
Scalable Diffusion Models with Transformers
Abstract
기존의 U-Net 기반 Backbone이 아닌 Latent Dimension을 Latent Patch로 생성한 뒤 Transformer를 사용하여 Denoising을 진행하는 과정으로 처리하는 새로운 Diffusion Transformer를 제안한다.
1. Introduction
Transformer는 많은 Task에 활용되지만, Image-level generative model은 아직 Convolutional U-Net 구조를 사용하기 때문에 저자들은 Transformer 구조를 제안한다. U-Net의 Inductive bias가 diffusion model의 성능에 크게 영향을 미치지 않음을 보이고 이 구조가 아닌 transformer 구조로의 확장을 제안한다.
저자들은 추가적으로 Transformer의 scaling behavior를 파악한다고 한다. 즉 Gflop로 측정되는 Network complexity와 FID로 측정되는 sample quality와의 상관관계를 파악하고자 한다.
2. Related Work
자명한 내용
3. Diffusion Transformers
3.1 Preliminaries
Diffusion formulation
다른 부분들은 모두 DDPM의 원본 수식과 별반 다르지 않다. 다만, 전체 ELBO Term을 다시 떠올려보면 아래와 같다.
\[\mathcal{L}(\theta) = -\log p_{\theta}(x_0 \mid x_1) + \sum_t \mathcal{D}_{KL}\!\left[ q(x_{t-1} \mid x_t, x_0) \;\|\; p_{\theta}(x_{t-1} \mid x_t) \right]\]이전에 위 ELBO 식은 $\mu_{\theta}$ 식에 대한 reparameterization을 통해 간단히 $\left|\varepsilon_{\theta}(x_t,t)-\varepsilon_t\right|^2$ 형식으로 표현하여 학습을 진행했었지만, variance에 대해서는 별도의 학습을 하지 않고 고정된 값을 사용했던 것으로 기억한다.
다만, 이 논문에서는 Nichol and Dhariwal Approach를 따라서 $\varepsilon_{\theta}$를 ELBO Simple에 대해 훈련을 한 뒤 $\Sigma_{\theta}$에 대한 값을 전체 ELBO에 대한 식으로 한번 더 훈련을 하는 과정을 진행한다고 한다. 따라서 우리가 필요한 Output은 $\varepsilon_{\theta}$와 $\Sigma_{\theta}$에 대한 값으로 원본과 동일한 형식 2개가 필요하다.
3.2 Diffusion Transformer Design Space
이 논문은 Image 도메인에 대한 DDPM을 학습하는 과정이기 때문에 ViT Transformer의 설정을 많이 참조하여 모델을 만들었다고 한다. 아래는 전체적인 Transformer Design이다.
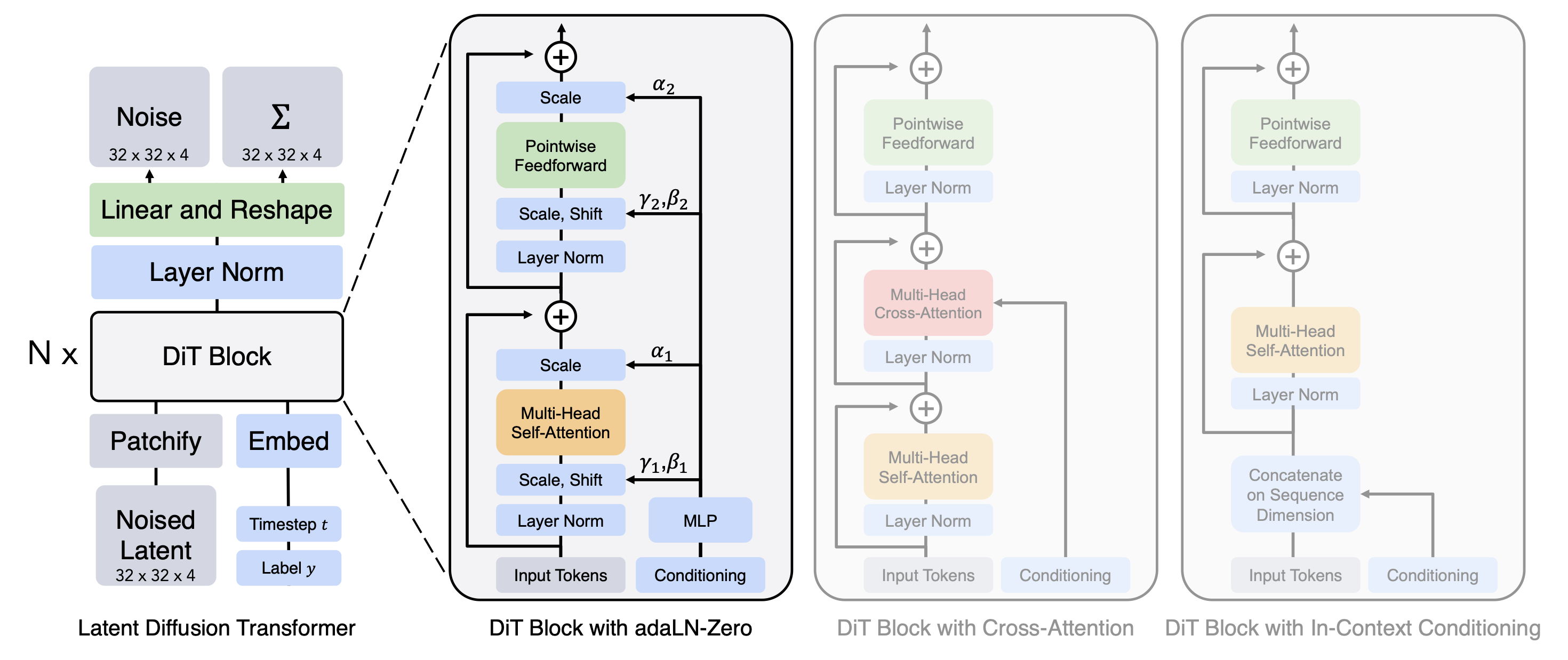
위 Figure에 존재하는 블럭 하나하나씩 자세하게 설명한다.
3.2.1 Patchify
원본 Pixel을 Encoder를 통해서 latent domain으로 변환한 뒤에 Patchify 모듈을 활용하여 이미지를 input의 patch embedding sequence로 변환한다. 이때 patch size parameter $p$를 활용하여 입력값 $I \times I \times C$를 $T = (I/P)^2$ 길이의 입력으로 변환한다. 이 p의 설정에 따라서 동일한 Parameter 개수를 사용해도 Gflops는 굉장히 많이 달라지기 때문에 저자들은 parameter count는 제대로 된 scale factor가 될 수 없다고 주장한다.
3.2.2 Dit block design
위 Figure에서 볼 수 있듯이, 원본 노이즈가 포함된 latent 이외에도 Timestep t 나 Class label c를 Conditional Information으로 받아 이미지 생성에 사용한다. 저자들을 이 정보들을 사용하는 방식에 따라 4가지 서로 다른 Block Design을 제안한다.
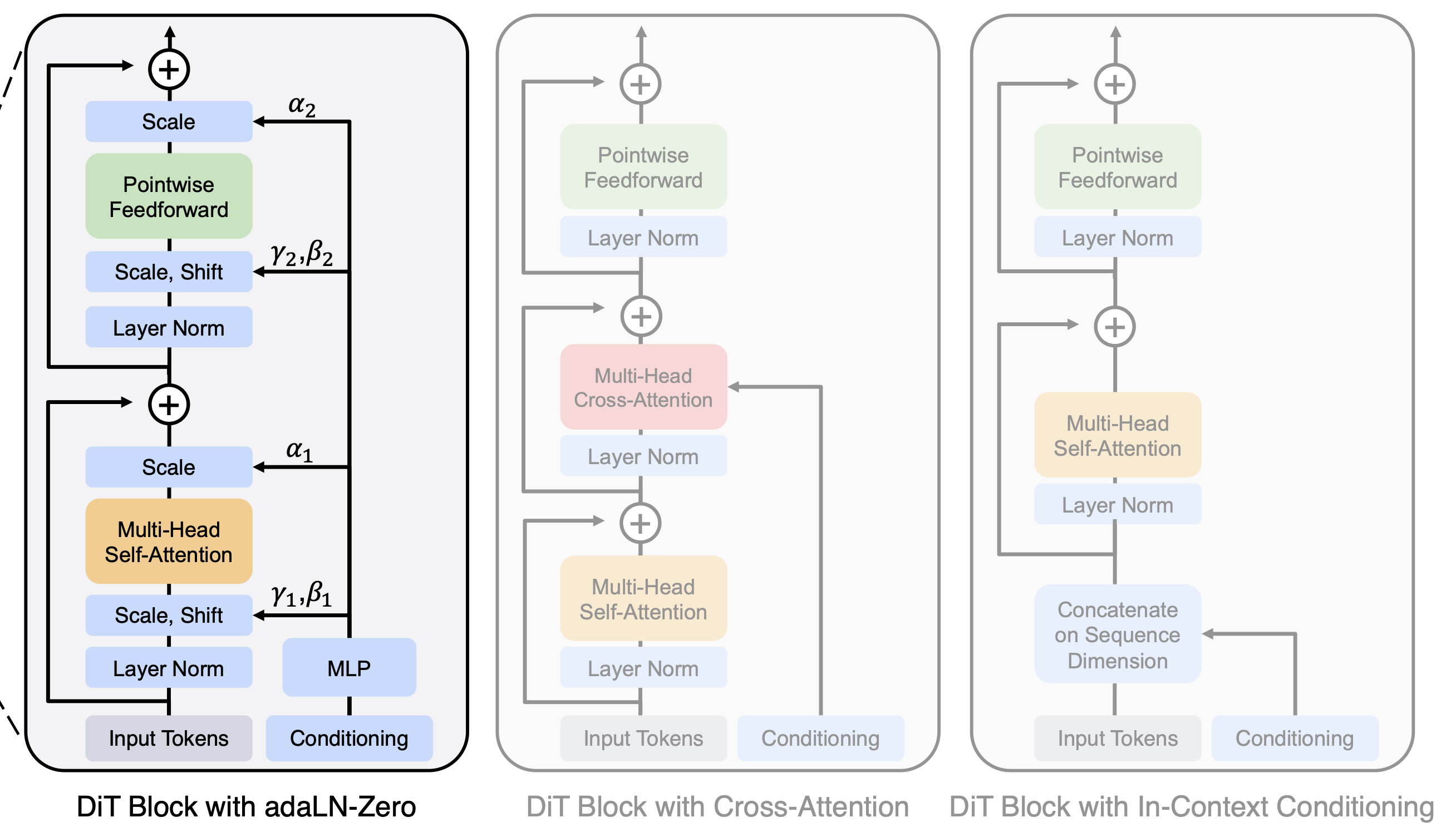
In-context Conditioning
t,c를 Additional Token으로 사용함.- 추가적인 Token으로 처리하다가 마지막 Layer에서 제거함.
- 전체적인 GFLOPS에는 영향을 미치지 않음.
Cross-attention Block
t와c를 추가적인 길이를 가진 sequence로 생각함.- MHSA 이후 Cross Attention에 이 정보를 사용함.
- 15% 정도의 추가적인 GFLOPS overhead 사용
Adaptive layer norm (adaLN) Block
- Condition 처리 부분에 Two Layer MLP로 구성하고 SiLU Activation을 적용함.
- Output dimension은 256 크기가 된다.
- Condition을 $\gamma$와 $\beta$ 파라미터로 변환하고 이 값을 사용하여 Feature Wise Linear Modulation(FiLM 참고)을 진행한다.
adaLN-Zero Block
- 다른 연구들을 참고하여 Residual Block을 Identity Function으로 처리할 수 있도록 함.
- 위에서 언급했던 $\gamma$와 $\beta$ 이외에도 dimension-wise regressing $\alpha$를 추가적으로 생성함.
- $\alpha$값을 초기에 0으로 설정하여 Residual Block을 Identity Block으로 동작하도록 함.
3.2.3 Transformer Decoder
Transformer의 최종 output을 앞서 이야기한 것처럼, Noise $\varepsilon_{\theta}$와 Variation $\Sigma_{\theta}$에 해당하는 두개의 값을 생성해 주어야 한다. 이를 위해서 final layer norm을 적용한 이후 $p \times p \times 2C$의 Tensor를 생성하도록 한다. 이후 이를 분할하여 Noise와 Variation으로 사용한다.