Seq2Seq 정리
- Deepfix와 BIFI 논문을 읽다 보니 Seq2Seq 구조를 비롯한 RNN의 기본 구조를 명확히 이해하고 있어야 한다는 생각이 들어 RNN의 기본에 대해서 공부할 예정이다.
- 이번 포스트는 위키독스 NLP를 참고하여 정리한 내용이다. **
Context
- Seq2Seq 모델
- Seq2Seq 모델 사용
- Seq2Seq Training
- Seq2Seq Testing
- Embedding Layer
- Softmax function
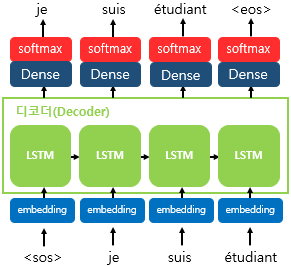
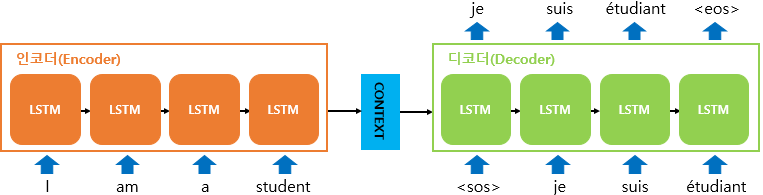
Seq2Seq 모델
Seq2Seq 모델은 크게 Encoder, Decoder module과 그 사이를 연결해주는 Context Vector로 이루어져 있다. Encoder는 입력 문장 단어들을 순차적으로 입력 받아 Context Vector를 생성하는 역할을 하고, Decode는 입력받은 Context Vector를 바탕으로 출력을 순차적으로 진행한다.
Encoder와 Decoder의 구조
Encoder와 Decoder 모두 RNN 아키텍처를 기반으로 한다. RNN 중에서 Vanishing Gradient 문제를 해결하기 위해 기억하는 비율을 조정하는 LSTM과 GRU 기반으로 구성된 Encoder나 Decoder가 사용된다.
Encoder의 입력에는 token화된 입력 데이터들이 들어가게 되고, 각 토큰들은 Encoder Cell에서의 특정 시점에 해당하는 입력으로 활용된다.
인코더와 디코더 모두 RNN Cell을 기반으로 구성되어 있기 때문에, Hidden state의 개념이 사용된다. 현재 시점이 t라고 가정하면, LSTM이나 GRU의 Input값으로 이전 시점 t-1의 hidden state와 input (token)값이 사용되고, 현재 시점 t의 hidden state를 생성하게 된다. 다음 시점 t+1에서 시점 t의 hidden state가 또다시 사용되는 방식으로 구성된다.
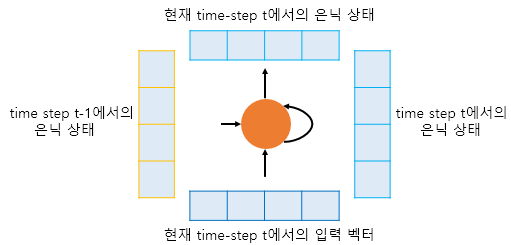
DeepFix 논문에서 등장한 Cell이 stacked GRU등등이 쓰였으므로, Cell이 Stacked된 형태로 사용된 것을 추후에 공부할 예정이다.
Context Vector
Attention기법을 사용하거나 기본적인 Encoder-Decoder 구조에서는 다른 방식으로 사용되겠지만, 특점 시점에서 생성되는 hidden state는 이전 시점까지의 동일한 RNN Cell에서의 모든 hidden state 정보에 영향을 받는다고 볼 수 있다.
다른 기법을 사용하는 경우 Context Vector는 다른 형태일 수 있지만, Context Vector는 마지막 시점에서의 Hidden state를 사용하여 Decoder에게 넘겨주는 형태를 사용한다고 가정했을 때, Context Vector는 이전 시점의 hidden state의 정보를 전부 반영하는 것이므로, 모든 토큰에 대한 정보를 요약해서 담는 것이라고 볼 수 있다.
결국, 이 정보를 이용하여 Decoder의 정답 생성에 활용할 수 있는 것이다.
Seq2Seq 모델 사용
Seq2Seq 모델은 Training 단계와 Test 단계에서 동작하는 방식이 다르다.
-
Seq2Seq 모델 Train
훈련 과정에서는 Decoder에 디코더로부터 출력된 Context Vector와 정답를 입력받고, Decoder를 훈련하는 방식으로 훈련을 진행한다. 이는 교사강요에 사용된다.
교사강요
Training 과정을 생각해보자. Decoder의 작동 방식은 이전 시점의 정답이 다음 시점의 입력값으로 활용되는 형태를 보이므로, 훈련 과정에서도 동일한 방식을 사용하게 된다면, Training의 특성 상 오류가 발생할 가능성이 높고, 오답지를 계속해서 사용한다면 이후 시점에 입력되어야 하는 값또한 오류가 발생하는 것이기에, 학습이 매우 더디게 진행될 것이다.
이를 방지하기 위해 사용하는 방법이 교사강요이다. 교사강요는 위의 현상을 방지하기 위해서 Decoder의 Input을 추가로 제공하여 학습이 빠르게 진행될 수 있도록 하는 것이다. 결국 Training단계에서는 Encoder의 Context Vector, Decoder의 Input, Decoder의 Output을 제공해야 한다.
-
Seq2Seq 모델 Test
RNN을 기반으로 하는 Decoder 모델은 Encoder에서 생성한 Context Vector와 </SOS/>를 첫번째 시점의 hidden state와 input로 받아서 연속적인 정답을 생성해낸다. 첫번째 시점의 정답지를 두번째 시점의 input으로, 첫번째 시점의 hidden state를 두번째 시점의 hidden state 입력으로 받아 사용할 수 있게 된다. 이를 연속적을 반복하여 정답지가 </EOS/>가 나올 때, 생성을 중지하는 방식으로 Test 과정이 진행되는 것이다.
Embedding Layer
사람의 경우 숫자와 텍스트를 전부 잘 이해할 수 있지만, 기계의 경우 기본적으로 숫자를 다루는 것이 문자를 다루는 것보다 훨씬 더 성능이 좋다. 따라서 자연어 처리의 경우, Text Data를 Vector로 바꾸는 워드 임베딩 방식이 주로 사용된다.
결국, input 정보가 text인 경우가 많기에, 입력층에 Embedding Layer를 추가해 텍스트를 숫자처럼 다룰 수 있게 해주어야 한다.
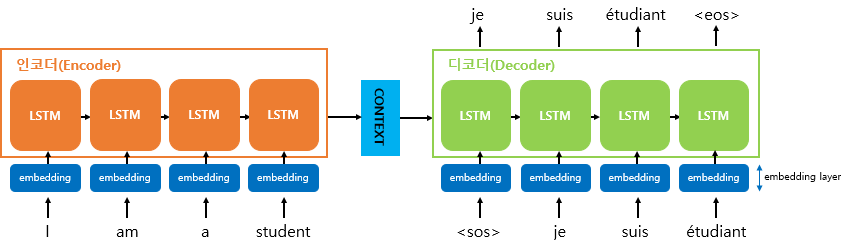
Deepfix 논문에서 입력층을 one hot vector로 변환한 이후 Embedding을 진행했는데, 이에 대해서 더 공부하고 정리할 예정이다.
Softmax function
Decoder에서 출력할 단어를 예측하는 과정에서 Softmax function이 쓰인다. 최종 출력값을 예측하는 과정에서 Greedy Search나 Beam Search등등을 사용하려면, 확률값을 알아야 한다. 이를 위해서 선택할 수 있는 모든 단어들의 각 시점에서의 확률을 구하는 함수를 사용해야 하는데, 이때 쓰이는 것이 Softmax 함수이다.