
소개
DeepSeek-V3는 효율적인 추론과 고성능을 동시에 달성하기 위해 다양한 구조적 개선과 학습 전략을 도입한 대규모 언어 모델(LLM)입니다. 본 포스트에서는 논문 및 발표 자료를 바탕으로 주요 기법을 정리합니다.
1. Multi-head Latent Attention (MLA)
1.1 개념
MLA는 Attention Key/Value를 압축 표현(Compressed Latent Vector)으로 저장하여
추론 시 메모리 사용량과 연산량을 줄이는 기법입니다.
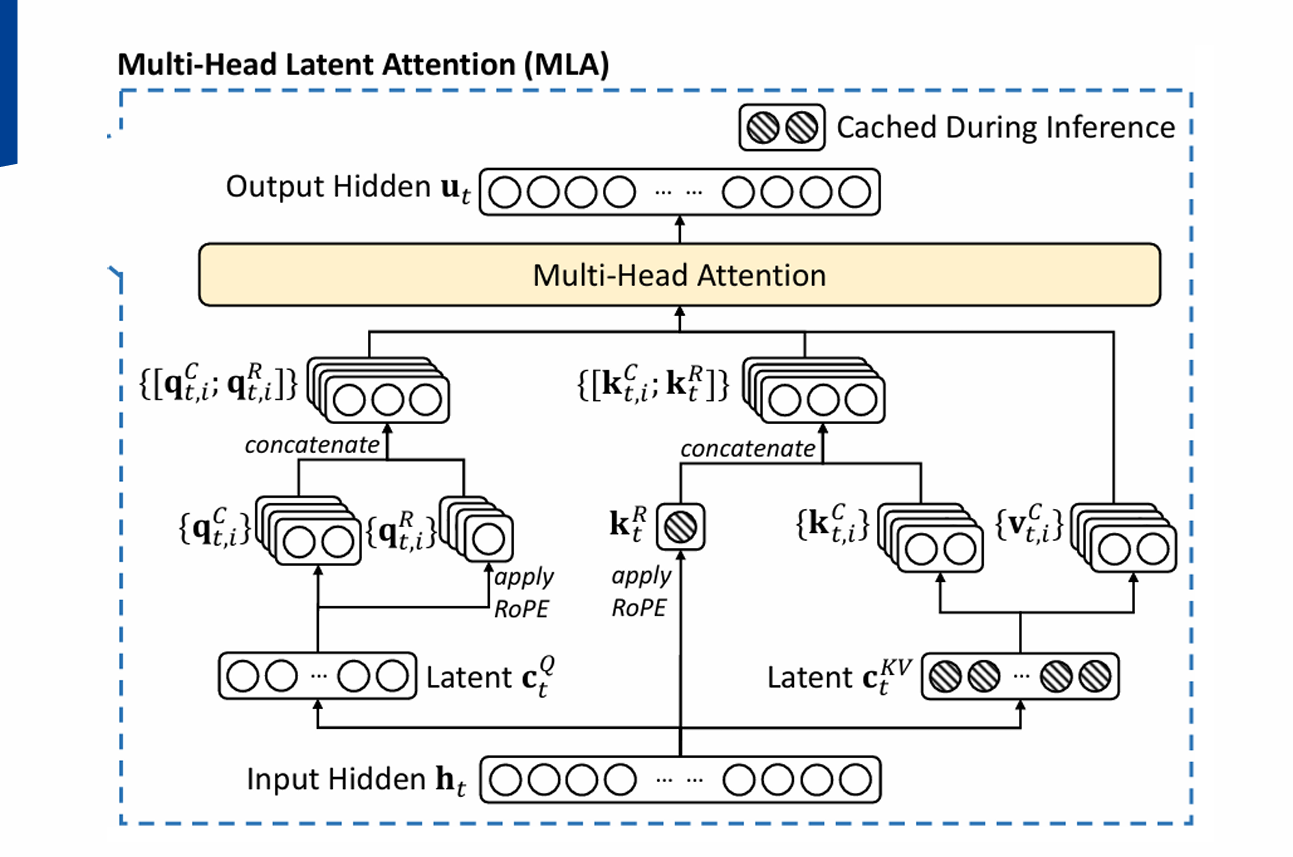


- 기본 파라미터
d: 임베딩 차원n_h: Attention head 개수d_h: head별 차원d_c: KV 압축 차원
- Projection 행렬
WDKV: Down projection (Key/Value 압축)WUK,WUV: Up projection (복원)
1.2 장점
- 메모리 사용량 절감
- 긴 시퀀스 추론에서 KV 캐시 효율성 향상
1.3 한계
- 추론 시 프리픽스 토큰의 Key 재계산 필요 → 속도 저하 가능성 존재
2. DeepSeekMoE 아키텍처
2.1 핵심 아이디어
- 전문가 세분화(Segmentation) → 각 전문가가 더 특화된 지식을 학습
- 공유 전문가(Shared Experts) → 전문가 간 지식 중복 완화
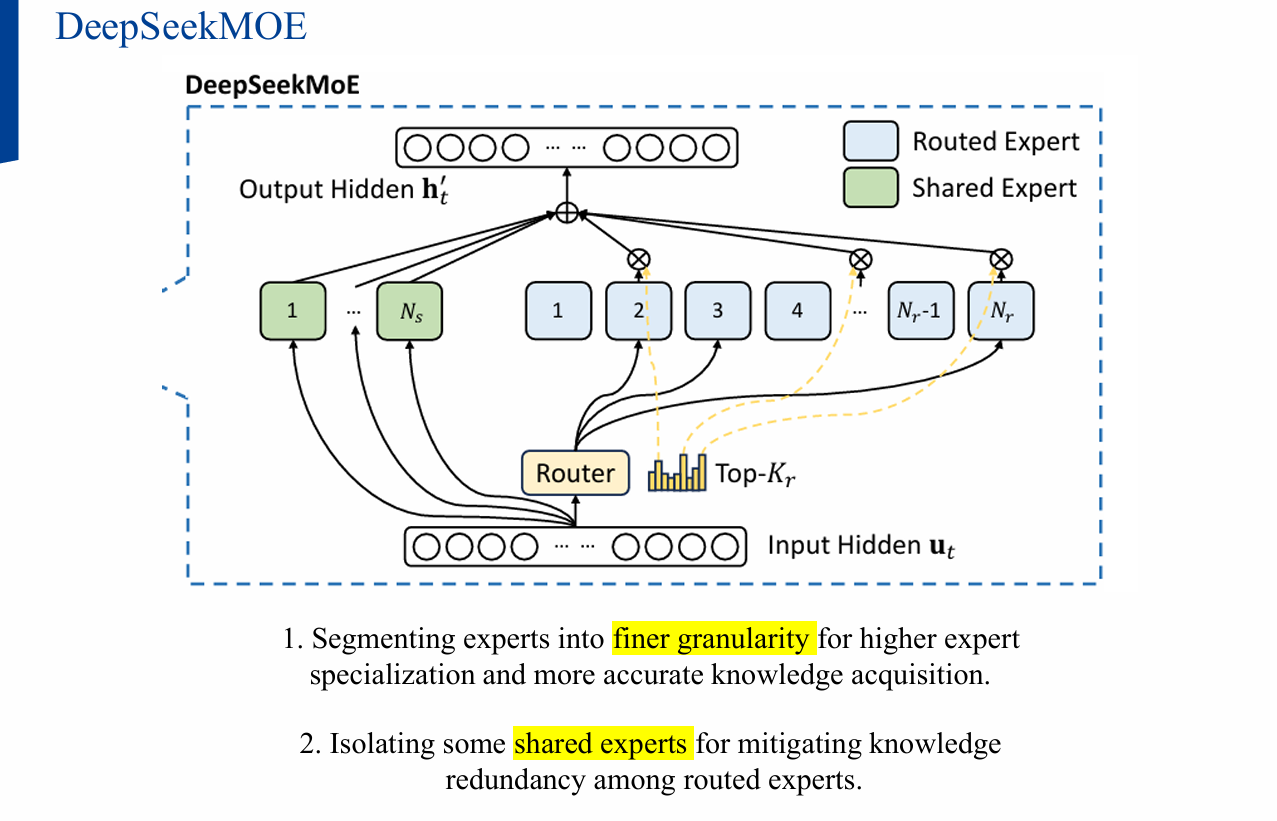

2.2 문제점
- MoE(Mixture-of-Experts) 모델은 불균형한 전문가 로드 → Routing Collapse 위험
- 전문가 병렬화 시 효율 저하
3. Auxiliary-loss-free Load Balancing
3.1 기존 문제
- 기존 MoE는 로드 밸런싱을 위해 Auxiliary Loss 추가 → 학습 안정성/성능에 부담
3.2 제안 기법
- Loss 없이 로드 밸런싱 수행
- 매 스텝마다 전문가별 로드를 모니터링
- 과부하 시 bias 감소
- 저부하 시 bias 증가
γ(Bias update speed)로 조정 속도 제어

4. Multi-token Prediction (MTP)
4.1 개념
- 한 번의 예측에서 여러 토큰을 동시에 예측하도록 학습
- 추론 시 MTP 모듈은 제거 가능 → 추론 비용 증가 없음
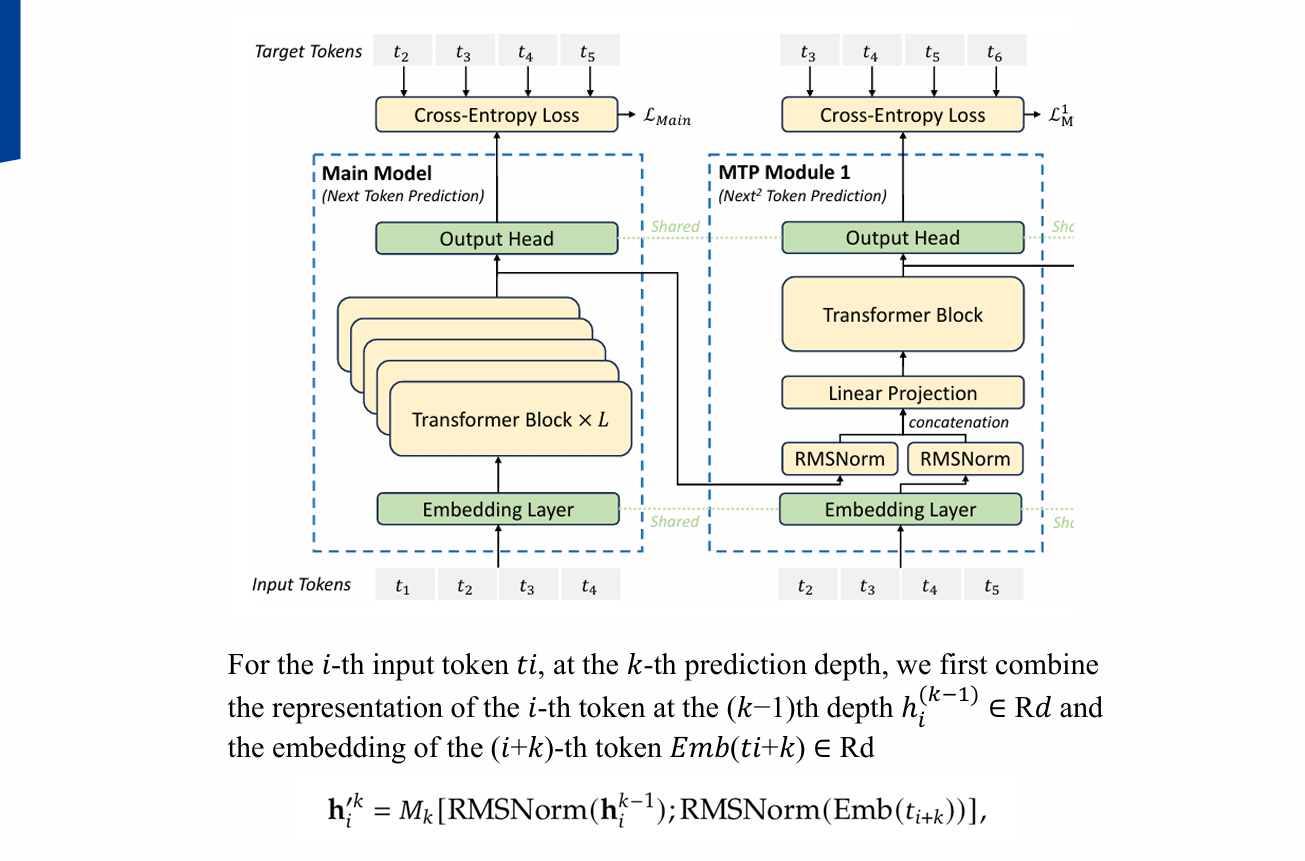
4.2 장점
- 학습 효율 상승
- 장기 시퀀스 예측 품질 향상
5. 종합 정리
| 기법 | 목적 | 효과 |
|---|---|---|
| MLA | KV 캐시 효율화 | 메모리 절감, 긴 시퀀스 처리 |
| DeepSeekMoE | 전문가 세분화 + 공유 | 지식 특화, 중복 감소 |
| Auxiliary-loss-free | 로드 밸런싱 | 성능 저하 없이 부하 분산 |
| MTP | 다중 토큰 예측 | 학습 효율 상승, 추론 속도 유지 |
참고자료
발표 자료
- 자세한 내용은 논문이나 아래 발표 자료로 확인 가능합니다.