
Video Generation
2.1 Pioneering Works
T2I Model과 T2V Model의 가장 큰 차이점은 무엇보다도 Output이 2D에서 3D로 바뀌며 Temporal Axis(Frame) 이 추가된다는 점에 있다. 이전의 연구에서도 3D Convolution을 아주 빈번하게 사용했기 때문에, 이를 바탕으로 자연스럽게 Convolution을 진행할 수 있지만, 마지 Depth-Wise Convolution 연산과 비슷하게 Spatial Convolution 이후 Temporal Convolution을 진행하는 방식으로 사용한다.(Make-A-Video)
추가적으로 Attention Layer에 대해서도 Spatial Attention 이후 Spatial을 마치 Batch처럼 처리하여 Temporal Attention을 진행하는 식으로 확장하는 과정을 거쳤다. 또한, Video를 한 번에 생성하는 것은 힘들기 때문에, Cascaded Generation을 사용하여 순차적으로 Video를 생성하는 방식을 차용했다.
Make A Video에서는 먼저 Image에 대해서 학습을 진행하고, 앞서 말한 Temporal Conv나 Temporal Attention Layer를 추가한 뒤에 Video Data로 Fine Tuning을 진행한다.
Nvidia에서는 Latent Diffusion Model (Stable Diffusion)을 활용하여 3D로 확장한 방식이 있다. Align your Latents : High Resolution Video Synthesis with Latent Diffusion Models
2.2 Open Source Video Models
2.2.1 ModelScopeT2V
- Pretrained Weight을 유지하면서 Stable Diffusion을 3D로 확장함.
- 이 구조에서도 Temporal Convolution과 Temporal Attention을 사용함.
- 이때 $1 \times T$만큼의 시간축을 보기 때문에 $T$를 1로 설정하여 이미지를 학습할 수 있음.
- ModelScope 모델은 꽤나 좋은 성능을 보였지만, Watermark가 Training Dataset에 포함된 문제가 존재해서, ZeroScope이라는 Watermark를 제거한 영상을 생성하는 모델을 이용하여 이 문제를 해결함.
2.2.2 Show-1
- 앞서 만든 ModelScope 모델과 같은 경우 영상을 그럴듯하게 생성해 내지만, Text Video Alignment가 부족하다는 문제가 존재했다.
- Video-Text Alignment Problem의 원인을 살펴보니, Pixel Based Model의 경우에는 제대로 Align이 가능했지만, Latent Diffusion 모델의 경우 정합성이 매우 떨어지는 것을 확인했다고 한다.
- 위 문제를 해결하기 위해서 Low Resolution Stage에서는 Pixel-Based VDM을, High Resolution Stage에서는 Latent-based VDM을 사용했다고 한다.
2.2.3 Stable Video Diffusion
- Lavie와 같은 모델이 굉장히 큰 양의 데이터셋을 생성하여 생성 품질을 높임.
- Stable Video Diffusion 모델의 경우도 방대한 데이터를 생성하고 정제해서 학습 효율을 높임.
- Stable Video Diffusion의 학습 과정은 아래와 같이 정리할 수 있다.
Image Pretraining: Stable Diffusion 2.1 모델을 사용하여 Pretraining 이후 3D 변환.Curating a Video Pretraining Dataset: LLM에서와 마찬가지로 Pretraining 진행.High Quality FineTuning: 앞에서 진행한 데이터에서 정제하여 High Quality Video Data를 생성하고 해당 데이터셋을 활용하여 High Resolution T2V, I2V Generation Task에 활용함.
2.3 Other Closed Source Works
2.3.1 Lumiere
Google에서 생성한 모델로, 비디오 생성 과정에서 Temporal Super Resolution을 진행하는 것이 아니라 Space-Time Diffusion Model을 활용해서 한번에 Temporal Data를 늘리는 과정을 거쳤고, 이를 통해서 Temporal Consistency를 높이는 결과를 보여준다고 한다.
이 논문에서도 역시나 동일하게 Convolution-based Inflation Block과 Attention-based Inflation Block을 사용하여 기존에 Pretraining한 T2I 모델의 파라미터를 추가로 학습하지 않고 효율적인 학습이 가능.
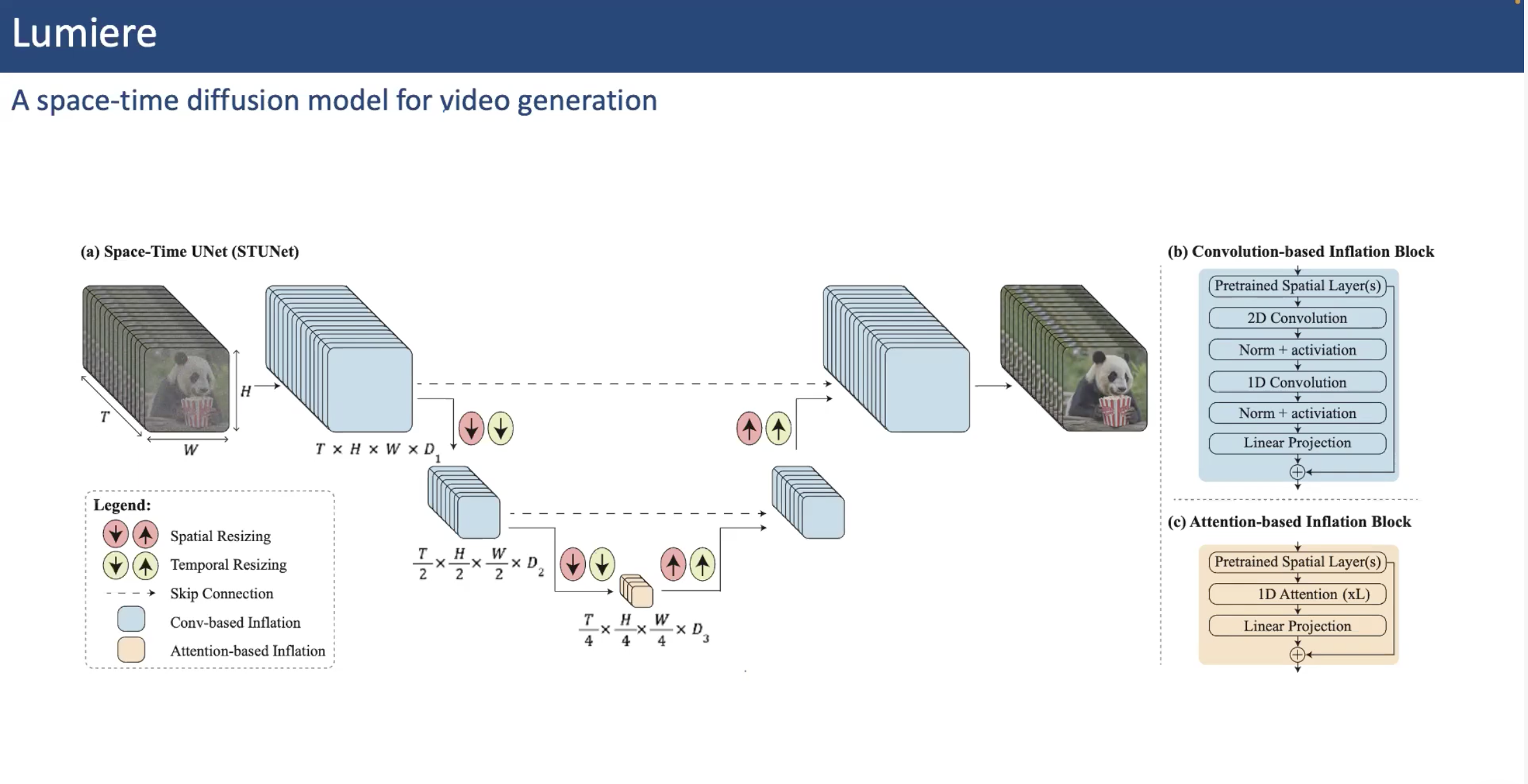
Transformer-based Video Diffusion Models
2.3.2 GenTron
Diffusion Model을 Transformer Architecture를 활용하여 구현함. Scalable Diffusion Models with Transformers 논문에 해당하는데, 해당 논문은 Image Diffusion이고, Gentron은 Video Diffusion을 Transformer Architecture로 구현함.
- Problem in T2V Quality
- Data Limitation : T2I Data에 비해 T2V Data가 굉장히 작음 / 데이터의 품질 또한 좋지 못함.
- Fine-Tuning Focus : T2V Fine Tuning 과정에서 Spatial Visual Quality를 높이기 위해 노력하는 과정에서 Video 품질이 낮아지는 문제가 발생함.
- Solution to Enhance T2V Quality
- Joint Image-Video Training : Domain Discrepancy 상쇄를 위한 Joint training 진행
- Motion Free Guidance : Temporal Motion이 Conditioning Signal로 사용되며 Temporal Consistency 향상을 위한 MFG를 정의함.
2.3.3 WALT
- Image와 Video를 Shared Latent Space로 표현함.
- 특수한 Attention Layer를 사용함. $q_s$의 Spatial Information에 대한 Self / Cross Attention(Text)를 진행하고 $q_t$의 Spatiotemporal Information에 대한 Self/Cross Attention을 진행
2.3.4 Snap Video
Video Generation Model을 더 효율적으로 만들기 위한 방법이다. 최근의 Video Generation Model은 Unet 기반의 모델을 3D로 확장한 모델인데, Computational Overhead가 존재한다. Temporal and Spatial Attention을 모두 진행하기 때문이다.
Redundant Information을 제거하기 위한 과정으로, Temporal과 Spatial Information을 1D의 Factor로 Highly Compression을 진행하는 과정을 거친다.
2.3.5 Sora
- Image와 Video Data를 Visual Encoder를 사용하여 Space Temporal Patch들로 표현하고 이를 활용하여 Transformer를 사용할 수 있도록 함.
- 다만, 복잡한 Text prompt가 들어왔을 때, 이를 제대로 완벽하게 처리하지는 못한다는 점을 발견함.
2.3.6 VideoPoet
- LLM을 사용한 Video Generation
- For Video Tokenizer
- Video = MAGVIT V2
- Audio = SoundStream
- 위 두 토크나이저를 사용하여 Video를 이산 코드 형태로 바꾸어 텍스트와 호환되도록 함.
- AutoRegressive하게 새로운 Token들을 생성하는 과정을 거침.
2.4 Training Efficient Techniques
2.4.1 AnimateDiff
T2I Model들은 본인들이 원하는 느낌의 이미지를 생성하도록 Pretraining된 모델들이 많다. 이 모델들을 전부 Finetuning하려면 굉장히 오랜 시간이 걸리기 때문에 이를 해결할 방법을 고민함. 이는 별도의 Motion Modeling Module을 따로 학습하여 여러 Domain specific T2I model을 Plug and play 방식으로 사용할 수 있도록 해주었다.
2.4.2 Text2Video-Zero
위 AnimateDiff 방법도 충분히 의미가 있지만, 그냥 Stable Diffusion Model을 사용하고 별다른 Fine Tuning 없이 바로 Video Generation에 사용할 수 없을까에 대해서 고민한 논문이다. 내용이 복잡해서 논문 전체를 읽어봐야겠음. 추가적인 Training이 없이도 temporal consistency가 잘 맞는 결과가 출력된다.
2.5 Storyboard
기존의 방법들은 모두 짧은 영상들을 생성하는 데에 집중했다. 여기에서 더 나아가 긴 Context에 맞는 긴 영상들을 생성할 수 없을까? 이를 위한 기초로 StoryBoard를 생성하는 Task가 먼저 제안되었다. 이는 영화 제작에 앞서서 먼저 대략적인 이미지와 해당 이미지에 대한 텍스트를 생성하는 과정을 의미한다.
2.5.1 VisorGPT
먼저 단일 이미지의 Storyboard를 생성하는 Task를 해결해야 한다. 이 논문이 해당 문제를 푸는 논문인데 먼저 Visual Prior에 해당하는 Object Bounding Box, Human Keypoints, Semantic Masks등등을 우리가 흔히 사용하는 LLM이 이해할 수 있는 Discrete한 Token으로 인코딩해주어야 한다. 이 과정을 통해서 Visual Prior들을 더 자세하게 표현할 수 있게 된다.

위와 같이 Human Keypoints들을 우리가 원하는 세부적인 방향으로 정보를 표현할 수 있다. 이를 통해서 정보에 맞는 Image를 Decoding하는 과정을 거친다.
2.5.2 VideoDirectorGPT
앞서 본 VisorGPT를 영상으로 확장한 버전이라고 이해할 수 있다. Video Planner가 여러 Scene에 대한 정의를 하고, 각 Scene에 대한 여러 Frame에 대한 정보를 확장하여 이를 정확한 Video를 생성하는 데에 활용한다.
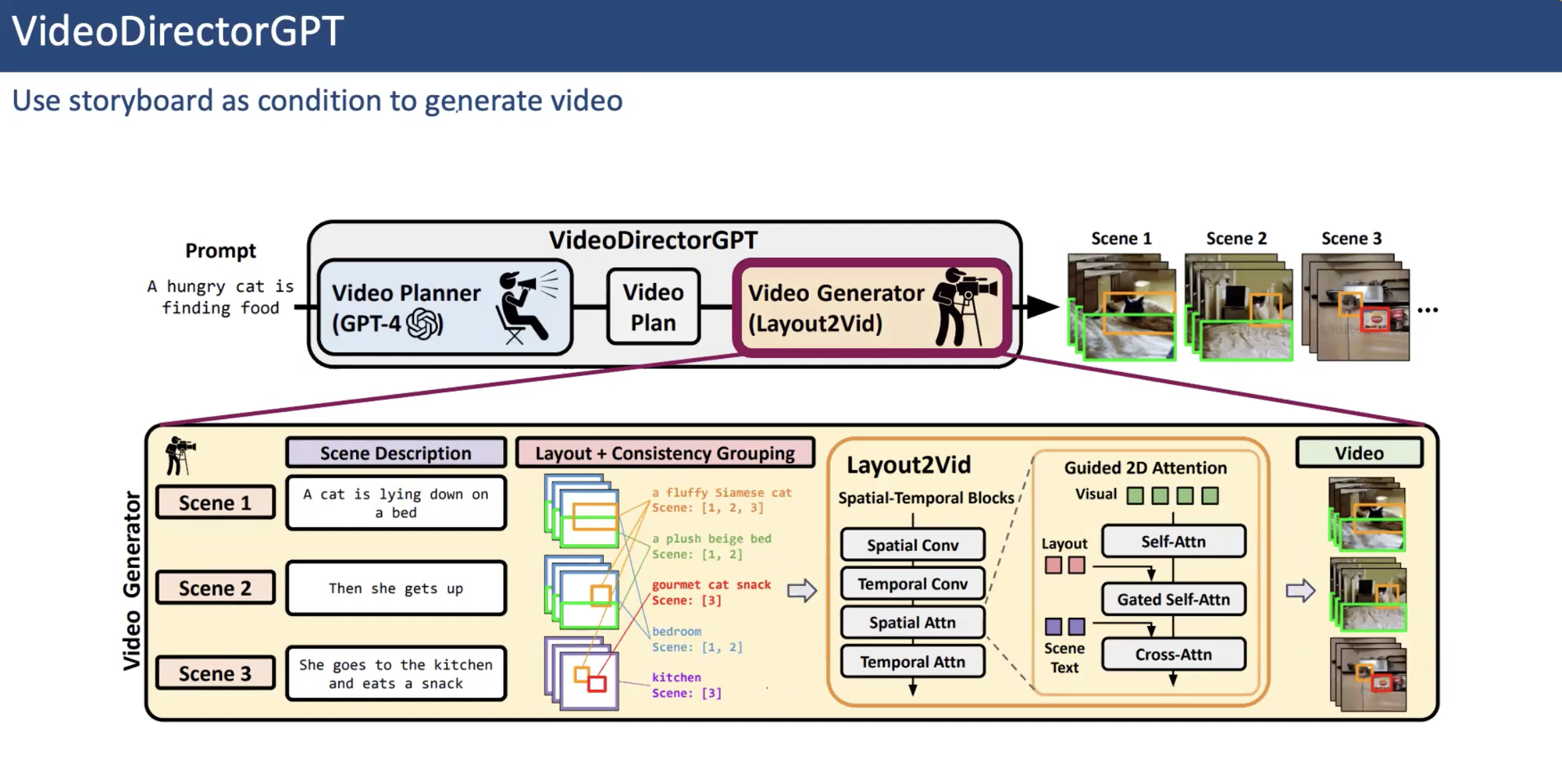
2.6 Long Video Generation
2.6.1 NUWA-XL
- Very Long Video over 3k frames 생성
- Parallel Inference를 통해서 Coarse to Fine Hierarchical generation 가능하게 함.
- 계층적인 Generation을 통해서 굉장히 긴 Sample을 생성할 수 있도록 해줌.
Global Diffusion은 Text에 대응되는 Sparse한 Frame들을 생성한다면, Local Diffusion은 두 Frame 사이의 공백을 메꾸는 방식으로 동작하기 때문에 계층적인 구조를 가진다. 이를 설명하는 Figure는 아래와 같다.

Global Diffusion : 앞뒤 Frame들은 신경쓰지 않고 오로지 text에 대응하는 이미지를 생성함. Local Diffusion : 앞뒤 Frame을 제공하고 가운데를 채우는 Interpolation Task를 품.
2.7 Multimodal guided generation
꼭 Text나 Image 기반이 아니더라도 다양한 Input을 기반으로 Video를 생성할 수 있다. 이번 장에서는 이와 관련된 생성모델을 정리한다.
2.7.1 MCDIFF
시작 Image Frame과 Flow와 관련된 움직이는 방향 정보를 주면 이를 바탕으로 영상을 생성하는 방식이다.
2.7.2 MotionCtrl / CamerCtrl
Camera Pose 정보를 추가적으로 주고 이에 맞는 영상을 생성하는 과정이다.
2.7.3 Cinematic Mindscapes
Human vision Reconstruction을 fMRI 신호를 바탕으로 복원하는 Task를 푼 것이다.