
1. Abstract & Introduction
LLM을 다양한 분야에서 사용함에 따라서 multiple generation call, structured input/output과 같은 복잡한 작업이 점점 더 많이 사용되고 있다. 다만, 이것들을 효율적으로 programming하고 executing하는 시스템이 부재하다. 따라서 저자들은 SGLang을 통해 해당 목적을 달성하려고 한다. SGLang은 frontend과 runtime으로 구성되어 있다. 최종적으로 agent control, logical reasoning, JSON Decoding과 같은 다양한 벤치마크에서 state-of-art 성능의 6.4배에 해당하는 throughput을 달성했다고 한다.
LLM의 성능이 증가함에 따라서 활용 가능성이 증가했고 여러 application이 생겨났다. 여러 application을 달성하기 위해서 few-shot learning, self-consistency, skeleton-of-thought, tree-of-thought등의 기법을 활용한다. 위에서 언급한 기법들을 사용하기 위해서, 여러 번의, 때로는 의존적으로 Multiple LLM Generation Call을 필요로 한다.
이러한 배경에서 LLM의 생성 process를 schedule하고 control하는 프로그램이 필요해졌고, 저자들은 해당 방식을 LM Program이라고 이름을 붙였다. 저자들은 LM Program이 두 가지 특성을 필요로 한다고 주장한다.
- LM program들은 일반적으로 제어 흐름이 섞인 multiple LLM Call을 포함한다.
- LM program들은 구조화된 input/output을 사용한다. 이는 LM Program들의 구성을 가능하게 해주고, 이미 존재하는 시스템에 LM Program을 통합할 수 있게 해준다.
LM Program은 어떤 LLM 호출의 전체 파이프라인이라고 생각하면 된다. 같은 질문에 대해서 10개의 답변을 병렬로 생성한 뒤에, 투표로 최종적인 선택을 진행하는 예시를 생각해보면, API를 사용하여 10개의 query를 생성하고 답변을 받아서 선택을 진행하는 것이 아니라, 해당 과정 전체를 하나의 프로그램으로 생각해서 표현과 실행을 프로그램 단위로 최적화하겠다는 의미이다.
현재 이 LM Program이 널리 사용되고 있음에도 불구하고, 해당 프로그램을 express하고 execute하는 과정이 비효율적이라고 주장한다. 아래가 두가지 비효율성의 예이다.
- LM Program들이 다양한 종류의 input을 받거나 병렬처리를 진행해야 해서 비결정론적인 특성을 가지고 있고, 이로 인해서 programming하기 어렵고 지루하다.
- LM Program들을 실행하는 것은 쓸모 없는 계산이나 memory 사용으로 인해서 비효율적이다.
- KV Cache값을 재사용하지 않는 경우, 매우 비효율적이다.
- Constrained Decoding을 사용하는 경우에서도 다른 시스템은 여러 토큰을 한번에 처리하지 못한다.

따라서 저자들은 front-end 단에서는 LM Program의 Programming을 단순화하고, runtime단에서는 실행을 가속화하는 방향으로 이 문제를 해결하려고 한다.
먼저 Front-End 단에서는 Python 언어로 SGLang을 embed해서 native python syntax를 사용하여 prompting workflow를 편집할 수 있도록 했다.
이후 Runtime 단에서는 execution 관점에서 3가지 optimiziation을 도입하여 LM Program의 실행을 가속화하려했다. RadixAttention은 KV Cache를 관리하는 정책에 관한 내용이다. 이는 KV 캐시를 전통적인 캐시처럼 관리하고 효율적인 matching, insertion, eviction을 위해 radix-tree를 사용한다는 것이다. 또한 Compressed finite state machine을 도입하여 constrained decoding을 진행할 때 autoregressive + masking 형태로 진행하는 것이 아니라 한 번에 여러 토큰을 decoding할 수 있도록 하여 효율을 높혔다. 마지막으로는 API Speculative execution을 통해서 Api 호출을 통해서만 사용할 수 있는 model에 대해서도 최적화를 진행했다.
2. Programming Model

2.1 Running Example
논문에서 LM Program Programming, 즉 LLM을 어떻게 사용하여 본인이 원하는 Task를 수행할 수 있을 것인지를 결정하기 하는 programming을 설명하기 위해서 Branch-Solve-Merge 방식을 사용하여 Image에 대한 Essay를 평가하는 Task를 예로 들고 있다.
위 Figure 2에서는 python으로 작성된 Domain-specific language 언어를 사용하여 실제로 위의 Task 수행을 위한 코드를 보여주고 있다. System 명령어로 공통 프롬프트를 넣어주고, Image와 Essay 명령어로 필요한 값을 입력해준다. 이후 select 명령어를 통해 yes, no 둘 중에서 더 높은 확률을 가진 값을 파악하여 연관성을 파악한다. 그 이후에 parllel evaluation을 진행하는데, 미리 정의해둔 dimension 각각의 시각을 활용하여 해당 수 만큼 fork 명령어로 동일한 evaluation을 진행한다. 최종적으로 모든 답변을 종합하여 regex 포맷에 맞는 최종 답변을 생성하는 과정으로 진행된다.
2.2 Language Primitive
SGLang에서는 자체 내장 함수를 제공한다. 위 Figure 2 예시에서도 해당 내용을 확인할 수 있는데, 정리해보면 아래와 같다. 이는 파이썬 위에서 구현되어 있기 때문에 파이썬 기본 문법과 혼용해서 사용이 가능하다.
system(text): 전역 규칙·역할(시스템 메시지) 설정.user(text): 사용자 입력 역할로 프롬프트에 추가.assistant(text=None): 어시스턴트 역할 추가(접두 문구를 고정할 때 사용 가능).+=/extend(text_or_obj): 현재 프롬프트 상태에 문자열/객체를 덧붙임.image(path_or_bytes)/video(path_or_bytes): 멀티모달 입력(이미지/비디오) 첨부.gen(name, **opts): 한 번의 생성 호출을 실행하고 결과를state[name]에 저장 (옵션으로max_tokens,stop,temperature,top_p,top_k,regex등 사용).select(options): 주어진 후보 중 최대 우도(로그확률) 항목을 선택.fork(k): 프롬프트 상태를 k개로 복제하여 분기 실행(비동기 진행).join(forks): 모든 분기 실행 완료를 대기하고 상태를 병합(배리어 동기화).state["var"]: 이전gen/select결과를 읽어 옴(읽는 순간 동기화 발생).
2.3 Execution modes
SGLang Program을 실행하는 방법은 Interpreter mode와 Compiler mode가 있다. Interpreter 모드를 사용하면, prompt는 비동기 스트림으로 다루어지며, Fetching(var[value])와 같은 동작에서만 block되어 이전 명령의 종료를 기다리게 된다. Compiler mode에서는 computational graph로 컴파일되어 몇가지 최적화를 진행하게 되는데, 논문에서는 Interperter 모드로 설명을 진행한다.
2.4 Comparsion

정리하자면, SGLang, LMQL. Guidance, Langchain, DSPy와 같은 것들은 전부 프롬프트를 준비하는 과정에 해당한다. 다만, SGLang / LMQL / Guidance 등은 direct programming이 가능하게 해주고 Langchain / DSPy는 High-level로 프롬프트를 자동으로 최적화하는 데에 사용된다. 추가적으로 vLLM이나 Ollama와 같은 것들을 model을 직접 실행시켜 token을 생성하는 back-end에 해당하는 아키텍쳐이다. SGLang은 prompt생성과 함꼐 Runtime Backend도 관리한다는 점이 특징이다.
3. Efficient KV Cache Reuse with RadixAttention
SGLang program은 다수의 generative call을 묶거나, 병렬 복사본을 생성하는 경우가 많다. 이 경우가 아니더라도 다른 프로그램들 또한 종종 공통된 prompt를 공유하는 경우가 많다. 이는 당연히 KV Cache처리와 관련된 논의를 유발하는데, 공통된 KV 값을 계속해서 연산한다면 의미없이 throughput과 latency에 악영향을 끼치는 것이 되어버리기 때문이다.
따라서 저자들은 RadixTree를 활용하여 KV Cache의 Reuse, Search, Insertion, Eviction 연산을 효율적으로 진행하는 RadixAttention을 도입하게 된다. 아무리 좋은 KV Cache 정책을 고안한다고 해도, 실제로 KV Cache를 다시 사용하는 Cache hit rate가 낮다면 의미가 없기 때문에, 저자들은 LRU Eviction Policy와 Cache-aware prefix Search Policy를 도입하여 Cache hit rate를 최대화하려고 한다.추가적으로, RadixAttention은 기존의 Continuous Batching, PagedAttention, Tensor Parallelism과도 함께 사용이 가능하다.
3.1 RadixAttention
RadixAttention은 RadixTree를 사용하여 KV Cache를 관리하는 방식이다. Tree의 edge에 해당하는 것은 분기되어 달라지기 시작한 prompt에 해당한다. 이는 가변길이의 객체를 사용하면서 Prefix를 최상단 노드까지의 path로 표현해 공간-효율적으로 KV 값들을 저장할 수 있게 해준다. vLLM 논문에서 등장한 PagedAttention처럼 page 단위로 값을 저장하는 방식으로 non-contiguous memory에 KV 값을 저장할 수 있다.
3.2 LRU Eviction Policy
Radix Attention에서 GPU 메모리는 한정되어 있기 때문에 효율적으로 Cache hit rate를 높이기 위해서, KV 값들을 flush/evict 해주어야 한다. 해당 정책으로 사용되는 것이 Least Recently Used Policy로 사용하지 않은지 가장 오래된 leaf부터 제거한다는 것이다. leaf부터 제거함에 따라서 공통된 KV 값들은 유지해 hit rate를 높게 유지할 수 있다. 추가적으로 Continuous Batching을 사용할 때, 내가 지금 실행하고 있는 node를 evict하면 안되기 때문에 reference count를 도입하는데, 해당 refer count와도 이 축출 정책이 충돌하지 않는다는 장점이 있다.
GPU를 사용한 Inference를 진행할 때, 메모리는 Model Parameter, Activation, KV Cache 3가지로 크게 구성되어 있는데, Batch가 커짐에 따라서 Activation이나 중간 연산값이 차지하는 메모리가 커지게 된다. RadixAttention 방식에서는 KV 값의 크기를 고정해서 사용하는 것이 아니라 배치 크기와 동적으로 조절되어 사용한다는 설명도 포함되어 있다.
위 Figure 3 예시를 통해서 RadixAttention의 Evict와 KV Reuse 정책을 확인할 수 있다. Evict는 Leaf노드에서부터 진행되며 Prefix는 한번만 저장되어도 충분하기 때문에 공간 효율적 저장이 가능하다.
3.3 Cache-aware scheduling
Cache Hit Rate는 Number of cached tokens / Number of tokens로 정의된다. Hit 비율을 높이려면 비슷한 Prompt들이 연속적으로 들어와야 하는 것이 당연하기 때문에, Request order가 굉장히 중요해진다. 따라서 저자들은 Matched Prefix Length 공통 접두사 길이를 기준으로 request들을 정렬한 뒤에 처리하는 방식을 사용하게 된다. 저자들은 이 Policy가 offline case에서 최적임을 증명했다고 한다.
이 내용은 뒤 Appendix에서 다루겠다.
3.4 Distributed Cases
Tensor Parallelism은 하나의 모델을 여러 GPU에 분배해서 사용하는 것으로 생각하면 된다. 여러 Layer나 Head, FFNN 등을 분할하는 것이기에, KV Cache 값도 본인의 연산 과정에서 필요한 값만을 각각 나누어 저장하면 되기 때문에 동일한 tree 연산이 사용되고, 따라서 별도의 동기화 과정은 필요가 없다.
Data Parallelism 과정은 뒤의 Appendix에서 다룬다.
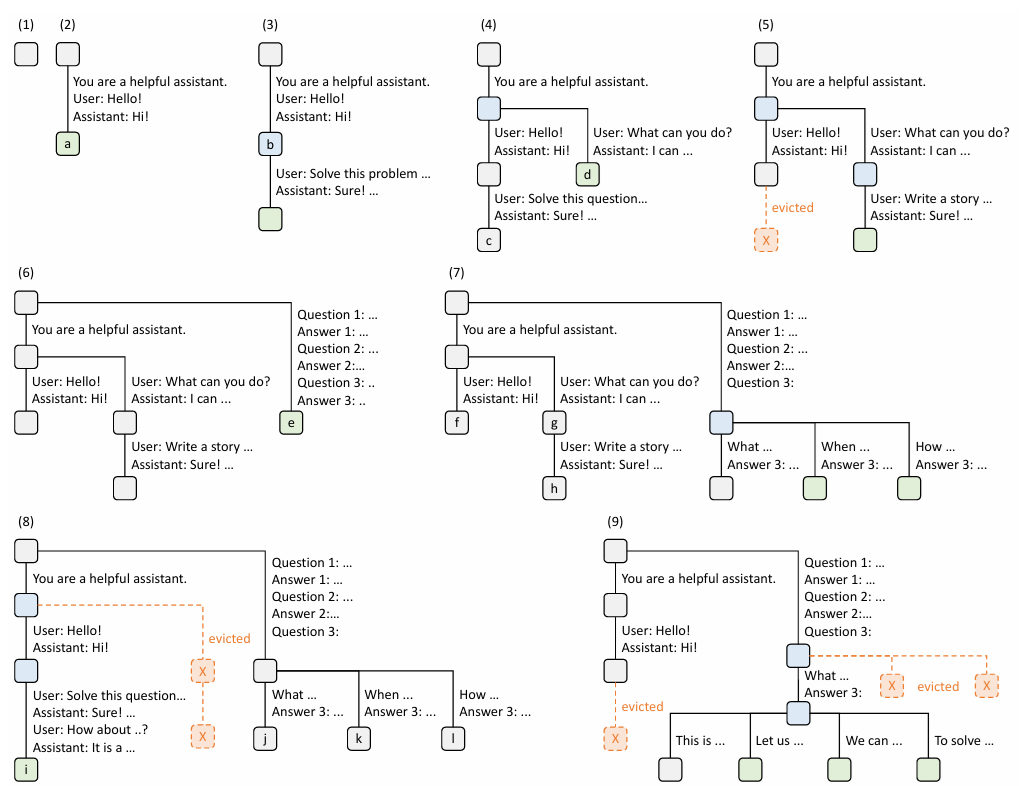
4. Efficient Constrained Decoding with Compressed Finite State Machine
LM Program을 사용할 때 모델의 output이 특정 포맷을 지키면서 결과를 출력하도록 해야 할 수도 있다. 이 경우에는 Regex를 사용하는 것이 효과적인데, 정규표현식을 사용하면 Deterministic Finite Automata를 생성할 수 있어 원하는 문자열 포맷으로 Constrained된 output 생성이 용이해지기 때문이다.
다만 기존의 방법론들은 Regex를 사용한 Finite State Machine을 생성하는 과정에서 Constant String을 한번에 처리하지 못하는 문제가 존재했다. 결과적으로 바로 다음에 나올 Token들이 고정되어 있음에도 불구하고, 의미없는 LLM query를 보내 낭비하는 문제가 발생한다는 것이다.
위의 그림을 통해서 확실히 확인할 수 있는데, {"summary": "부분까지는 반드시 고정되어 있어 해당 토큰들까지는 굳이 LLM query가 필요없다. 다만 이전에 존재하던 token-by-token 접근방법을 사용하여 다음 토큰이 고정되어 있어도 쿼리를 넣어 고정토큰을 출력하도록 하는 비효율적인 동작 방식을 사용하고 있었다.
따라서 SGLang의 저자들은 위의 {", summary, ":, _" 4가지 토큰을 한번에 처리하여 LLM 고정된 token은 다시 생성하지 않고 바로 뒤의 토큰을 생성하도록 하는 Multi-token 접근방식을 차용하여 속도를 높였다고 한다.
이를 위해서 기존에 사용하던 FSM을 바탕으로 Constrained FSM을 생성하는 과정을 먼저 거친다고 한다. 위에서 언급했던 것처럼 첫 번째 단계는 Regex -> Finite State Machine 과정이다. Compiler 수업에서 해당 부분은 자세하게 다루었다.
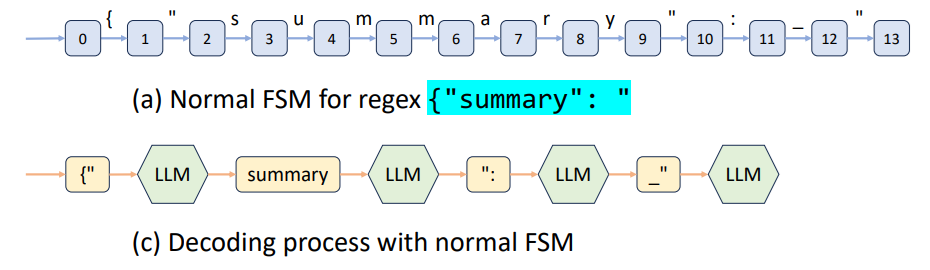
FSM(DFA)는 기본적으로 Character 단위로 생성된 Automata이고, LLM은 Token단위로 Decoding을 진행한다. 따라서 이 간극을 처리하는 것이 Constrained Decoding의 핵심이다.
기존의 방법론들 중 하나인 Outlines 방법을 예로 들어 설명하면 Character Level DFA를 Token Level DFA로 변환하는 과정을 거치고 Current state에서 진행할 수 있는 transition token을 골라 나머지 token들의 decoding probability를 0으로 설정하는 과정으로 진행된다. 이 방식은 다만, 처음에 token level dfa를 compiling하는 데에 시간이 많이 든다는 단점이 있다.
더 자세한 내용은 아래 링크에 정리되어 있다.
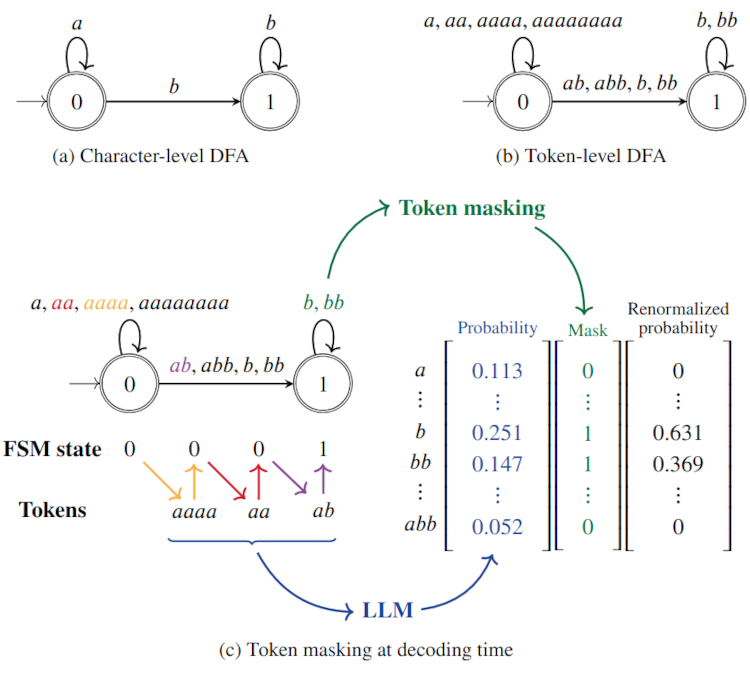
SGLang 논문에서는 해당 문제를 FSM을 압축한 Compressed FSM으로 압축하는 과정을 거쳐서 최적화하고, Constant string 구간이 더해질 때 발생하는 문제에 대해서는 Retokenization을 진행하여 이 간극을 매우는 방식을 적용한다.
위의 (a)의 예시에서 Singular Transition Edge(DFA의 다음 state가 고정되어 있고, Transition 또한 하나의 character를 통해서만 처리가 가능하면 singular transition edge임.)를 한번에 묶어서 Compressed edge로 표현하는 것을 볼 수 있다. 이렇게 되면, 불필요한 LLM Query를 없애고 한번에 multi-token decoding을 진행하는 효과를 볼 수 있다.
위 Multi token processing 방법은 물론 속도를 높일 수 있지만, Decoding process에서 token을 고려하지 않는다. 이를 무시하고 진행한다면, 생성된 token과 뒤에 오는 상수 string이 concat되는 구조의 경우에 앞의 token과 뒤의 string이 한번에 tokenization 처리된 것과 분절 단위로 concat된 것의 token 차이가 발생하게 된다. 따라서 해당 위험을 방지하기 위해서 필요한 경우 SGLang은 Retokenization을 진행한다고 한다. 앞에서 예로 든 Outlines 방식은 애초에 token 단위로 처리하는 것이기 때문에 이런 방식들이 필요하지 않다.
5. Efficient Endpoint Calling with API Speculative Execution
이 섹션은 Open Source LLM이 아닌 GPT와 같은 Closed Source 모델에 대해서 효율성을 높이는 방식을 다룬다. s += context + "name:" + gen("name", stop="\n") + "job:" + gen("job", stop="\n").과 같은 코드를 다루는 경우 context에 해당하는 내용은 gen() 함수가 두 번 호출되기 때문에, 결과적으로 토큰 낭비가 된다. 이 낭비를 최소화하기 위해서 논문에서는 gen("name") 함수를 실행할 때, terminal token을 무시하고 계속해서 생성해 두어, gen("job")에 해당하는 내용이 등장한다면, 추가적인 연산을 진행하지 않고 해당 token sequence들을 재사용한다는 것이다. 다만, 답이 굉장히 많이 달라지는 경우에 대해서는 이것이 제대로 동작하지 않을 가능성이 크다.
6. Evaluation
저자들이 진행한 실험에 대한 여러 자세한 내용이 존재하만, 논문에서 다루고자 하는 핵심과 관련된 부분만 정리해 보았다. SGLang들은 Custom CUDA Kernel을 활용한 Pytorch로 구현되었다.
6.1 Baselines
SGLang은 LM program을 direct programming할 수 있게 해주기도 하고, back-end 또한 구현하기 때문에 비교를 위한 Baseline으로 Guidance와 LMQL 그리고 마지막으로 Back-end 단에 해당하는 vLLM을 baseline으로 설정했다.
- Guidance -
Guidance v0.1.8withllamma.cpp - LMQL -
LMQL v0.7.3withHugging Face Transformers - vLLM -
vLLM v0.2.5withdefault API server
6.2 Workloads
- MMLU (5-shot): 한 토큰만 디코딩하여 정답 선택.
- HellaSwag (20-shot):
select함수로 highest-probability 선택지 고르기. - ReAct agent / Generative agents: 원 논문의 execution traces를 추출해 replay.
- GSM-8K: Tree-of-Thought (ToT) 적용.
- Tip generation: Skeleton-of-Thought (SoT) 사용.
- LLM judging: Branch-Solve-Merge 기법으로 분기 통합.
- JSON decoding: regex-specified schema에 맞춘 constrained decoding.
- Multi-turn chat (4 turns): 각 turn input 길이는 256–512 tokens 범위에서 랜덤 샘플.
- Short output: 응답 4–8 tokens
- Long output: 응답 256–512 tokens
- RAG pipeline: DSPy 공식 예제 사용.
6.3 Metrics
- Throughput: 큰 batch of program instances로 maximum throughput 측정.
- 단위: programs per second (p/s)
- Latency: no batching 상태에서 single program을 여러 번 실행해 average latency 보고.
6.3 End to End Performance
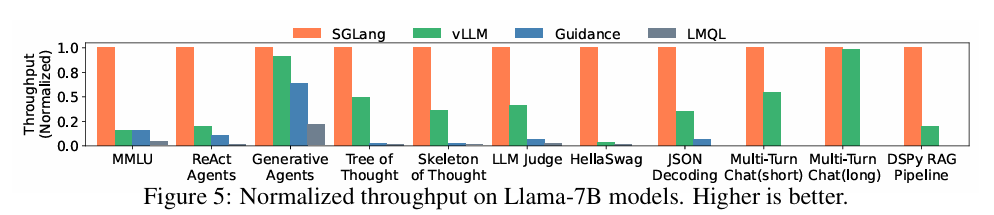
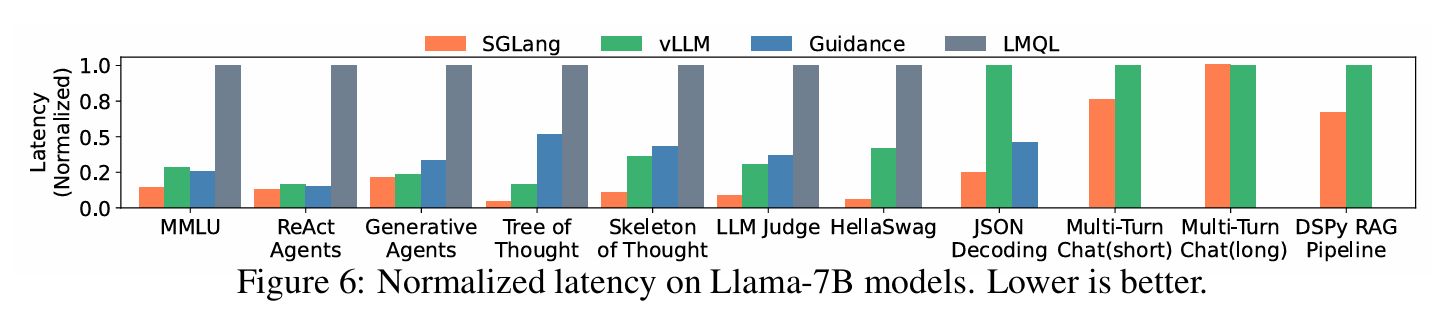
위 Figure 5와 Figure 6는 open source 모델인 Llama 7B 모델을 활용하여 Latency와 Throughput을 여러 Baseline들과 비교한 지표이다. 처리량은 최대 6.4배, 지연 시간은 최대 3.7배 효과가 있었다고 한다. 이러한 결과들은 모두 RadixAttention과 Compressed FSM 등을 통해서 달성할 수 있었다고 하고, 해당 벤치마크들에서 Cache hit rate는 50~99%의 수치를 보였으며 이 결과는 uppper bound의 96%에 해당하는 수준이라고 한다.
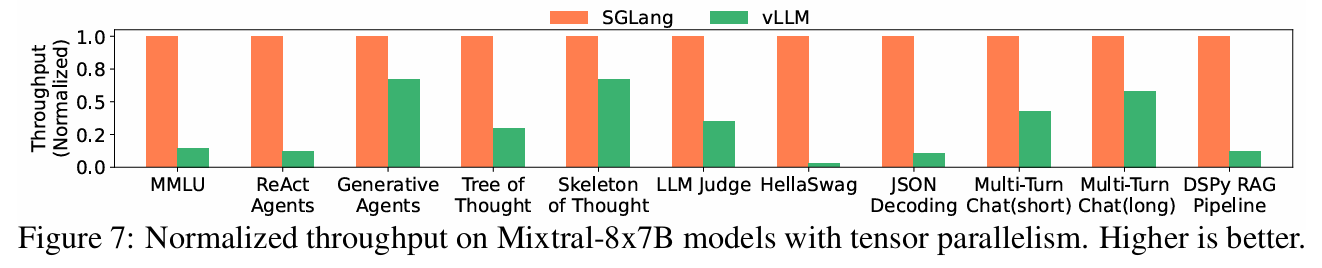
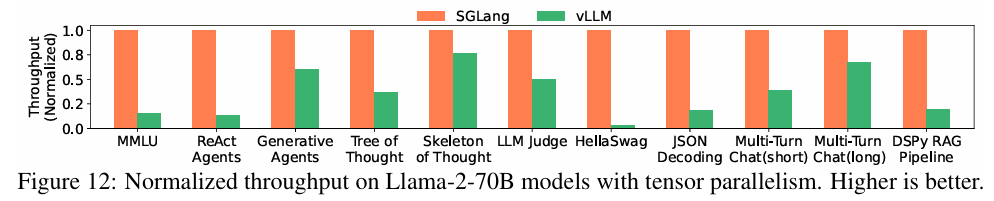
추가적으로 저자들은 더 큰 모델에 대해서 tensor parallelism을 적용한 성능을 측정해보았을 때, 작은 모델과 비슷한 수준의 성능 향상이 있었고, 큰 모델에 대해서도 좋은 일반화 성능을 보인다고 한다.

위 Table은 Image와 Video 도메인을 포함하는 multi-model model에 대한 처리량을 비교한 지표이다. 기존 Token을 사용하는 텍스트 도메인 LLM과 동일하게 KV cache를 사용하는 방식으로 처리량을 늘렸는데, 이때 하나의 token에 해당하는 것이 이미지의 hash값에 해당한다. 따라서 동일한 이미지나 영상이라면 동일한 KV 값을 사용할 것이기 때문에 이에 대한 최적화가 가능하다.
다만, vLLM이나 기존의 serving framework가 multi-modal model에 대한 지원이 미흡하여 Hugging Face Transformer의 구현을 그대로 사용했다고 한다. 그 결과 처리량이 6배 증가했다.
마지막으로, API 모델에 대한 실험으로 위키피디아 페이지에서 3가지 필드 정보를 뽑은 프롬프트를 gpt-3.5 api를 사용하여 진행했을 때, Few shot prompting을 사용했을 때 api speculative execution 성능이 높고, Input token의 cost가 준다는 것 또한 확인했다고 한다.
6.4 Ablation Study
Cache hit rate vs latency/throughput
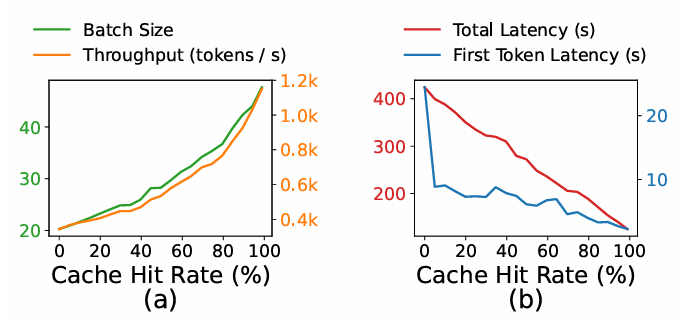 저자들은 Cache Hit Rate와 지연시간이나 처리량의 상관관계를 파악하기 위해서 위와 같은 도표로 성능을 측정했다. 결과적으로 Hit Rate가 높아짐에 따라서 지연시간이 줄고 처리량이 높아진 다는 것을 확인할 수 있었다고 한다.
저자들은 Cache Hit Rate와 지연시간이나 처리량의 상관관계를 파악하기 위해서 위와 같은 도표로 성능을 측정했다. 결과적으로 Hit Rate가 높아짐에 따라서 지연시간이 줄고 처리량이 높아진 다는 것을 확인할 수 있었다고 한다.
Effectiveness of RadixAttention
저자들은 본인들이 제안한 RadixAttention이 얼마나 효과적인지 보이기 위해서 다양한 KV Cache 관리 정책들과 본인들의 RadixAttention Architecture를 비교한다.
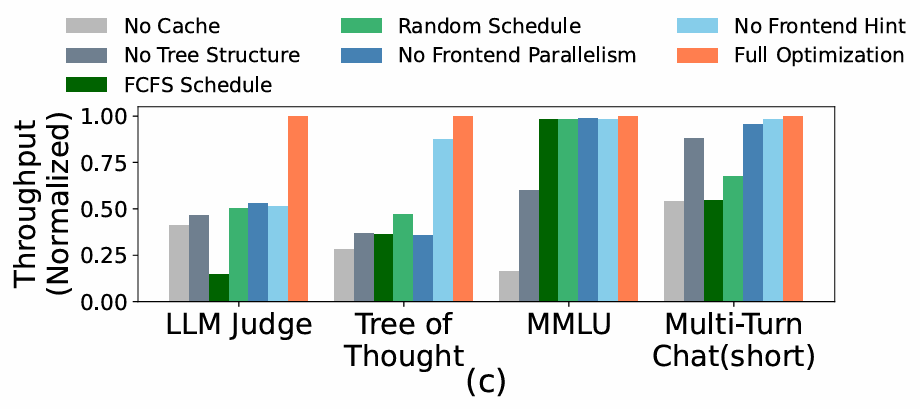
위의 비교군은 아래와 같다.
No Cache: KV Cache를 사용하지 않고 전부 재계산No Tree Structure: Table based Cache 사용FCFS Schedule: 논문에서 제안한 겹치는 것이 많은 순으로 처리 하지 않고 FCFS로 처리Random Schedule: 랜덤 순서대로 프롬프트를 처리No Frontend Parallelism: 인터프리터 병렬 처리 제거No Frontend Hint: Fork Hint를 제거Full Optimization: 논문에서 제안하는 모든 방법 사용
결과적으로 논문에서 제안한 모든 방법을 사용해야 Optimal Performance를 달성할 수 있다.
Overhead of RadixAttention
RadixAttention을 사용하면서 RadixAttention data를 관리하는 데에 들어가는 시간을 계산해보았을 때, ShareGPT dataset을 가지고 100개의 프롬프트를 처리하는 실험을 진행하면 74.3초가 걸리지만, RadixAttention data를 처리하는 시간은 총 0.2초로, Tree 연산의 복잡도가 선형적이기 때문에 충분히 무시할 만한 수준이라고 한다.
Effectiveness of the compressed finite state machine
논문에서 Constrained Decoding을 위해서 Compressed FSM을 제안했다. JSON Decoding Benchmark에 대해서 실험을 진행했을 때, 1.6배 더 많은 처리량을 달성했다고 한다. 다만, 모든 요청이 각각의 Constrain을 사용한다면 매번 FSM을 다시 디코딩해야 하기 때문에, 처리량이 2.4배 줄어든다는 문제가 발생한다고 한다.
Appendix
A. Additional Details on RadixAttention
Input Prompt를 받아서 처리하는 과정을 Prefill과정이라고 부르고, 계속해서 Output token을 생성하는 과정을 Decoding 과정이라고 부른다. 저자들은 Prefill + Decoding과정을 합쳐 single-generation call이라고 부른다.
Token을 생성하는 과정에서 중간 Tensor들이 생성되는데, 이 값들을 KV Cache라고 부른다. 이 값들은 이전 Token들에만 영향을 받기 때문에, 여러 prompt에서 동일한 token sequence들을 사용하면 이 Tensor들을 공유해서 사용하는 것이 불필요한 계산을 줄이고 효율성을 높이는 방법이다.
LLM program을 사용할 때, Multiple text segment들과 generation call들이 하나의 prompt 안에서 사용되는 것은 매우 흔하다. Multiple text segment는 여러 텍스트 명령어를, Generation Call은 중간중간의 LLM 생성 호출의 결과물들을 의미하는 것이다. 따라서 여러 Text segment와 gen call들이 하나의 프롬프트로 사용되는 경우가 흔한데, 이 연쇄적인 호출 과정에서 이전에 사용된 KV 값들을 재사용하는 것이 합리적인 선택이라는 것이다.
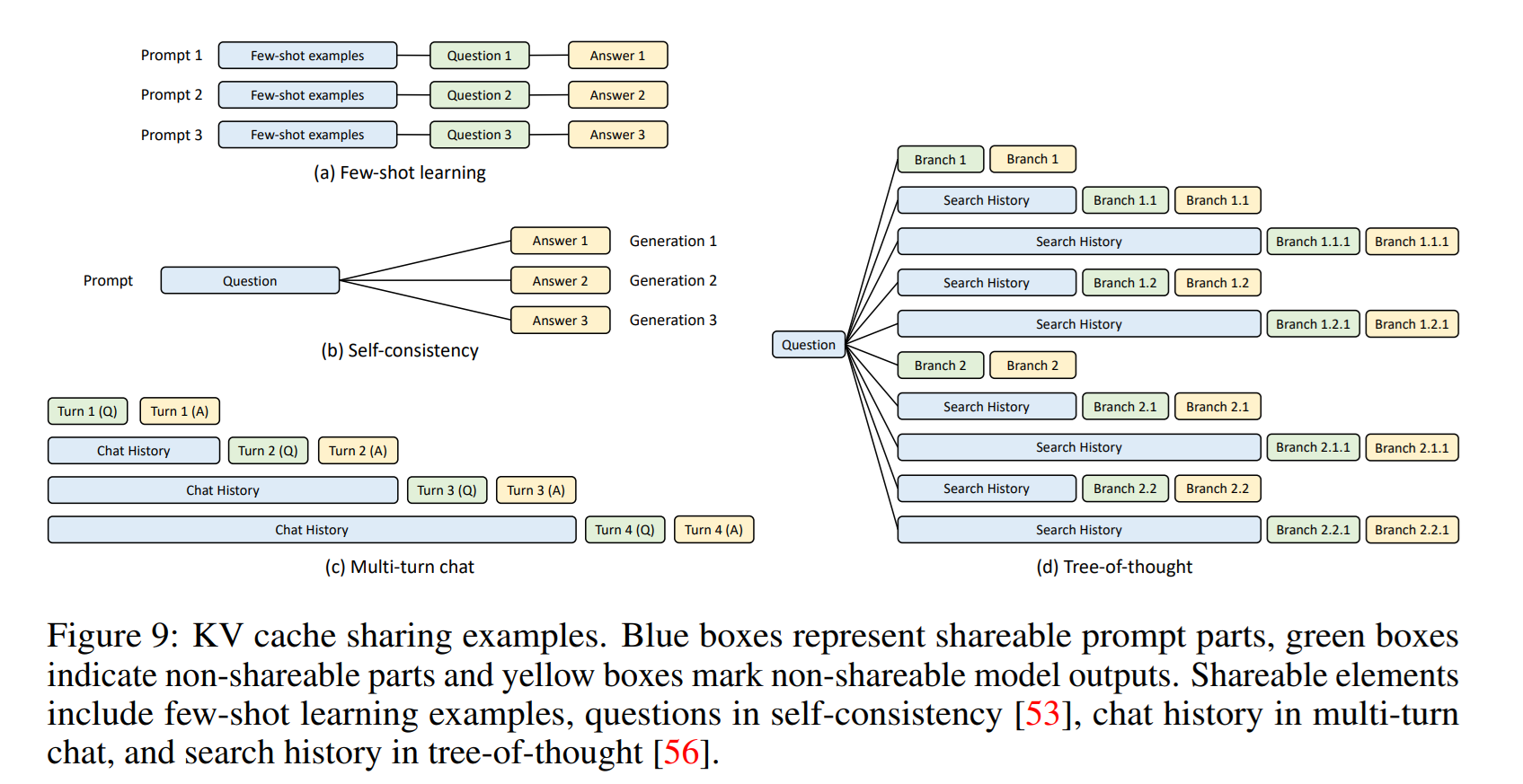
Figure 9에서는 KV Cache를 재사용하는 4가지 경우를 보여준다. 파란색 박스는 공유가 가능한 prompt, 초록색 박스는 공유가 불가능한 prompt output을, 노란색 박스는 prompt output를 의미한다. 위 4가지 경우를 모두 다루는 시스템은 없었지만, SGLang은 다룬다고 한다.
저자들은 Cache aware Scheduling을 continuous batching과 결합한 의사 코드를 작성했다. 해당 코드를 파이썬 형태로 나타내어 정리해 보았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# Cache-Aware Scheduling for RadixAttention with Continuous Batching
# Inputs:
# T : Radix tree (prefix index) that stores KV-cache per prefix node
# P : Memory pool (GPU KV-cache pool)
# B : Current running batch (requests that are already on GPU)
# Q : Waiting queue (requests not yet admitted)
# Output:
# finished : list of requests that finished this iteration
def schedule_radixattention(T, P, B, Q):
# fetch candidates from the waiting queue
requests = Q.get_all_requests()
# prefix matching (find longest prefix in the radix tree for each request)
for req in requests:
req.prefix_node, req.prefix_len = T.match_prefix(req.input_tokens)
# sort by Token prefix matching
requests.sort(key=lambda r: r.prefix_len, reverse=True)
# select the next batch under memory budget
available_size = T.evictable_size() + P.available_size()
current_size = 0
new_batch = []
for req in requests:
need = req.size() # KV memory needed by the request's unshared tail
if current_size + need < available_size:
new_batch.append(req)
delta = T.increase_ref_counter(req.prefix_node)
available_size += delta
current_size += need
# move selected requests into the running batch
Q.remove_requests(new_batch)
B.merge(new_batch)
# ensure we have KV memory; if not, evict and retry
needed_size = B.needed_size()
success, buffer = P.alloc(needed_size)
if not success:
T.evict(needed_size)
success, buffer = P.alloc(needed_size)
# run one decoding step for all requests in the running batch
B.run(buffer)
# collect finished requests and update prefix reference counters
finished = B.drop_finished_requests()
for req in finished:
T.decrease_ref_counter(req.prefix_node)
Results.insert(req)
return finished
위 과정은 아래와 같다.
waiting queue에서request들을 받는다.request들을common prefix length를 기준으로 sorting한다.- 현재 메모리에서 남는 공간
P.available_size()와 KV 값에서 축출 가능한 공간의 크기T.evictable_size()를 계산한다available_size = P.available_size() + T.evictable_size(). - 정렬된 request를 순차적으로 3에서 계산한
available_size보다 작은가를 기준으로 판별하여 새 request가 현재 배치에 추가될 수 있을 지 판단한다.- 이 과정에서
delta = T.increase_ref_count(req.prefix_node)코드를 실행하는데, 기존에 새로운 request를 배치에 추가하면서 ref count를 올리는 동작을 하게 되고, 기존에 evictable하다고 판단했던 노드들이 새롭게 축출 불가능하다고 판단되면 이를 반영해야 OOM을 방지할 수 있기 때문에 진행한다.
- 이 과정에서
- 현재 Running batch에 추가하여 실행할 수 있다고 판단되면 넣고 진행한다.
- 새롭게 추가되는 버퍼에 필요한 사이즈를 RadixTree의 evict 연산을 통해서 확보해준다.
- 이후에 한 Token을 decoding하고, 완료된 request의 reference count를 제거하는 등의 연산을 취한 뒤, 결과를 반환한다.
나머지 Appendix나 추가적인 증명은 나중에 필요하면 다시 다루겠다.