
Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation
Abstract
ModelScopeT2V 모델의 실험 결과 중에 CLIPSIM 점수가 낮게 나오는 경향을 확인했다. 이 논문에서는 이를 Pixel Based와 달리 Latent Space에서 Diffusion을 진행해서 이와 같은 문제가 발생했다고 보고, Low Resolution에서는 Pixel based Diffusion을, High Resolution에서는 Latent based Diffusion을 진행하는 방법으로 이를 해결하고자 한다. 이를 통해 오로지 Pixel 기반 방법보다 더 효율적이고 Latent 기반 방법보다 Text Alignment가 좋아지는 결과를 확인했다고 한다.
1. Introduction
Pixel Based VDM은 Textual Input과 잘 맞는 Output을 생성할 수 있는데 이것이 낮은 해상도의 Video에서부터 생성을 시작하기 때문이라고 주장한다. 다만, Upsampling 과정에서 메모리가 많이 든다는 문제가 있다.
Latent Based VDM은 연산 효율적이지만, 실제로 이미지를 생성하는 차원이 너무 작기 때문에 시각적 의미를 충분히 담을 만큼의 공간이 없다고 주장한다. 추가적으로 직접 High Resolution의 Video를 생성하는 것은 오히려 Text Alignment를 떨어뜨린다고 한다. 이에 대해서는 Latent Model이 Spatial Appearance에 집중하고 Text-Video Alignment를 간과하기 때문이라고 한다.
따라서 두 방법의 장점만 합쳐 Low Cost이면서 Video-Text Alignment를 향상시키는 것을 도모한다고 한다.
저자들을 실험을 통해서 Low Resolution KeyFrame에서 시작하여 Frame Interpolation과 SuperResolution을 진행하는 과정이 효과가 좋다고 한다. 이 부분에서 최초의 Keyframe을 작게 생성하는 것이 왜 높게 생성하는 것보다 더 좋은 지에 대한 분석이 필요하다고 본다. 이후에 Keyframe에서 시작하여 최종적인 영상을 생성하기 위해서 Latent Diffusion을 사용한다고 하는데, 이때 기존의 모델을 그냥 사용하는 것이 아니라 Noisy low resolution video를 직접 인코딩하여 Upsampling에 사용하는 방식을 사용했다고 한다.
2. Related Work
자명한 내용
3. Show-1
3.1 Preliminaries
- DDPM 논문
-
UNet
Text-to-image Diffusion을 위해서 주로 UNet 구조에 대한 변형을 많이 사용한다. DALLE-2 / GLIDE 논문에서는 Residual Block에 Global Information을 넣고 Self Attention 과정의 Attention Matrix에 특수한 토큰에 대한 정보를 추가하여 텍스트와의 정합성을 맞춤.
다만 이 논문에서 본 UNet구조는 Stable Diffusion을 가정함. 각 Residual Block 이후에 Self attention, 그리고 Cross Attention을 차례로 진행하는 구조를 가정함.
3.2 Turn Image UNet to Video
UNet은 기존의 Image를 위한 구조였기 때문에 이를 Video 도메인으로 확장하는 과정이 필요하다. Stable Diffusion을 사용한 이전의 ModelScopeT2V 구조에서 BottleNeck 부분에 Spatial Conv -> Temporal Conv -> Spatial Attention -> Temporal Attention으로 확장했었는데, 이를 일반적인 해상도로 확장하여 각 Resolution에 대해서도 진행할 수 있도록 해준다.
더 자세한 구조는 아래와 같다. ModelScope 논문과 다른 점은 Spatial Attention 부분의 Self Attention과 Cross Attention 순서가 다르다는 점 뿐이다.
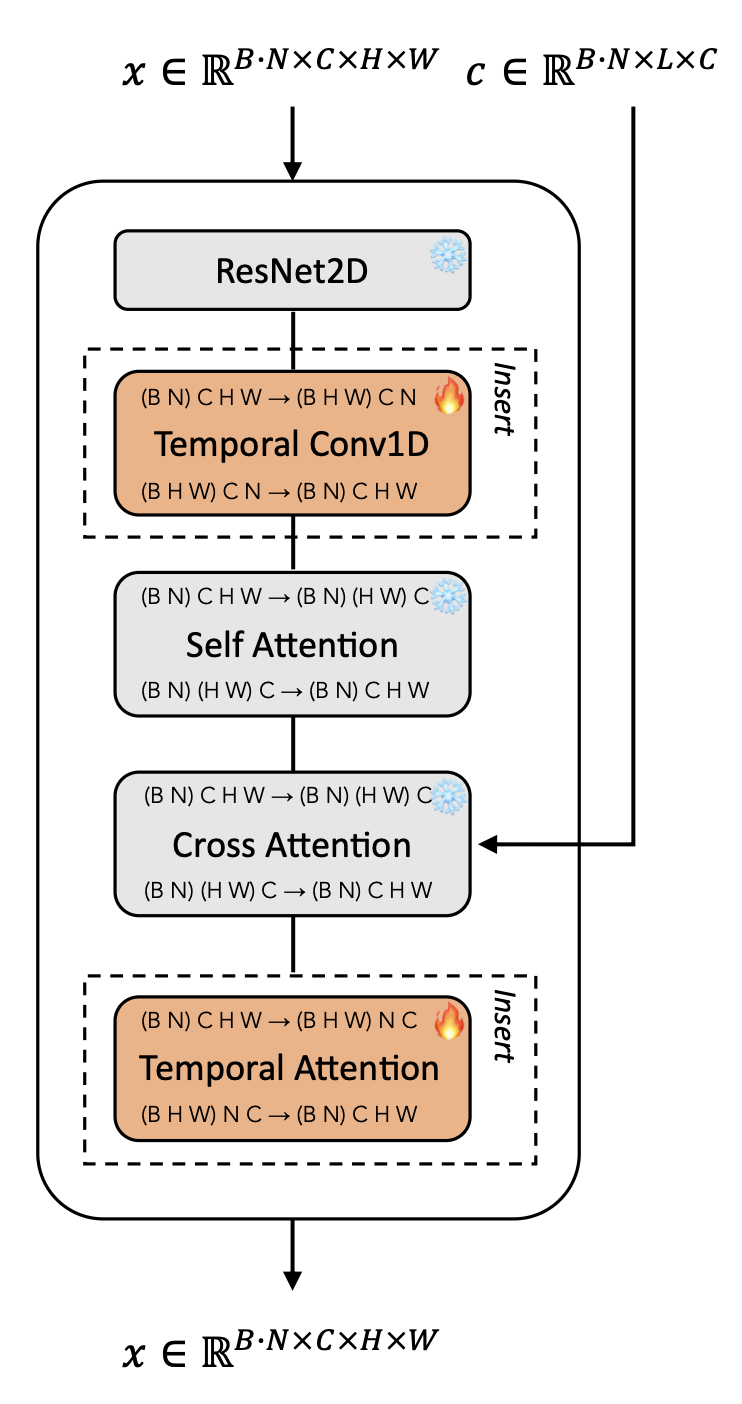
이전의 논문들과 동일하게 Spatial Attention을 진행할 때는 Temporal 축을 Batch처럼 다루고, 반대로 Temporal Attention을 진행할 때에는 Spatial 축을 Batch처럼 다룬다는 점을 기억해야 한다.
3.3 Pixel-based Keyframe Generative Model
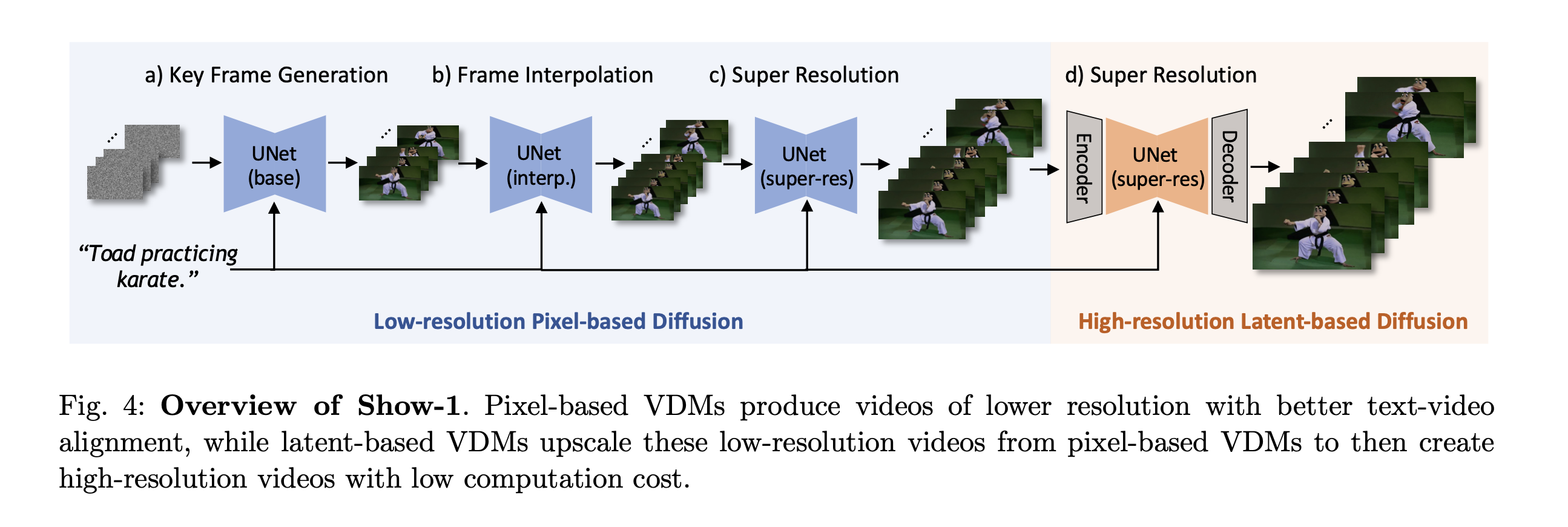
앞선 Introduction에서 설명한 것과 동일하게, 처음 부분은 Frame도 낮고, 해상도도 낮은 영상을 Pixel-based Diffusion Model로 생성하는 과정을 거친다. 저자들은 이 과정이 T2V Alignment를 높이는 방법이라고 소개했는데, 그 이유로 해상도가 낮기 때문에 겉보기에 깔끔해질 필요가 없고 프레임도 낮기 때문에 시간 축으로 보았을 때도 일정할 필요가 없다고 주장한다.
Low Resolution의 Keyframe을 왜 PixelBased Diffusion으로 생성하는지에 대해서 나머지 방법들이 좋지 않기 때문이라고 한다. Low resolution을 Latent diffusion으로 생성하는 과정은 Latent로 더 작게 표현한다면 표현 능력이 현저히 떨어지기 때문에 불가능하다고 하고, 그렇다고 latent 차원을 높인다면 차라리 pixel based를 사용하는 것이 좋다고 한다.(추가적인 AE 필요) 또한 그냥 바로 High Resolution을 사용하는 것에 대해서는 실험을 통해서 확인했을 때 spatial apperance에 집중하느라 텍스트와의 정합성을 놓치게 된다고 한다.
3.4 Temporal Interpolation Model
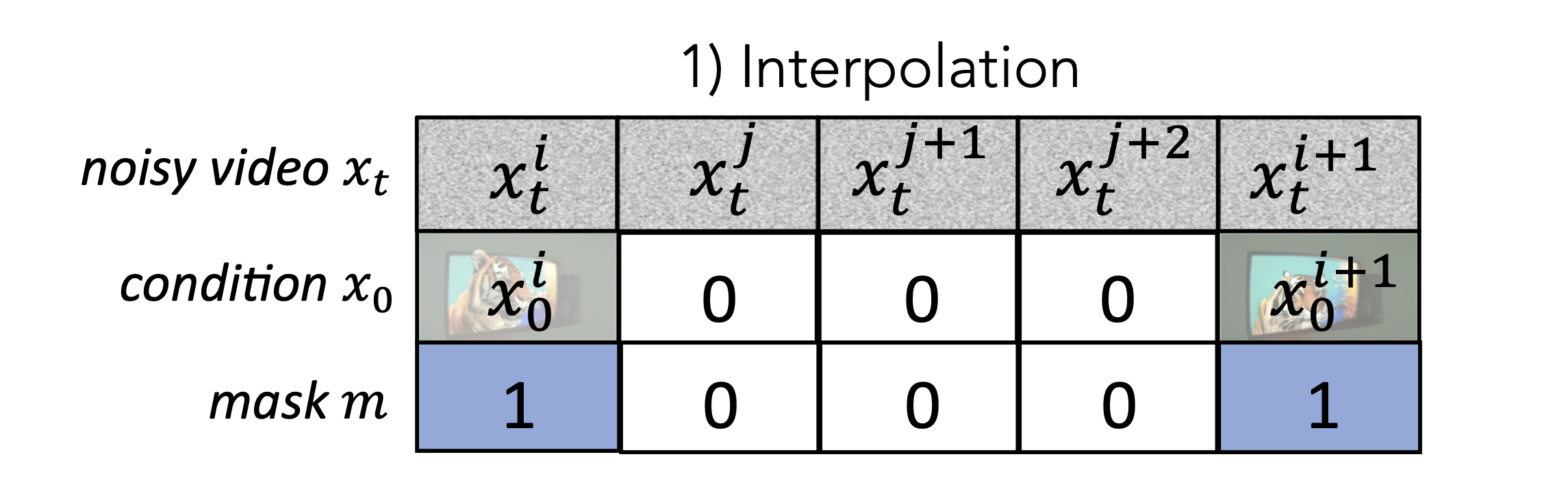
앞서 설명한대로, Low Spatial Resolution / Low Frame Rate에서 KeyFrame을 생성한 뒤, Pixel based diffusion model을 활용하여 Frame Interpolation 과정을 진행한다. 이는 Make-A-Video 논문과 매우 유사한 과정으로 진행된다.
논문에서는 기본적으로 두 Keyframe 사이를 3개의 additional frame으로 채우는 과정으로 진행된다고 한다. 먼저 Input의 구조는 Noisy Video $x_t$와 Condition $x_0$, Mask $m$을 Channel 단위로 Concat한 구조이다.
Noisy Video는 $x_t \in \mathcal{R}^{5 \times C \times H \times W}$ 구조이다. 처음과 끝 Frame은 우리가 Keyframe으로 이미 알고 있는 부분이고, 나머지 중간 3프레임은 우리가 모르는 프레임에 대한 Noise이다. Training 과정에서는 중간 Noisy Input을 Noise Injection 단계에서 알고 있기 때문에 이를 학습에 사용할 수 있고, Inference 과정에서는 앞의 Noise를 받아서 Sequential하게 Inference를 진행한다.
Condition $x_0$ 또한 $x_t \in \mathcal{R}^{5 \times C \times H \times W}$ 구조이다. 처음과 끝 프레임은 저해상도 Keyframe의 값을 그대로 사용하면 되고, 중간의 모르는 프레임에 대해서는 전부 0으로 마스킹한 Input을 사용한다.
마지막으로 Masking 부분은 $x_t \in \mathcal{R}^{5 \times 1 \times H \times W}$ 구조이다. 이는 우리가 보간해야 할 프레임에 해당하면 0을 사용하고 그렇지 않다면 1의 값을 사용하는 구조이다.
결과적으로 Temporal Interpolation Model의 경우에 $\hat x_t \in \mathcal{R}^{5 \times (C + C + 1) \times H \times W}$의 입력을 받아 $x_t \in \mathcal{R}^{5 \times C \times H \times W}$의 출력을 내보내는 구조로 이루어져 있으며, 훈련 과정에서는 아래와 같은 목적함수를 사용함.
\[\mathbb{E}_{\varepsilon \sim N(0, 1), \hat x, x_0, m, t, c}[||\varepsilon - \varepsilon_{\theta}([\hat x_t, x_0, m], t, c)||_2^2]\]3.5 Super-Resolution at Low Spatial Resolution

다음 단계로 Upsampling을 진행해야 하는데 바로 8배로 Upsampling을 진행하게 되면 Spatial Information이 부족해서 제대로 된 결과가 나오지 못한다. 이를 해결하기 위해서 두 단계로 Upsampling을 진행하게 되며 먼저 Spatial Quality를 높이는 과정을 거친다. 이후 Final High Resolution을 만들어낸다.
첫번재 Low Resolution Video Upsampling은 Pixel based diffusion으로 진행한다. 이 과정에서는 이전 단계에서 생성한 이미지를 4배로 Upsampling하는 과정을 거친다. 즉 앞선 단계에서 $x_t^{\prime} \in \mathcal{R}^{4N \times C \times H \times W}$으로 증강한 데이터를 $x_t^{\prime \prime} \in \mathcal{R}^{4N \times C \times 4H \times 4W}$ 크기로 증강하고자 한다.
위의 Figure에서 나온 것처럼 Low Resolution Frame 개별에 대한 Bilinear Upsampling을 진행하고, 이를 Condition에 넣어 $x_t^{\prime \prime} \in \mathcal{R}^{4N \times 2C \times 4H \times 4W}$ Input을 생성하고 $x_t^{\prime \prime} \in \mathcal{R}^{4N \times C \times 4H \times 4W}$ 크기의 Output을 생성하고자 한 것이다.
Training 과정에서는 깨끗한 이미지를 Condition에 넣어주겠지만, Inference 과정에서는 Previous Stage에서 생성한 부정확한 이미지를 바탕으로 해당 과정을 진행해야 하기 때문에, 실제 Training 과정에서는 Random SNR을 넣어서 이 간극을 매꾼다고 한다. 추가로 GPU 메모리 한계로 인하여 한번에 5개의 Frame만 업샘플링을 진행할 수 있는데, 이때 발생할 수 있는 Temporal Consistency Problem에 대해서는 바로 이전에 생성한 마지막 Frame을 그대로 활용하여 총 4개에 대한 새로운 Upsampling을 진행하며 이 불일치 문제를 해결하고자 했다.
3.6 Super-Resolution at High Spatial Resolution

Low Resolution Video를 4배 Upsampling하는 방법대로 최종적인 8배 Upsampling 과정에도 적용하면 이전 단계 출력의 Artifact와 Temporal Corruption이 남아 있는데 이 오류를 수정하지 못해 최종적인 성능이 나빠진다. 이를 해결하기 위해서 기존 SDEdit 방법론에서 아이디어를 얻어 최종적인 Upsampling을 진행하고자 한다.
먼저 우리가 원하는 2배 Bilinear Upsampling을 진행하고 DDPM 노이즈를 추가하여 이 노이즈를 다시 복원하는 과정을 거쳐 높은 해상도의 영상을 생성한다. 더 자세하게는 기존의 Stable Diffusion 논문에서 언급되었던 것처럼 1000회의 복원 과정에 대한 학습이 완료되었다면, 초반 100 Step에서는 Coarse Detail을 복원하는 데에 집중하고 이후의 900 Step에서 Fine Detail에 집중한다는 정보를 바탕으로, Temporal Consistency를 위해 900 단계까지만 노이즈 추가와 복원 과정을 거친다고 한다.
논문에서 굳이 언급하지는 않았지만, 이 과정에서 Sampling을 위해 넣어주는 노이즈는 Deterministic하지 않은 Stochastic Noise가 더 자연스러울 것이다. 만약 DDIM의 Deterministic Sampling / Noising을 진행한다면 이는 SDEdit의 시각에서도 맞지 않고 그저 Bilinear Interpolation이 진행된 결과를 생성해 내게 될 것이다.
SDE와 ODE DDIM을 다시 한번 정리하면 아래와 같다.
Diffusion 과정은 SDE로 표현이 가능하다. 각 step에서의 marginal probability $p_t(x)$ 자체는 동일하지만 실제 trajectory는 다른 ODE로의 변환이 가능하다. 이는 초기의 $x_T$값이 정해져 있다면 언제나 동일한 값으로 나온다는 의미이다. SDE는 반면에 이 Mapping 자체는 불가능하지만 각 시점에서의 marginal probability 자체는 동일하다.
여기에서 주의해야 할 점은 이론적으로는 Mapping이 가능하지만 실제 구현 과정에서의 오차로 인해 완벽한 이론적인 대응은 불가능하다. 즉, 동일한 $x_T$를 바탕으로 동일한 Solver를 사용한다면 ODE는 동일한 값을 나타내지만 이 Solver에 따라서 서로 다른 값을 나타낼 수 있게 된다.
DDIM또한 비슷한 과정이다. Probabilistic Flow를 이산화한 과정이므로 초기값이 동일하다면 denoising 결과도 완전하게 동일한 값을 가진다.
4. Experiments
VBench라는 새로운 벤치마크 사용.
4.4 Ablation Studies
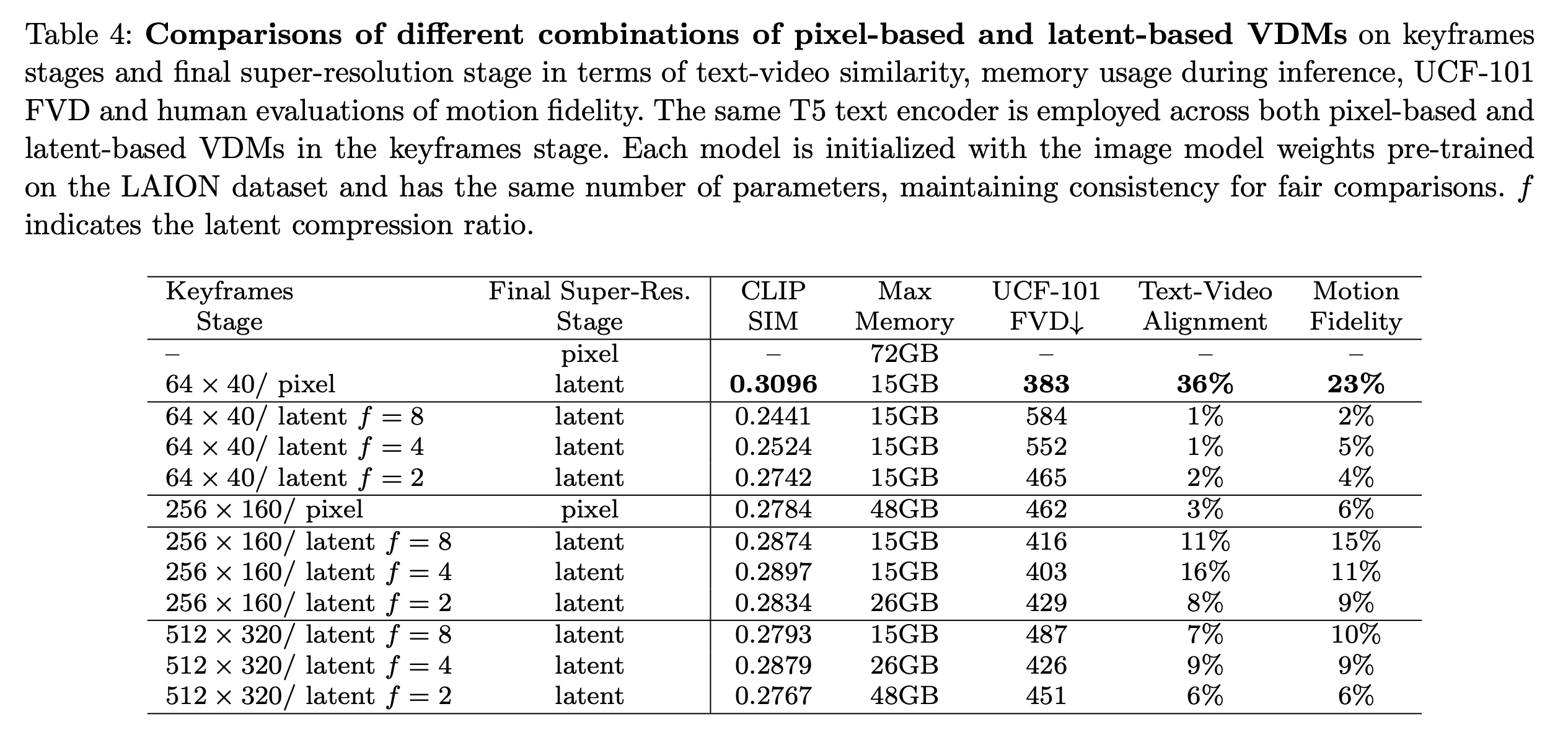
저자들은 위와 같은 다양한 초기 Keyframe들을 바탕으로 비교하며 Low Resolution에서부터 순차적인 Upsampling을 진행하는 과정이 가장 좋은 효과를 보인다고 언급한다. 추가로 High Spatial Resolution을 사용하여 생성을 진행하는 경우 오히려 Text와의 정합성이 낮아진다고 언급하는데, 이를 spatial appearance에 집중하는 양상으로 인한 것으로 주장한다. 다만 이는 Latent Space에 대해서만 언급했다. 실험 결과를 통해서 증명했지만 Coarse-to-fine Sampling이 좋은 성능을 보임을 주장한다.
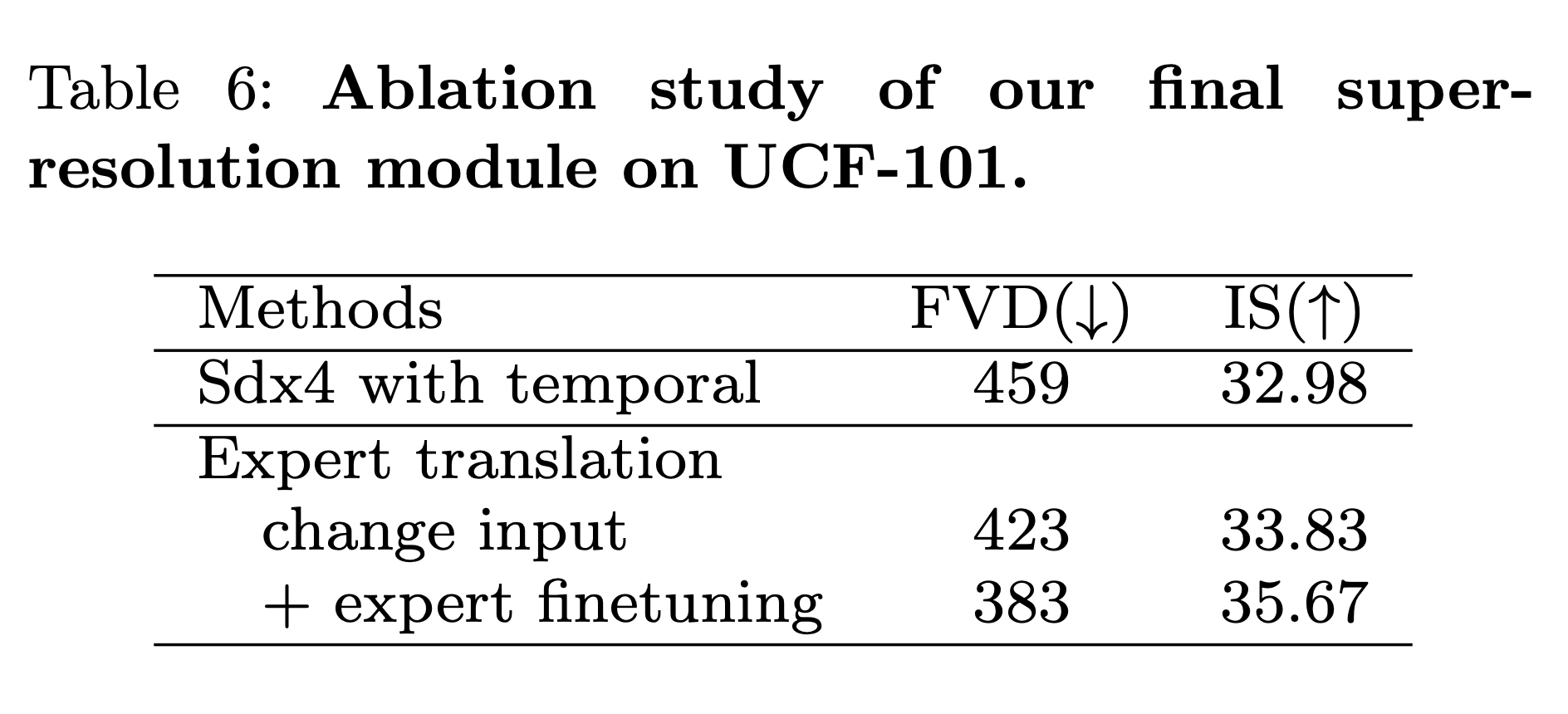
추가적으로, 위와 같이 Expert Translation의 효과도 비교한 실험이 있다. Input 구조를 바꾼 것과, High Frequency에 집중하여 영상 생성을 진행한 것 모두 효과가 있음을 보였다.