
1. Abstract
전역적인 KV Cache 굥유가 LLM 추론을 가속화했지만, 이전에 공부한 I Know What you Asked Prompt Leakage via KV-Cache Sharing in Multi-Tenant LLM Serving과 같은 timing을 side channel information으로 활용하여 공격하는 기법이 새롭게 대두되었다. 다만, 현재 존재하는 방어 기법들은 time-to-first-token(TTFT) 성는을 38.9%까지 감소시킨다는 단점이 있어. 실제로 사용하기에는 무리가 있다.
저자들은 SafeKV 방법론을 도입하여 non-sensitive 입력은 공유하되, sensitive 입력은 private cache에 넣어 처리하도록 했다. 이 SafeKV 방법론은 privacy detector, unified radix tree index, entropy based access monitoring으로 구성된다고 한다.
결론적으로 해당 방법론을 사용하면 94~97% 정도의 timing-based side-channel attack을 방어할 수 있고, TTFT는 40% 정도의 향상을, throughput은 2.66x배 향상을 이루어냈다고 한다.
2. Introduction
앞서 여러 논문들을 읽으면서 llm 추론 과정에서 중간 Tensor인 Key와 Value 값을 활용하는 KV Caching 방법이 request 처리량을 굉장히 높여주었다는 것을 확인할 수 있었다. 추가적으로 여러 실증적인 연구들이 실제 프롬프트들이 prefix-level이나 중복 구조를 보임을 확인시켜주었다.
다만 성능상의 이점에도 불구하고 KV cache sharing은 다중 사용자나 공유 deployment 과정에서 중대한 보안 문제를 야기한다. 실제로 여러 연구들에서 잘 구성된 prompt들과 해당 prompt들의 응답 순서 등을 정보로 하여 Token-wise prompt reconstruction을 진행할 수 있음을 보였다. 이 방법들은 일반 사용자와 동일한 권한으로 공격이 가능하고, 유출되는 데이터는 굉장히 민감한 데이터이기 때문에 반드시 다루어야 하는 문제이다.
위에서 다룬 방법이 PromptPEEK 방법론이며, The early bird catches the leak: Unveiling timing side channels in llm serving systems 논문에서는 더 넓은 범위에서의 캐싱 방식에서 timing 기반의 유출을 밝혀내여 이 위협의 적용 가능성을 확장한다. (이 논문도 다루어볼 예정이다.)
2.1 SafeKV Introduction
논문에서 제안하는 SafeKV는 보안과 효율성을 동시에 추구하는 LLM 추론 방법이다. timing 기반 기존의 공격에 대응하기 위한 방법들 중 하나로 user cache isolation을 강하게 규제하는 방법이 있지만, 효율성이 떨어진다는 문제가 있다. 따라서 SafeKV는 선택적인 재사용 전략을 사용한다. 다시 말해서 cache block creation에서 각 시스템은 민감 정보인지, 재사용 가능한 정보인지를 판단하고, 재사용 가능한 정보만을 cross-user reuse에 활용한다는 전략이다. 이 방법론을 통해서 사용자들 사이의 보안 경계를 강화하는 한편, 성능 이점도 가져갈 수 있다고 한다.
다만, SafeKV 방법론은 3가지 도전 과제가 있다.
Challenge 1: Accurate and Efficient Privacy Classification.
입력 받은 prompt 중에서 어떤 정보가 민감한지 아닌지를 판단하기 위해서 정확하지만 효율적인 전략이 필요하다. Rule-based 방법을 사용한다면 cost는 줄일 수 있겠지만, Recall 값이 낮아지고deep-learning 방법을 사용한다면 정확도는 높아지겠지만 지연 시간이 늘어난다는 단점이 있다.
Challenge 2: Risk Mitigation under Imperfect Detection.
시스템이 완벽하게 개인 정보를 필터링할 수 없는 것이 사실일텐데, 이런 leakage를 어떻게 감지하고 대응할 것인가가 중요한 과제이다.
Challenge 3: Scalable Cache Lifecycle Management
Cache 재사용을 최대화하되, 보안을 가져가기 위해서 어떻게 private cache와 shared cache를 구성할 지가 중요한 포인트이다.
SafeKV는 위 세가지 도전 과제를 풀어 개인 정보 보호와 높은 추론 성능을 확보했다고 한다.
3. Background
Background에서 기존 논문들에서 읽었던 내용들이 상당 수 중복되어 있어 새로운 내용만 정리했다.
3.B KV Cache Sharing

위 Table 1에서 확인할 수 있듯이 대부분의 LLM Framework들은 Prefix Caching들을 차용하여 KV cache를 공유한는 정책을 사용하고 있다.
3.C Timing Side-Channel Attack
KV Cache 공유가 추론 성능을 굉장히 끌어올렸지만, 미묘하지만 중요한 위험성을 낳게 되었다. timing side channel을 사용한 token reconstruction이 그 위험성이다. 더 자세히는 time-to-first-token(TTFT)을 사용하여 응답 지연을 측정하고, 낮은 지연 시간이면 Gpu cache 안에 해당 토큰이 존재한다는 의미로 판단하여 Probe-Detect-Reconstruct 과정을 거쳐 Prompt를 재생성해나간다.
이는 정확하게 정확하게 맞는 Prefix만을 재사용하는 정책뿐만 아니라 GPTCache와 같이 의미적으로 비슷한 input에 대해서도 지연 기반 유출이 가능하다는 문제가 있다. 또한 별도의 특권 없이도 이러한 공격이 가능하다는 점에서 LLM 서비스 과정에서 효율성과 안전성 사이의 Tradeoff가 발생하도록 한다.
3.D Motivation
a) The Risk of KV-Cache Leakage
실제로 C4 데이터셋과 Pile데이터셋에서 방대한 양의 프라이버시 데이터가 존재하기 때문에 이런 데이터를 통해서 학습된 내용이 실제로 KV 값에 실릴 확률이 높아지고, 추론 과정에서의 KV Cache를 통한 유출은 현실적이다라고 주장한다.
b) Performance Impact of Full Isolation
물론, 보안을 확실하게 지키는 방식은 KV Cache 다중 사용자 간에 공유하지 않도록 하는 것이다. 하지만, 이것은 굉장히 비효율적이다. 결과적으로 동일한 prefix로 방대한 양의 저장공간이 채워지고 multi-tiered 메모리 위계에서 메모리 효율성을 낮추게 된다.
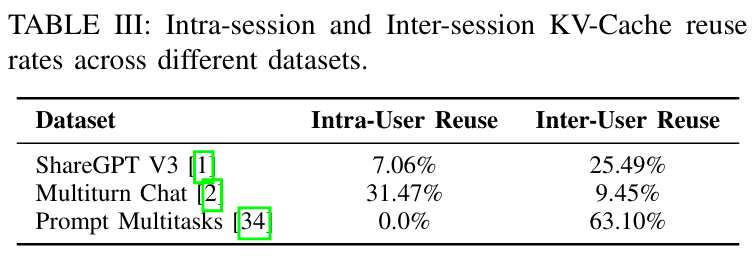
위 테이블을 통해서 다중 사용자 간의 KV 값을 공유하지 않는 것이 얼마나 비표율적인지를 더욱 잘 확인할 수 있다. Intra-User 재사용률보다 Inter-User 재사용률이 훨씬 높기 때문에, 다중 사용자 간의 KV 값 공유는 반드시 필요하다.
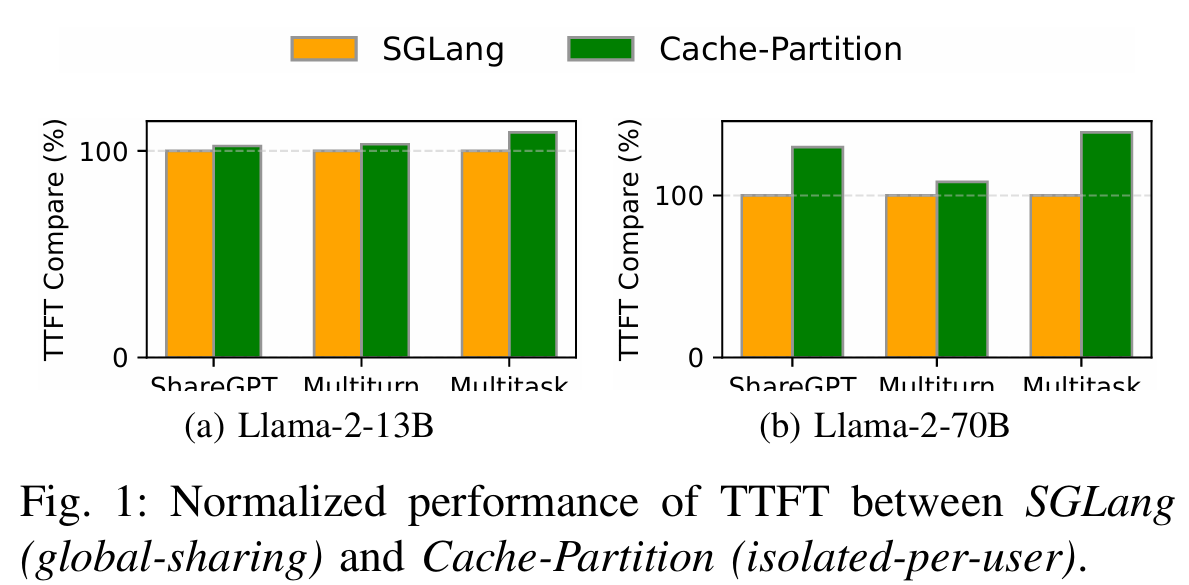
논문에서는 추가적으로 실제로 다중 사용자 간의 Cache를 공유하지 않는 경우와 공유하는 경우 간의 TTFT 값을 비교해보았다. 결과적으로 작은 모델에서는 2.3~8.9%의 성능 향상, 큰 모델에서는 8.3~38.9%의 성능 향상을 확인할 수 있었다고 한다. 따라서 저자들은 어떤 값이 민감한지 민감하지 않은 지를 구분하여 선택적으로 처리하는 SafeKV 방법론을 제안하여 공유 캐시의 효율성과 보안의 두가지 이점을 모두 균형적으로 고려할 수 있다고 한다.
4. Threat Model
4.1 System Model
6. SafeKV Cache: Privacy-aware cache management
SafeKV 방법론을 실제로 구현하기 위해서는 KV값을 효율적으로 공유하되, 엄격한 개인 정보 경계를 지켜야 한다. 추가적으로 multi-tier storage coordiation이나 efficient memory reclamation도 현실적으로 다루어야 한다고 한다. 이러한 목적을 달성하기 위해서 SafeKV는 통합된 하나의 트리 기반 Cache index를 사용하되, Private / Public 정보를 추가로 담는다. 추가적으로 개인정보로 판별된 개체에 대한path-aware memory optimization, progressive eviction strategy를 통해서 실제 KV를 관리한다고 한다.
6.1 Unified Privacy-Preserving Cache Index
메모리 효율성과 개인정보 격리를 위해서 SGLang 논문에서 제안한 것과 같이 radix tree를 기반으로 구현했다. 다만, 일반적인 radix tree를 그대로 사용하는 것이 아니라 private block과 public block을 모두 한번에 처리할 수 있는 확장 가능하고 개인정보를 고려하는 위계 구조를 도입하여 개선을 이루어냈다고 한다.
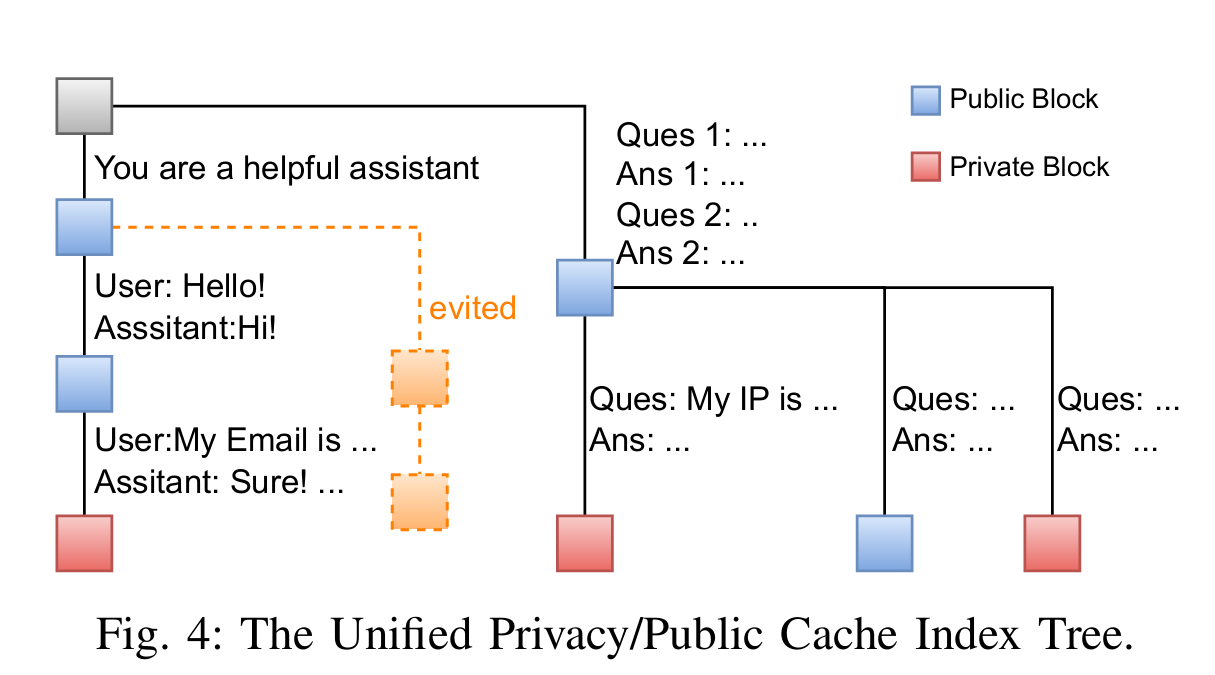
위 Figure 4를 통해서도 확인할 수 있듯이 개인정보로 분류된 block과 공유 block으로 분류된 block 전부 동일한 Radix-tree로 표현된 것을 확인할 수 있다. 각각의 노드는 private_tag와 creator_id 정보를 통해서 Cache loopup 과정에서 미세한 각 사용자의 접근을 통제한다.
private_tag가 0인, 즉 public으로 판별된 block은 모든 사용자가 사용할 수 있고, private_tag가 1, 즉 private로 판별된 block은 creator_id가 동일한 사용자만 해당 block을 다시 사용할 수 있도록 하여 접근을 조절하게 된다.
Insert: Decoding 과정을 거치고 난 이후에 Prefix를 계산하여 RadixTree에 추가된다.Search: 저장된 Cache를 Loopup하는 과정은 Radix Tree를 순회하는 방식으로 동작한다. 더 자세히는private_tag를 통해서 순회하게 되는데,private_tag == 0이라면 모든 사용자가 해당 node를 사용할 수 있게 해주고,private_tag == 1이라면creator_id == query user