mathbb{E}\!\left[(X-\bar{X})^{2}\right] =\mathbb{E}\!\left[X^{2}-2X\bar{X}+\bar{X}^{2}\right] =\mathbb{E}[X^{2}]-\bar{X}^{2}.\] \[\begin{aligned} \mathbb{E}[( \prod_{t=0}^{T-1}\frac{\pi(A_t\mid S_t)}{\mu(A_t\mid S_t)}\,G_0)^{2} ] &=\frac{1}{2}\cdot 0.1\left(\frac{1}{0.5}\right)^{2} \qquad\text{(the length 1 episode)}\\[4pt] &\quad+\frac{1}{2}\cdot 0.9\cdot \frac{1}{2}\cdot 0.1 \left(\frac{1}{0.5}\frac{1}{0.5}\right)^{2} \qquad\text{(the length 2 episode)}\\[4pt] &\quad+\frac{1}{2}\cdot 0.9\cdot \frac{1}{2}\cdot 0.9\cdot \frac{1}{2}\cdot 0.1 \left(\frac{1}{0.5}\frac{1}{0.5}\frac{1}{0.5}\right)^{2} \qquad\text{(the length 3 episode)}\\ &\quad+\cdots\\[6pt] &=0.1\sum_{k=0}^{\infty} 0.9^{k}\cdot 2^{k}\cdot 2\\ &=0.2\sum_{k=0}^{\infty} 1.8^{k}\\ &=\infty. \end{aligned}\]따라서 Ordinary Importance Sampling을 사용한다면 위 분산의 폭증을 막지 못할 것이고, Weighted Importance Sampling이라면 분산을 상쇄하여 연산이 가능해진다.
5.6 Incremental Implementation
Bandit 문제에서 확인했던 것과 동일하게, 모든 에피소드에 대한 Return 값을 저장해서 사용하는 것은 비효율적이고, 점증적인 구현을 통해 정확한 값을 계산하도록 하는 것이 좋다. Ordinary Importance Sampling의 경우, 앞에서 진행했던 것과 동일하게 진행하면 되고, Weighted Importance Sampling의 경우 기존에 1을 더해주는 것 대신에 Weight값을 더해서 진행하면 된다.
\[\begin{array}{l} \textbf{Initialize, for all } s \in \mathcal{S},\, a \in \mathcal{A}(s):\\ \quad Q(s,a) \leftarrow \text{arbitrary}\\ \quad C(s,a) \leftarrow 0\\ \quad \mu(a\mid s) \leftarrow \text{an arbitrary soft behavior policy}\\ \quad \pi(a\mid s) \leftarrow \text{an arbitrary target policy}\\[6pt] \textbf{Repeat forever:}\\ \quad \text{Generate an episode using } \mu:\\ \qquad S_0, A_0, R_1, \ldots, S_{T-1}, A_{T-1}, R_T, S_T\\ \quad G \leftarrow 0\\ \quad W \leftarrow 1\\ \quad \text{For } t = T-1,\, T-2,\, \ldots,\, 0 \text{ down to } 0:\\ \qquad G \leftarrow \gamma G + R_{t+1}\\ \qquad C(S_t, A_t) \leftarrow C(S_t, A_t) + W\\ \qquad Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \frac{W}{C(S_t, A_t)}\bigl[\,G - Q(S_t, A_t)\,\bigr]\\ \qquad W \leftarrow W \frac{\pi(A_t\mid S_t)}{\mu(A_t\mid S_t)}\\ \qquad \text{If } W = 0 \text{ then ExitForLoop} \end{array}\]위 알고리즘은 Every Visit Off Policy MC의 Prediction을 진행한 것이다. $G \leftarrow \gamma G + R_{t+1}$은 앞의 $G_t$를 구하는 과정을 풀어서 쓴 것이다. 먼저 C에 W 값을 저장해주고 W/C를 가중치로 하여 TD Update를 진행하면 된다. (State Value function을 구할 때에도 동일하게 진행하면 됨. - Sampling Ratio는 변함 x)
5.7 Off-Policy Monte Carlo Control
On-Policy MC 방법에서는 가치를 추정하는 정책과 실제로 control에 사용하는 정책이 동일했었다. Off-Policy MC 방법에서는 이 둘이 분리되기 때문에 Target Policy가 Deterministic해도 Behavior Policy가 $\varepsilon$-soft Policy를 사용한다면 탐험에 대한 걱정이 사라진다.
아래는 Off Policy MC Control의 Pseudo Code이다.
\[\begin{array}{l} \textbf{Initialize, for all } s \in \mathcal{S},\, a \in \mathcal{A}(s):\\ \quad Q(s,a) \leftarrow \text{arbitrary}\\ \quad C(s,a) \leftarrow 0\\ \quad \pi(s) \leftarrow \text{a deterministic policy that is greedy w.r.t. } Q\\[6pt] \textbf{Repeat forever:}\\ \quad \text{Generate an episode using any soft policy } \mu:\\ \qquad S_0, A_0, R_1, \ldots, S_{T-1}, A_{T-1}, R_T, S_T\\ \quad G \leftarrow 0\\ \quad W \leftarrow 1\\ \quad \text{For } t = T-1,\, T-2,\, \ldots,\, 0 \text{ down to } 0:\\ \qquad G \leftarrow \gamma G + R_{t+1}\\ \qquad C(S_t, A_t) \leftarrow C(S_t, A_t) + W\\ \qquad Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \frac{W}{C(S_t, A_t)}\bigl[\,G - Q(S_t, A_t)\,\bigr]\\ \qquad \pi(S_t) \leftarrow \arg\max_{a} Q(S_t,a) \quad (\text{with ties broken arbitrarily})\\ \qquad W \leftarrow W \frac{1}{\mu(A_t \mid S_t)}\\ \qquad \text{If } W = 0 \text{ then ExitForLoop} \end{array}\]위 코드에서 살펴볼 점은 2가지이다.
먼저, $\pi$가 Deterministic Policy로 사용된다는 점이다. $\mu$ 정책이 확률론적이기 때문에 위와 같은 설정이 가능하다. 두번째로, 업데이트를 중단하는 지점이다. 위 알고리즘을 보면 Terminal State에서 시작해서 $W = 0$인 지점에서 Q와 $\pi$에 대한 업데이트가 중단된 것을 확인할 수 있다. 이는 Importance Sampling Ratio의 수식을 보면 알 수 있는데 $\pi$의 정책을 따를 때 절대로 나올 수 없는 Action의 경우에는 Ratio가 0이 되기 때문에 해당 시점 이후에는 더이상 업데이트라는 의미가 없어지기 때문이다.
MCES와 같이 에피소드 단위로 $\pi$ 정책을 개선하는 것이 바람직하지 않을까 생각할 수도 있지만 바로바로 개선하지 않는다면 Q function을 업데이트하는 지점의 경계가 모호해지기 때문에 바로 개선을 진행한 것으로 이해할 수 있다. 만약 개선을 에피소드가 끝나는 지점에서 진행하려면 W 또한 새로운 Policy를 바탕으로 진행해야 할 것이다.
하지만 위 업데이트 방식은 큰 문제점이 존재한다. 마지막 Non-Greedy Action 이전 state는 전부 weight가 0이 되어서 학습이 불가하다는 점이다. 이를 해결하는 방법은 Chapter 7에서 다루는 TD 방식을 도입하거나 $\gamma$가 1보다 작은 방식을 취하는 것이다.
5.8 Importance Sampling on Truncated Returns
사실 Importance Sampling을 사용하여 $G_t \sim \mu$의 $G_t \sim \pi$로 변환하도록 하는 것은 표면적으로만 보면 전혀 문제가 없어보인다. 다만 $G_t$가 어떤 것으로 이루어져 있는지에 대해서는 생각해 보아야 하는데 $G_t = R_{t+1} + \gamma R_{t+2} + …$이므로 $R_{t+1}$의 입장에서는 $t+2 \sim T$까지의 Timestep에 대한 Ratio는 전혀 쓸모가 없을 것이다. 해당 비율은 오히려 Variance만 키우는 역할을 하기 때문에 적절한 처리가 필요하다.
따라서 $G_t$를 아래와 같은 식으로 새롭게 분리할 수 있다. 이때 $\bar{G}t^{h}$는 $\bar{G}_t^{h} = R{t+1} + R_{t+2} + … + R_h$를 의미한다.
\[\begin{aligned} G_t &= R_{t+1} + \gamma R_{t+2} + \gamma^{2} R_{t+3} + \cdots + \gamma^{T-t-1} R_T \\[4pt] &= (1-\gamma)R_{t+1} + (1-\gamma)\gamma\,(R_{t+1}+R_{t+2}) + (1-\gamma)\gamma^{2}\,(R_{t+1}+R_{t+2}+R_{t+3}) + \cdots \\[2pt] &\quad + (1-\gamma)\gamma^{T-t-2}\,(R_{t+1}+R_{t+2}+\cdots+R_{T-1}) + \gamma^{T-t-1}\,(R_{t+1}+R_{t+2}+\cdots+R_T) \\[6pt] &= \gamma^{T-t-1}\,\bar{G}_t^{\,T} + (1-\gamma)\sum_{h=t+1}^{T-1}\gamma^{h-t-1}\,\bar{G}_t^{\,h}. \end{aligned}\]해당 식 이후에는 각 $\bar{G}_t^{h}$에 $t$부터 $h$까지의 Ratio를 곱해 가중치를 연산한다. 아래 식은 Ordinary Importance Sampling과 Weighted Importance Sampling이다.
Ordinary Importance Sampling
Weighted Importance Sampling
다만 위 방법도 완전하게 의미 없는 Ratio를 없애는 방법은 아니다 $t$와 $h$의 격차가 커질수록 결국 의미 없는 Ratio는 커지지만 Gamma의 차수가 늘어남에 따라서 이를 상쇄시킬 수 있다고 생각하면 된다.
5.9 Per-Decision Importance Sampling
5.8에서 살펴본 Importance Sampling 방법은 사실 완전하게 분산을 줄일 수 있는 방법은 아니다. 이를 정확하게 반영하기 위해서 결정 단계별 중요도 추출 방법을 사용할 수 있다.
우리가 실제로 기댓값으로 사용하는
\[\begin{align} \rho_{t:T-1}G_t &= \rho_{t:T-1}(R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{T-t-1}R_T) \\ &= \rho_{t:T-1}R_{t+1}+\gamma\rho_{t:T-1}R_{t+2}+\cdots+\gamma^{T-t-1}\rho_{t:T-1}R_T \end{align}\]와 같은 형태이다. 다만, 실제로 의미가 있는 부분만을 나타낸다면 아래와 같을 것이다.
\[\mathbb{E}\!\left[\frac{\pi(A_k\mid S_k)}{b(A_k\mid S_k)}\right] =\sum_a b(a\mid S_k)\frac{\pi(a\mid S_k)}{b(a\mid S_k)} =\sum_a \pi(a\mid S_k)=1.\] \[\mathbb{E}\!\left[\rho_{t:T-1}R_{t+1}\right] = \mathbb{E}\!\left[\rho_{t}R_{t+1}\right].\]따라서 이를 반영하여 다시 식을 작성하면 전체 가중치는 아래와 같이 결정 단계별로 정리된다.
\[\tilde{G}_t = \rho_{t:t}R_{t+1} +\gamma\rho_{t:t+1}R_{t+2} +\gamma^{2}\rho_{t:t+2}R_{t+3} +\cdots +\gamma^{T-t-1}\rho_{t:T-1}R_T.\] \[V(s)=\frac{\sum_{t\in\mathcal{T}(s)}\tilde{G}_t}{\lvert\mathcal{T}(s)\rvert}.\]5.10 Summary