
대규모 언어 모델(LLM) 서빙에서 KV 캐시가 차지하는 메모리와 파편화가 병목입니다.
PagedAttention은 OS의 페이징 아이디어를 어텐션에 적용해 KV 캐시를 블록(block) 단위로 관리·공유하여
메모리 낭비를 거의 0에 가깝게 줄이고, throughput를 2–4× 끌어올립니다.
1) 배경: LLM 서빙과 KV 캐시
1.1 오토리그레시브(autoregressive) 생성과 어텐션
문장 $x=(x_1,\dots,x_n)$에 대해 언어모델은 다음처럼 분해합니다.
\[P(x) \;=\; P(x_1)\,P(x_2\mid x_1)\cdots P(x_n\mid x_{1:n-1})\]셀프 어텐션의 기본식은
\[q_i=W_q x_i,\quad k_i=W_k x_i,\quad v_i=W_v x_i\] \[a_{ij}=\frac{\exp\!\big(q_i^\top k_j/\sqrt{d}\big)}{\sum_{t\le i}\exp\!\big(q_i^\top k_t/\sqrt{d}\big)},\qquad o_i=\sum_{j\le i} a_{ij}\,v_j\]KV 캐시: 이전 토큰들의 $k_j, v_j$를 캐시해 다음 토큰 계산에 재사용. 프롬프트 단계(병렬)와 디코딩 단계(순차)로 나눕니다.
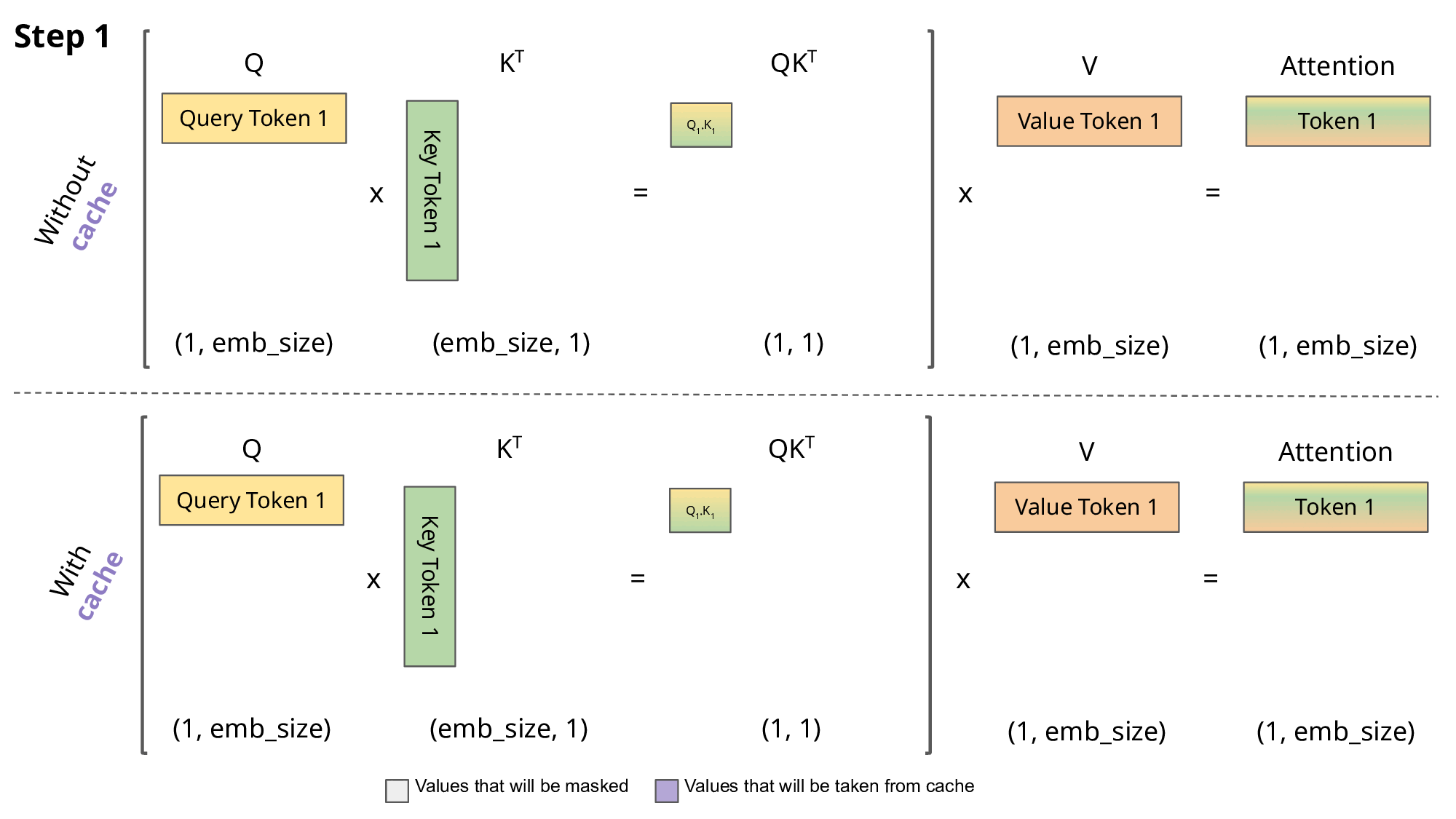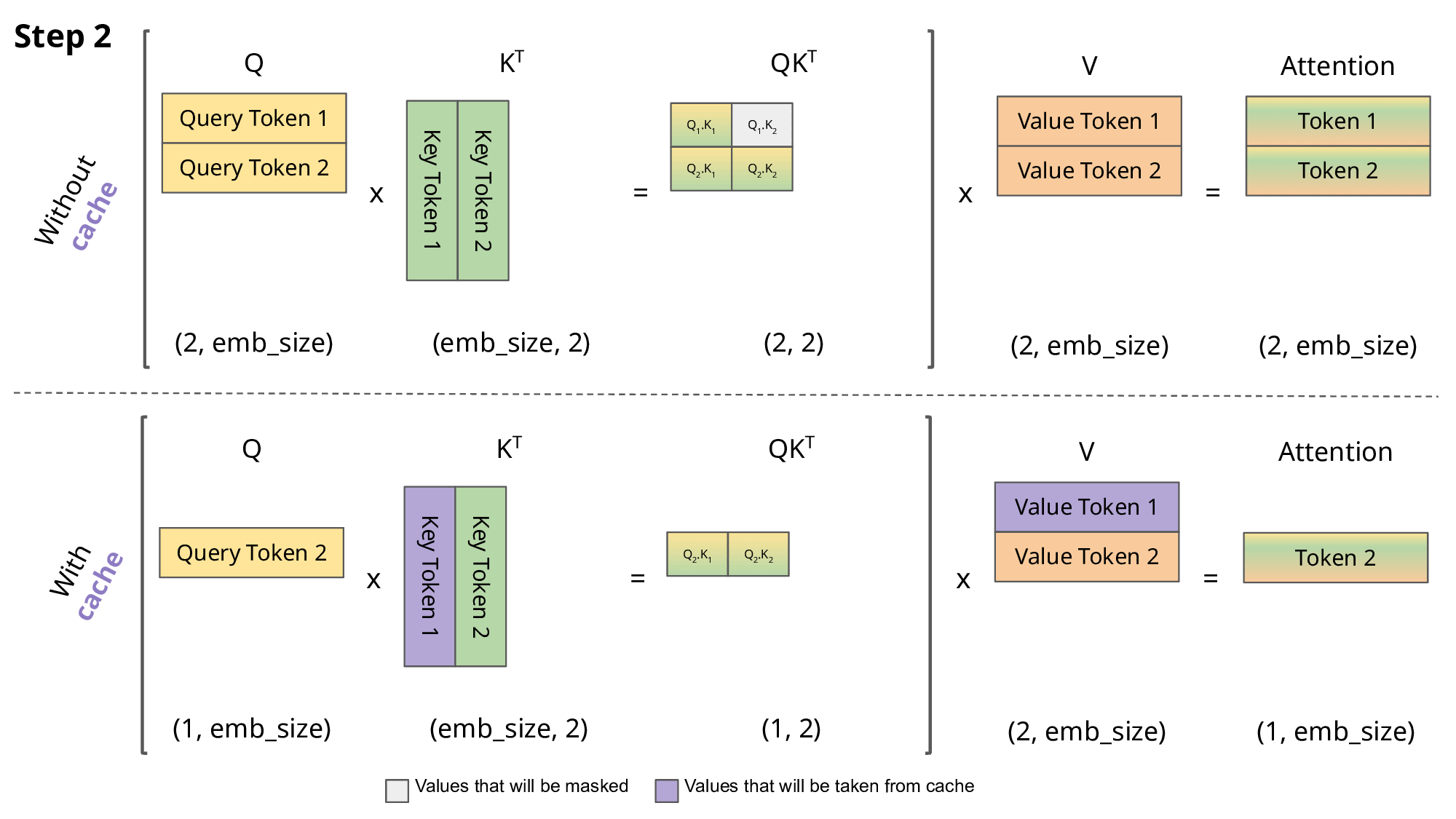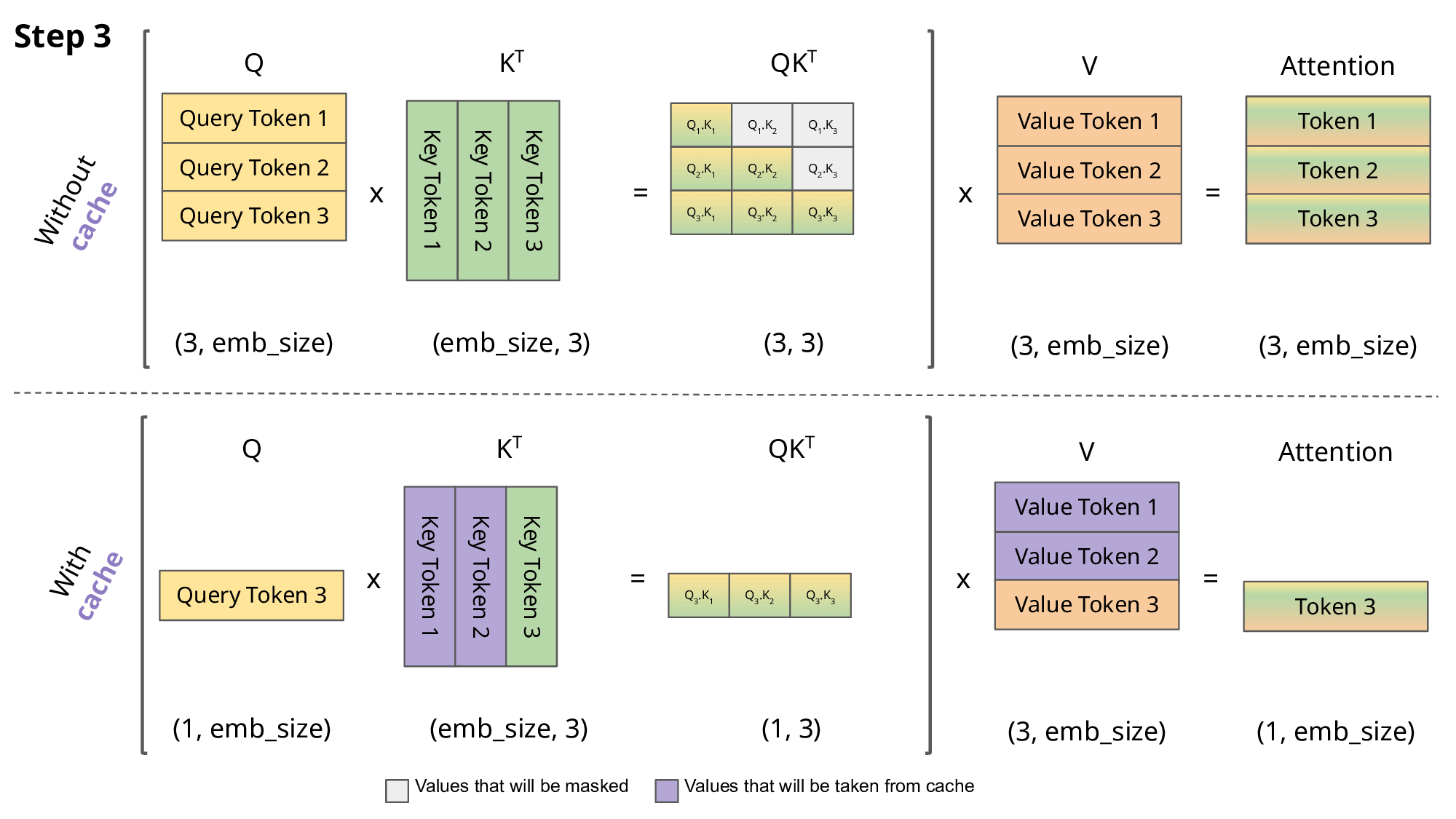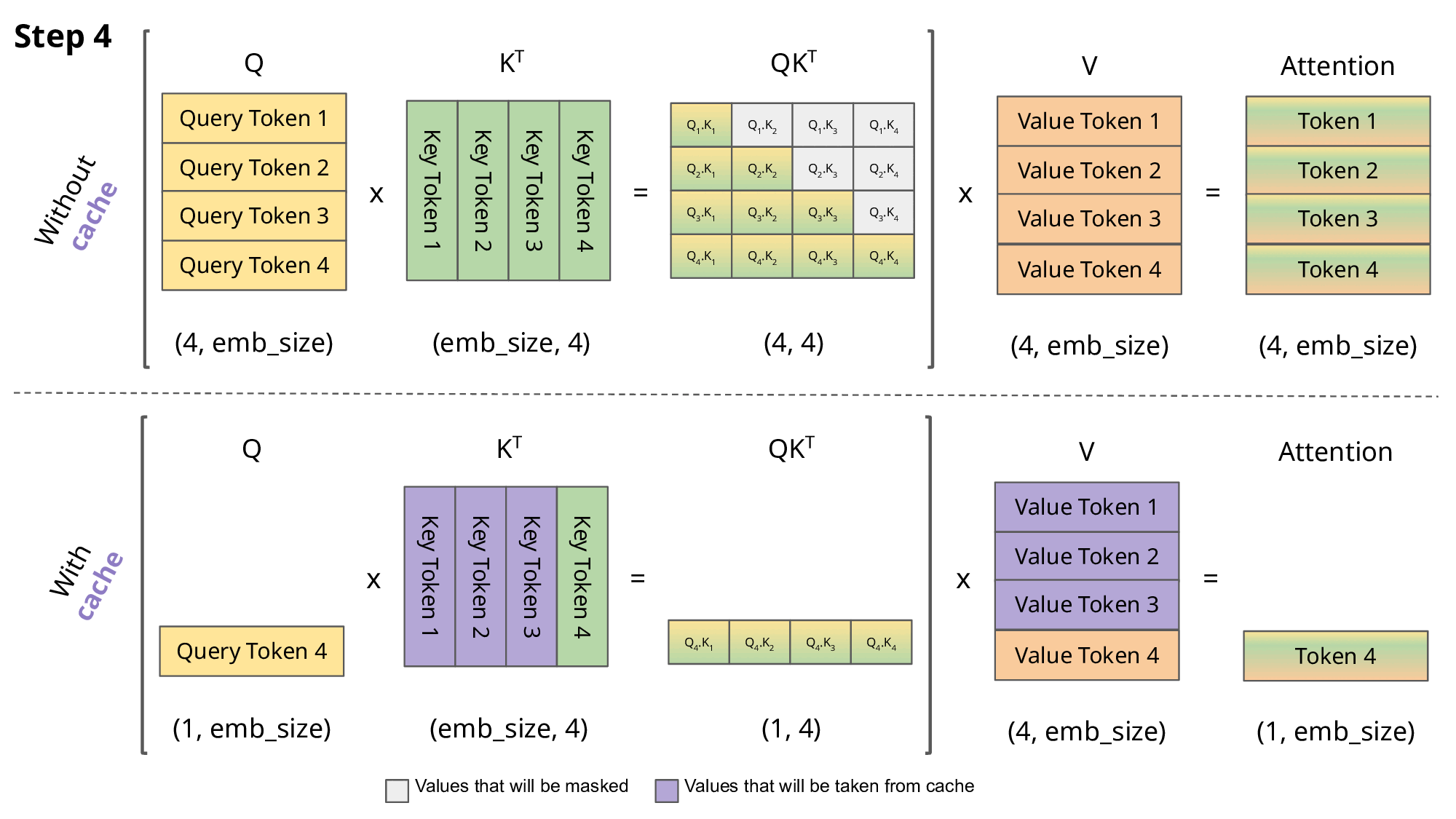
- 문제: 기존 시스템은 요청별 KV 캐시를 연속(contiguous) 메모리에 잡아 두고,
요청 길이가 가변이라 내·외부 파편화로 낭비가 큽니다.
(실사용 비율이 20.4%~38.2%에 그친 사례 보고)
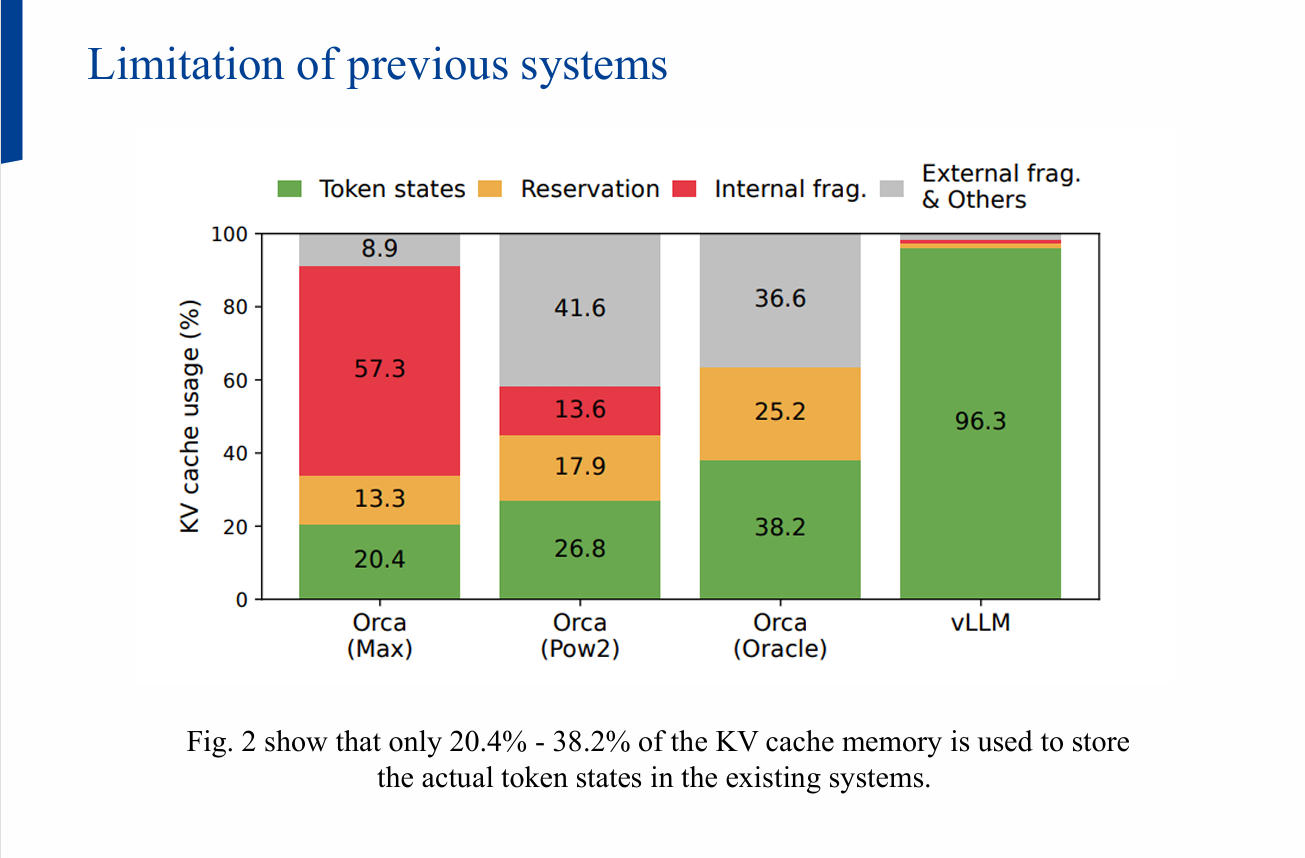
2) 기존 설계의 한계 정리
- 연속 메모리 전제: 프레임워크가 텐서를 연속 저장하길 요구 → KV 캐시도 요청별로 큰 덩어리 선할당
- 내부 파편화: 최대 길이(예: 2048토큰) 기준 예약 vs 실제 생성 길이 차이
- 외부 파편화: 요청별 예약 크기가 달라서 빈 공간이 쪼개짐
- 메모리 공유 불가: 병렬 샘플링/빔 서치에서 겹치는 prefix를 공유하면 절약 가능하지만,
연속 저장 탓에 부분 공유가 사실상 불가
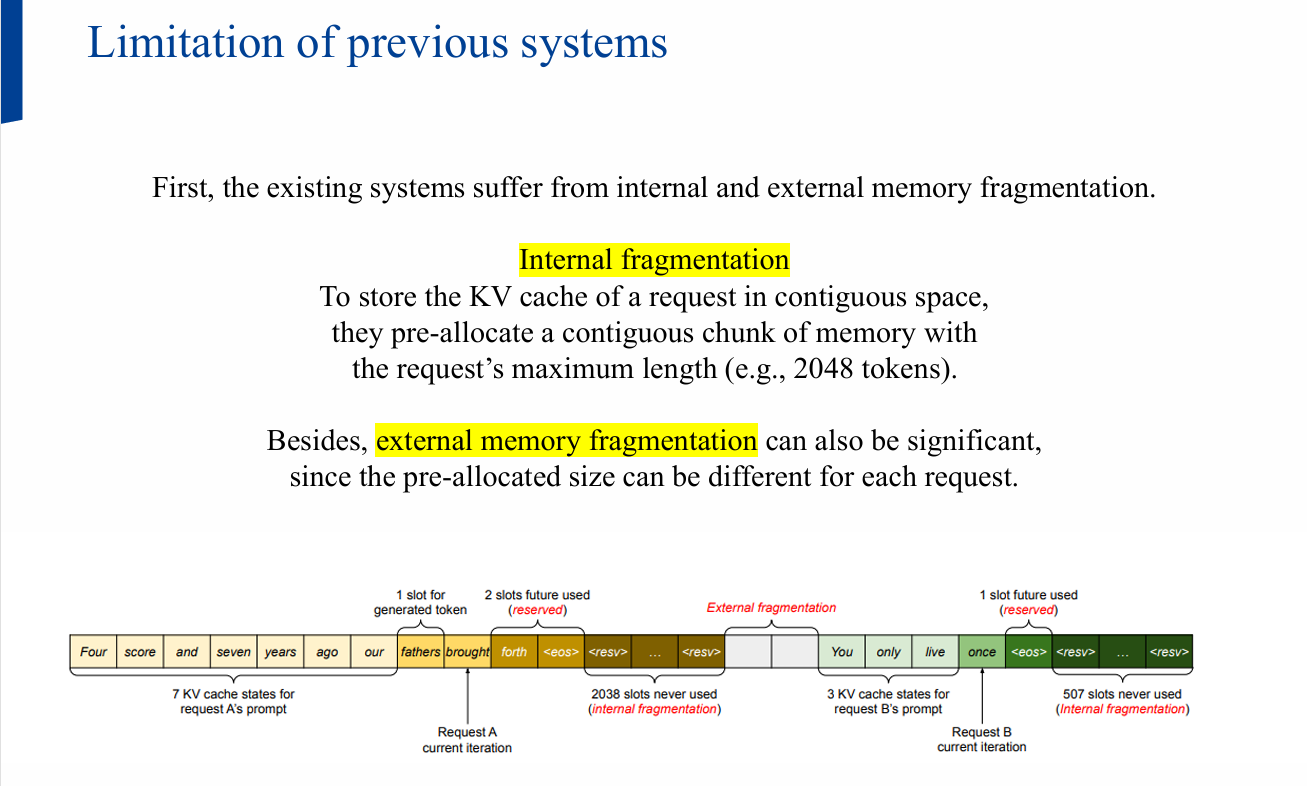
3) PagedAttention: 블록 단위 KV 캐시
3.1 아이디어
- KV 캐시를 고정 크기 블록(block) 으로 쪼개 저장 (물리적으로 비연속해도 됨)
- 요청은 논리 블록을 순서대로 쌓고, 블록 테이블이 Logical → Physical 매핑을 관리
- 필요할 때만 블록을 할당하고, 동일/유사 prefix는 블록 수준에서 공유 가능
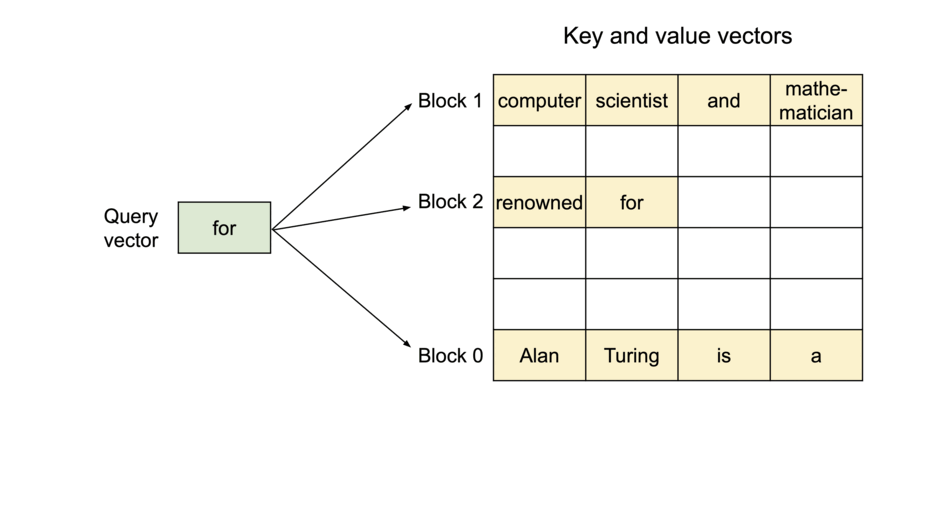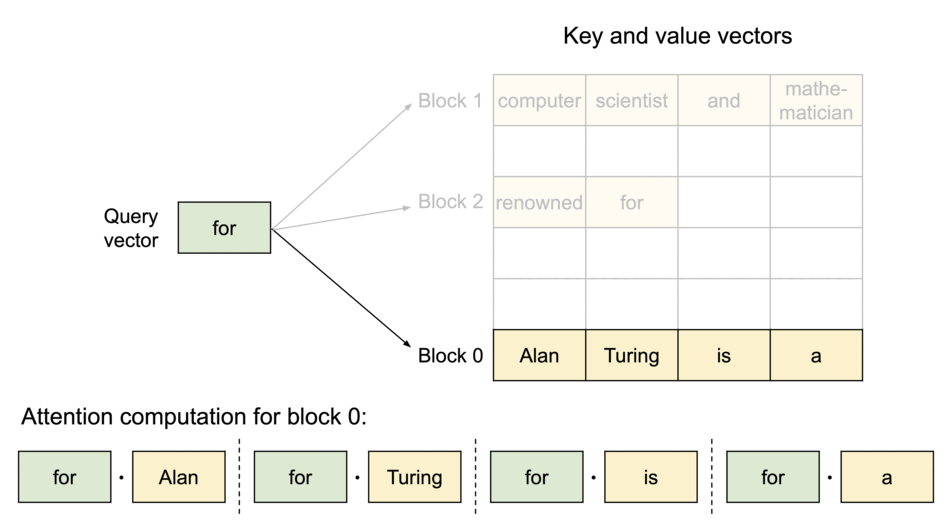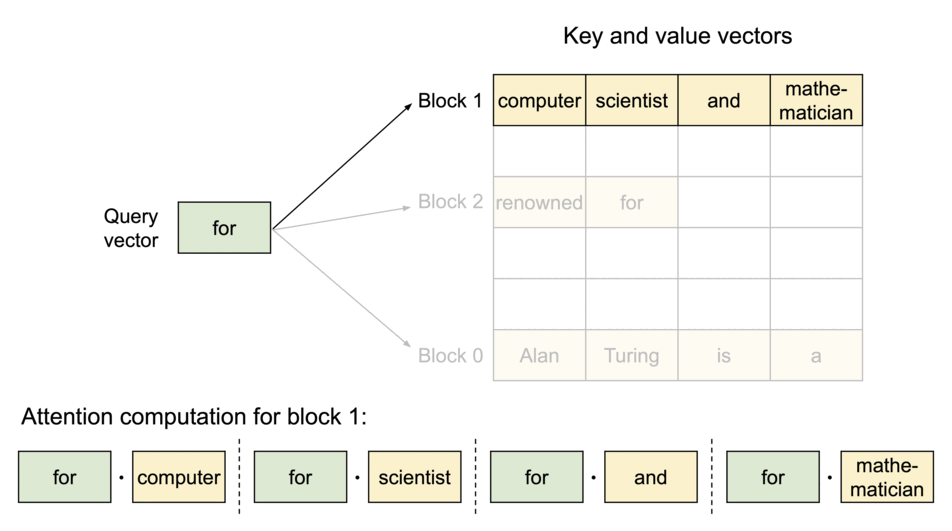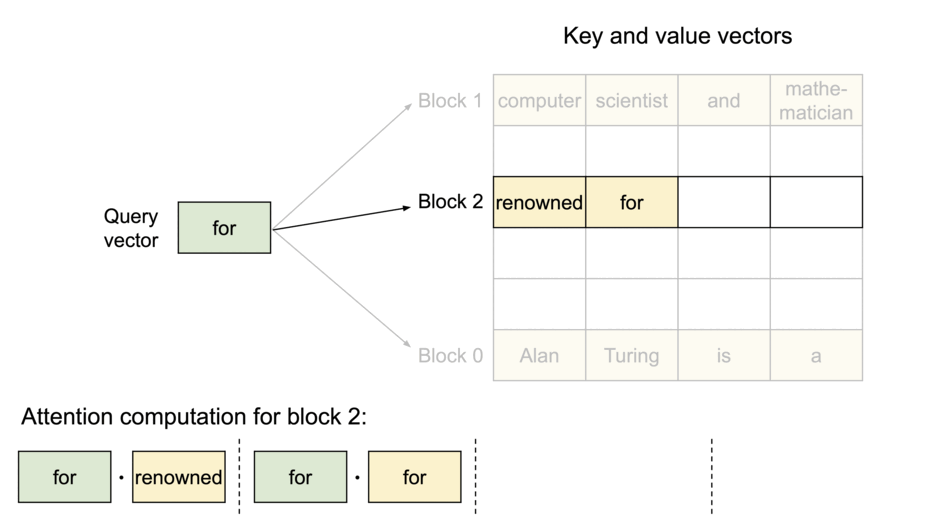
3.2 블록 단위 어텐션 수식
블록 크기를 $B$라 하고, $j$번째 키/밸류 블록을
\[K_j = (k_{(j-1)B+1},\dots,k_{jB}),\quad V_j=(v_{(j-1)B+1},\dots,v_{jB})\]로 두면, 어텐션을 블록별로 다음과 같이 쓸 수 있습니다.
\[A_{ij}\;=\;\Big(a_{i,(j-1)B+1},\dots,a_{i,jB}\Big) \;=\; \frac{\exp\!\big(q_i^\top K_j/\sqrt{d}\big)}{\sum_{t=1}^{\lceil i/B\rceil}\exp\!\big(q_i^\top K_t/\sqrt{d}\big)}\] \[o_i \;=\;\sum_{j=1}^{\lceil i/B\rceil} V_j\,A_{ij}^\top\]여기서 $A_{ij}$는 $j$번째 KV 블록에 대한 $i$번째 쿼리의 행(row) 어텐션 점수 벡터입니다.
3.3 효과
- 내부 파편화 완화: 작은 블록을 온디맨드로 할당
- 외부 파편화 제거: 모든 블록이 동일 크기
- 공유 가능: 동일 요청 내 샘플/빔, 심지어 서로 다른 요청 간에도 블록 공유
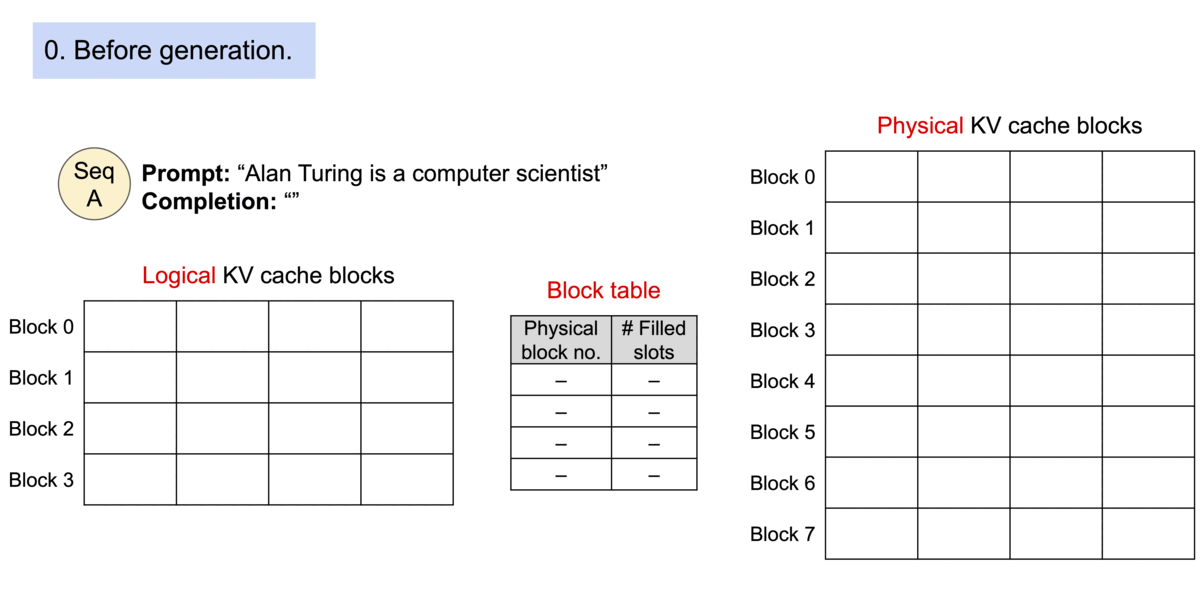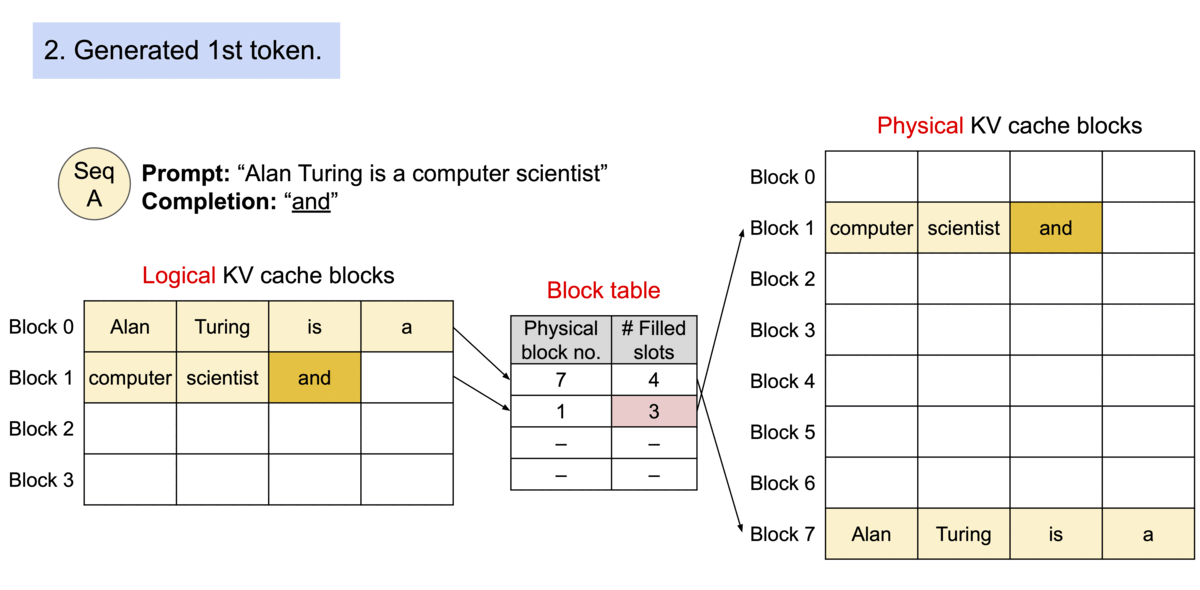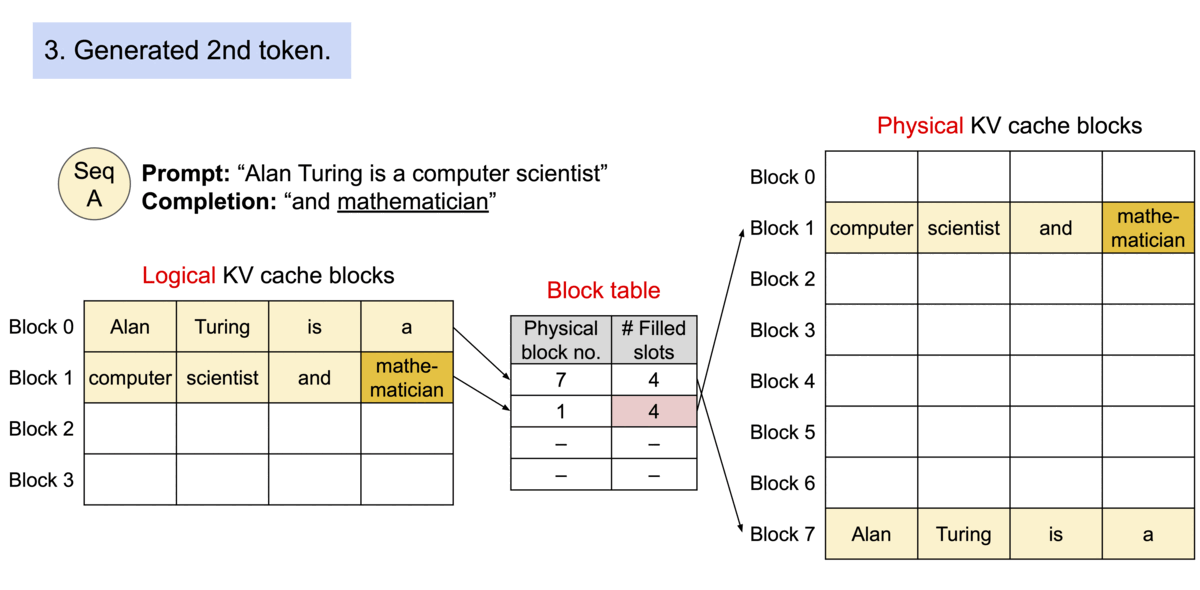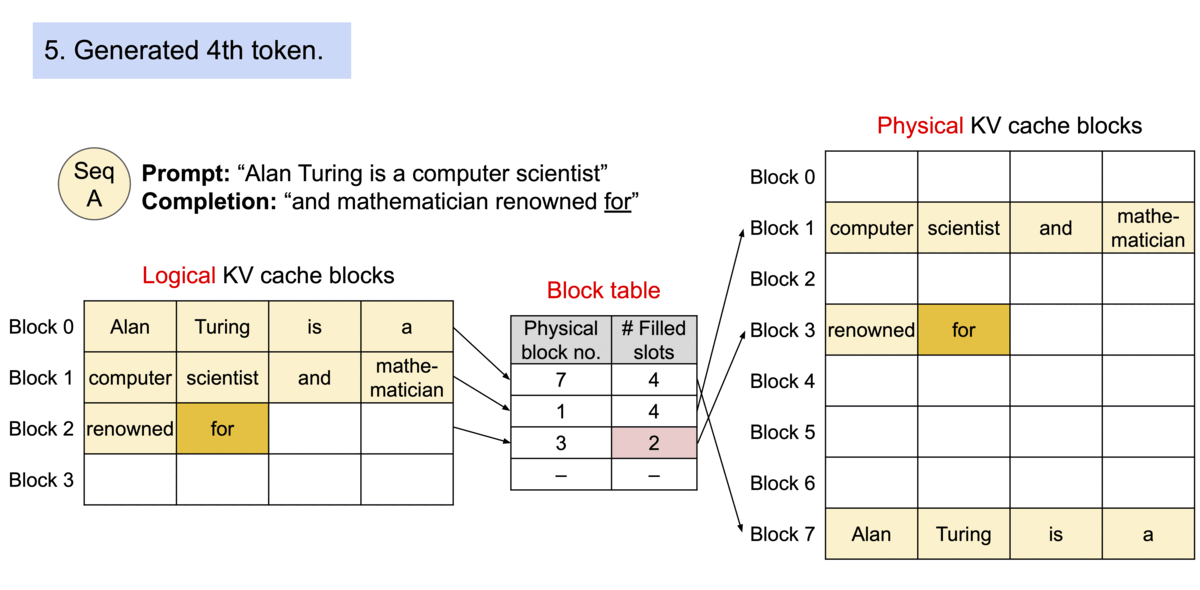
4) KV Cache Manager
- 블록 테이블: 요청마다 논리 블록 → 물리 블록 매핑을 관리
- 연속 논리 블록이라도 물리 주소는 불연속일 수 있으며, 커널이 테이블을 참조해 올바른 블록을 gather
- Prefill → Decode 파이프라인:
- Prefill(프롬프트)에서 첫 출력까지 일반 어텐션으로 KV 생성
- Decode(오토리그레시브)에서 매 스텝 새 블록이 찰 때만 다음 물리 블록 할당
- 결과적으로 낭비는 최대 1블록 크기에 한정
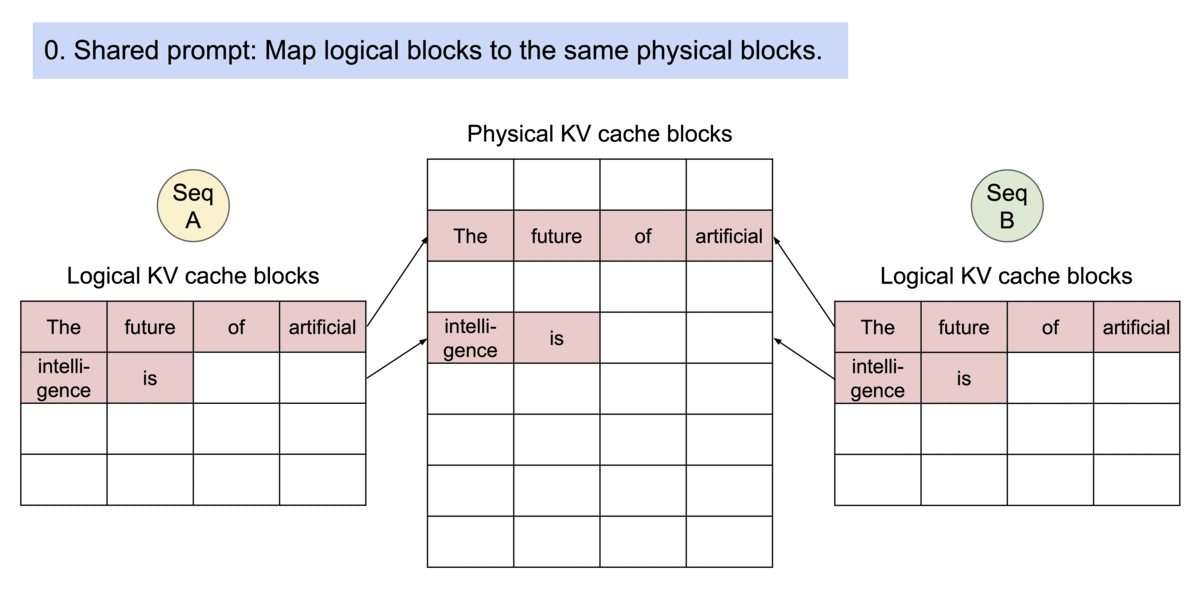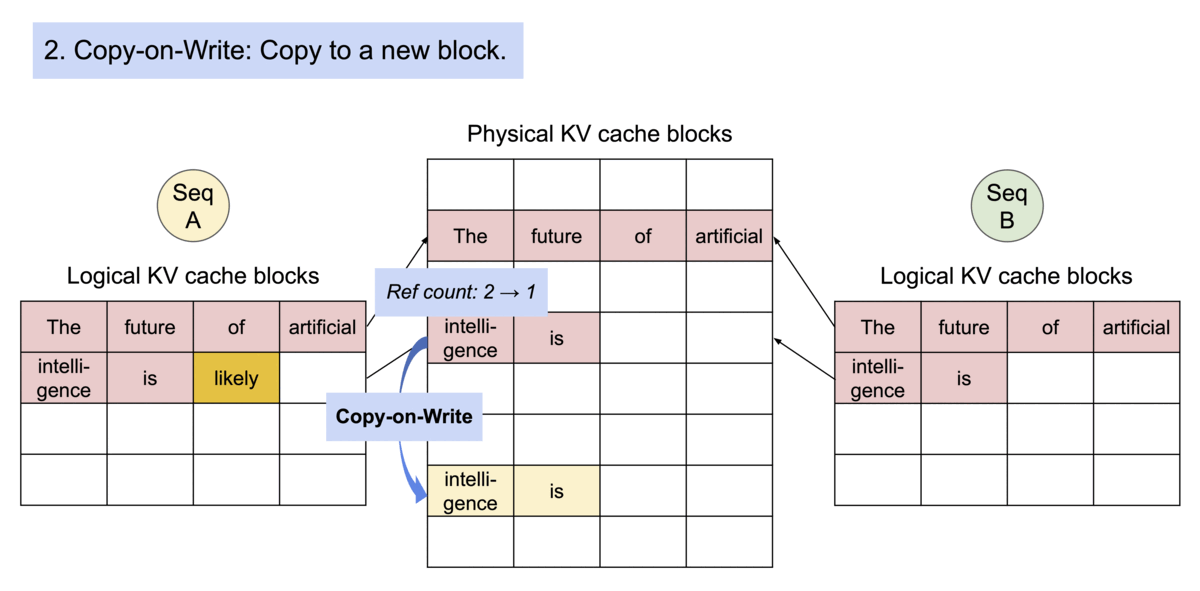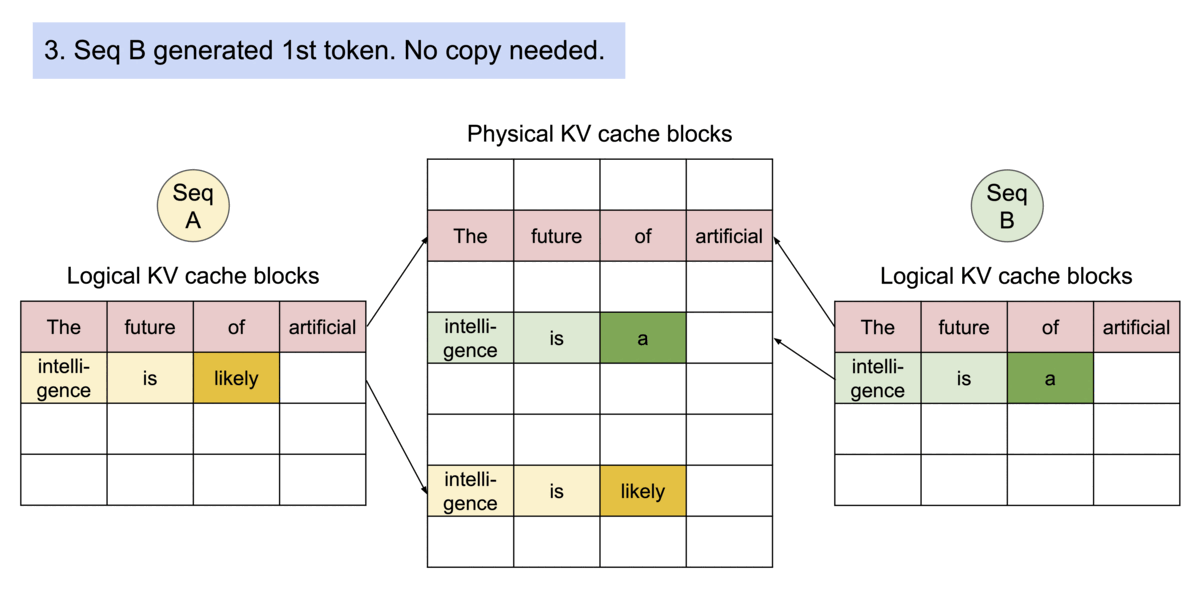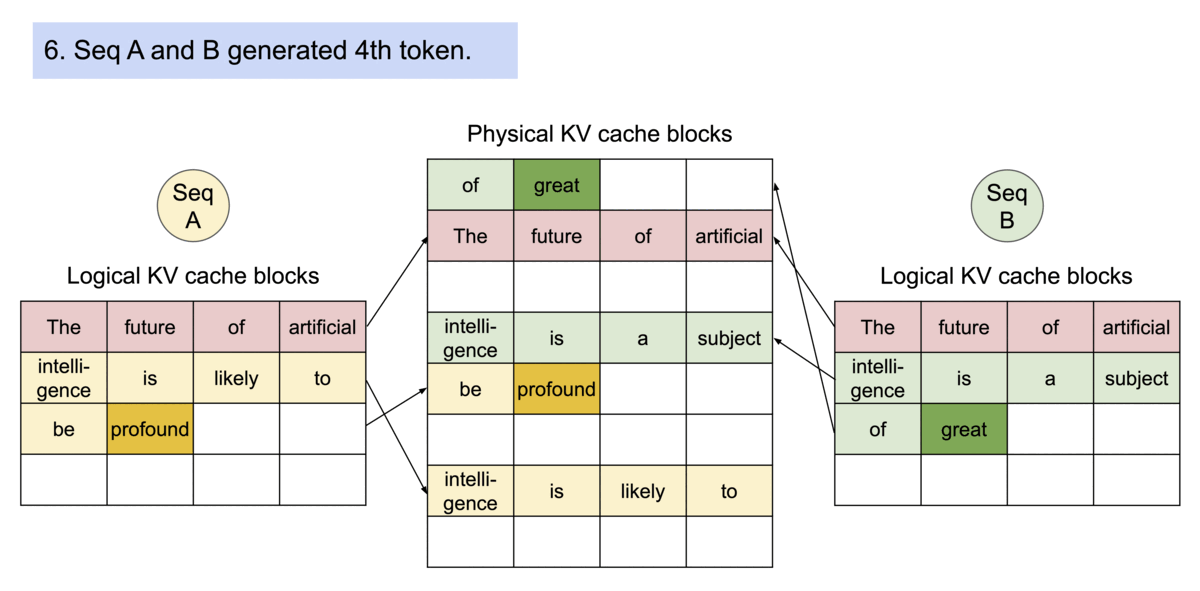
5) 복잡한 디코딩에서의 공유
- 병렬 샘플링: 여러 후보를 뽑을 때, 공유되는 prefix의 KV 블록을 재사용
- 빔 서치: 빔 간 공통 prefix 구간은 동일 블록 참조 → 메모리·대역폭 절약
7) 실험 설정
- 모델: OPT-13B / 66B / 175B, LLaMA-13B
- 하드웨어: NVIDIA A100
- 트레이스:
- ShareGPT (길고 다양한 대화)
- Alpaca (짧고 instruction 스타일)
비교 대상
- FasterTransformer: 지연(latency) 최적 엔진
- Orca: 처리량(throughput) 최적 엔진 — 세 가지 예약 시나리오
- Oracle(실제 출력 길이 사전지식)
- Pow2(최대 2× 과예약)
- Max(모델 최대 길이로 항상 예약)
8) 결과
- 처리량 2–4× 향상(동일 지연 수준) — 길이가 길수록, 모델이 클수록, 디코딩이 복잡할수록 이점 ↑
- KV 캐시 낭비 ~0에 수렴: 토큰 상태가 아닌 예약·내부·외부 파편화 비중이 극적으로 감소
- 커널 지연은 블록 테이블 접근·분기 등으로 소폭(20–26%) 증가하지만, 엔드투엔드 성능은 크게 우세
- 챗봇 트래픽(ShareGPT) 처럼 프롬프트가 긴 환경에서 Orca 대비 2× 이상의 요청 처리율
참고 자료
발표 자료
- 자세한 내용은 논문이나 아래 발표 자료로 확인 가능합니다.