
바이너리를 C 소스 코드로 복원하는 디컴파일(decompile) 문제에 LLM을 적용.
End2end-Decompile(바이너리→어셈→C 직접 복원)과 Refined-Decompile(Ghidra 결과를 LLM으로 정제) 두 축.
Decompile-Eval: 토큰 유사도 대신 재컴파일 가능성(syntax) + 재실행 가능성(semantics)으로 평가.
대규모 데이터(최적화 단계 O0~O3 포함)·중복 제거(LSH)·2단계 학습으로 성능 향상.
일부 벤치마크에서 기존 도구나 GPT-4o 대비 재실행률 2배+ 개선.
1) 배경과 문제 정의
전통 도구(예: Ghidra/IDA Pro)는 CFG 패턴과 규칙 기반 복원을 수행하지만, 최적화된 바이너리에서는
- 변수명/고수준 구조(루프/조건) 소실,
- 포인터 연산·goto 등 저수준 표현으로 치환,
- 결과 코드 가독성/재실행성 미흡
이라는 한계를 자주 보입니다.

LLM4Decompile은 LLM을 디컴파일 전용으로 파인튜닝하여, 사람 친화적인 소스 형태로의 복원을 목표로 합니다.
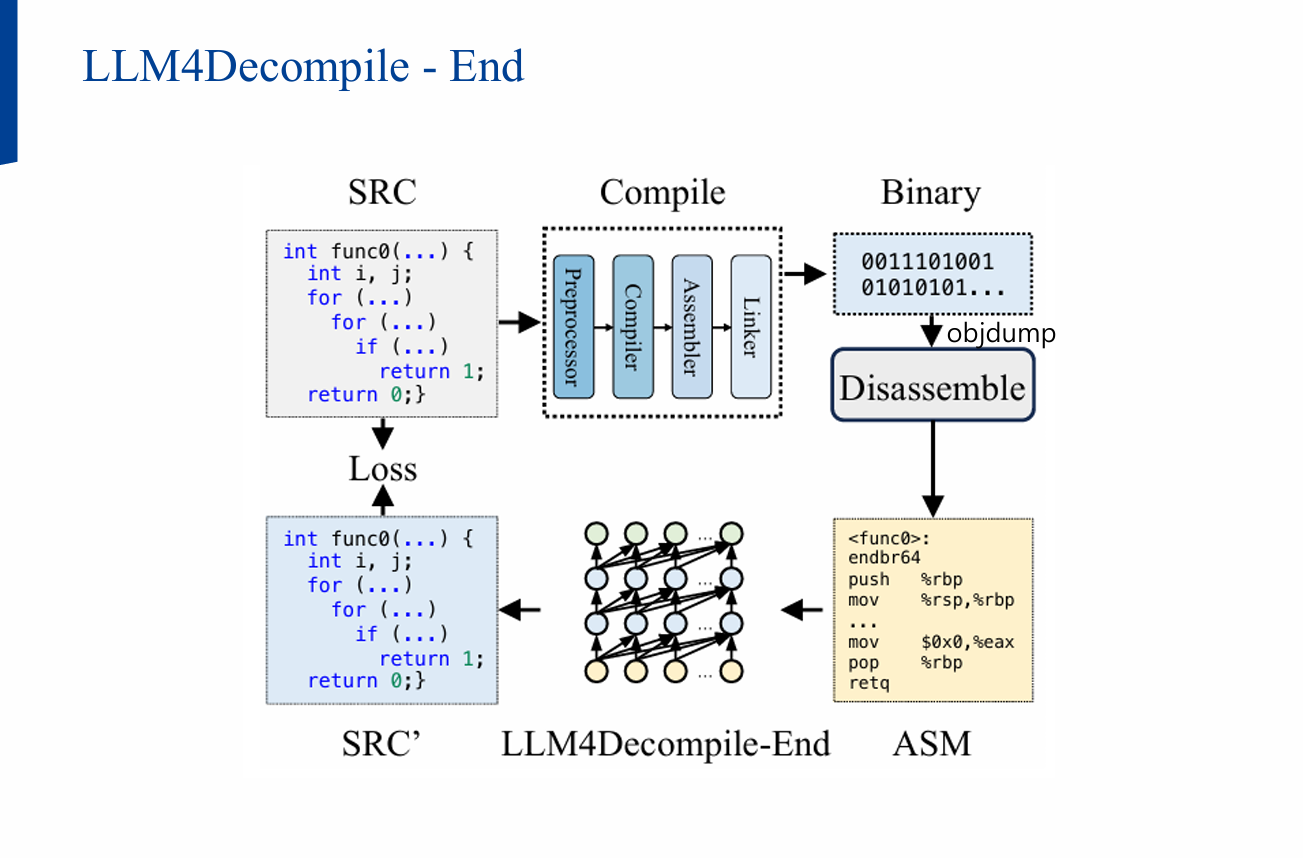
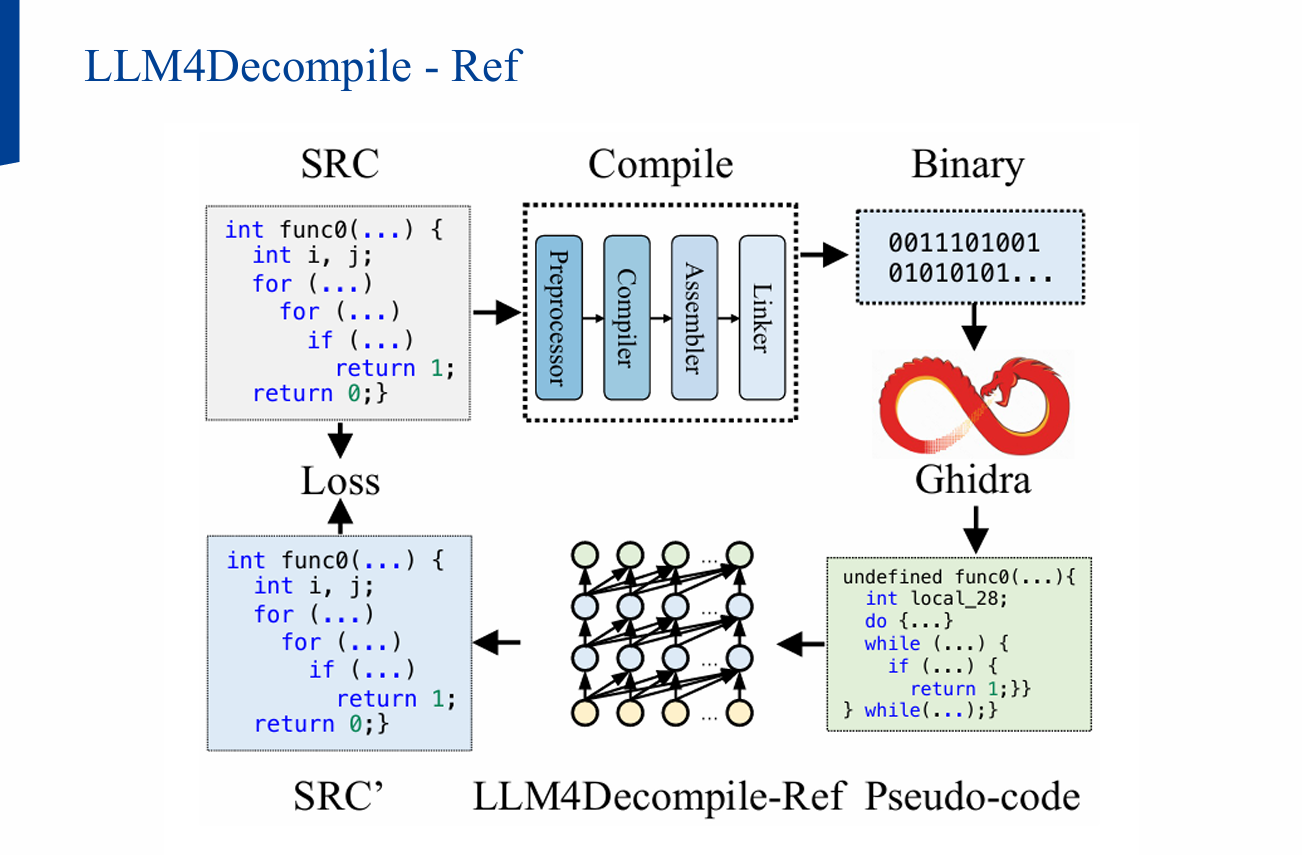
2) 접근 개요: Refined vs End2end
- Refined-Decompile: Ghidra가 생성한 의사코드를 LLM이 정제(가독성↑, syntax 오류 수정)
- End2end-Decompile: objdump로 얻은 어셈블리에서 곧장 C 코드를 생성
본 연구는 두 경로 모두를 강화:
- LLM4Decompile-End: 대규모/다양한 학습데이터, 데이터 클린징, 2-Stage 학습
- LLM4Decompile-Ref: Ghidra의 비실행/실행 바이너리 중 비실행 오브젝트를 활용해 대량 정제 데이터를 효율 수집, 최종 정제 성능↑
3) 학습 데이터 & 전처리
3.1 asm—source 페어 구축
- 대규모 공개 C 함수 집합에서 소스→(GCC O0/O1/O2/O3)→오브젝트/실행파일→objdump→ASM 생성
- ASM–소스 페어를 만들고, 프롬프트에 최적화 단계 힌트를 삽입:
1
2
3
This is the assembly code with [O{0|1|2|3}] optimization:
[ASM]
What is the source code?
3.2 데이터 품질 향상
- MinHash + LSH를 이용한 중복 제거
- 극단적으로 짧은 샘플 제외(예: < 10 토큰)
3.3 2-Stage 학습
- Stage 1 (Compilable/비실행): 링크 전 오브젝트(외부 심볼 바인딩 없음)로 대량 학습 → 바이너리 패턴 폭넓게 습득
- Stage 2 (Executable/실행): 실제 링크된 실행 파일 기반으로 세부 실용성 보정
4) 학습 목적 함수
본 문제를 기계 번역 시나리오로 보고, 입력(ASM) → 출력(C 코드)의 조건부 생성으로 최적화합니다.
4.1 Next-Token Prediction (NTP)
표준 언어모델 목적(자연어/코드 공통)으로, 전체 시퀀스의 다음 토큰 확률을 최대화:
\[\mathcal{L}_{\text{NTP}} = - \sum_{t=1}^{T} \log p_\theta\big(x_t \mid x_{<t}\big)\]- 입력(ASM)과 출력(C) 전체 토큰에 대해 손실을 계산
- 단, 디컴파일에서는 출력 시퀀스(소스) 복원이 핵심이므로, 아래의 S2S 목적이 더 직접적
4.2 Sequence-to-Sequence (S2S)
입력 시퀀스(ASM)가 주어졌을 때 출력(C 코드) 부분 토큰만에 대해 음의 로그우도를 최소화:
\[\mathcal{L}_{\text{S2S}} = -\sum_{i}\log P_\theta\big(x_i,\dots,x_j \,\big|\, x_1,\dots,x_{i-1}\big)\]- 출력 토큰 범위 $x_i\ldots x_j$에 대해서만 손실 집계
- 실험적으로 S2S $\ge$ NTP 또는 S2S $+$ NTP 조합이 유리한 경향
5) Refined-Decompile 세부
- Ghidra 결과는 논리 구조 보존 측면에서 유용하나, 가독성/구문 오류가 잦음
- 효율적 데이터 수집: 실행 파일은 디컴파일에 고비용 → 비실행 오브젝트로 대체 시 속도 ~10×
- 필터링: 지나치게 긴 의사코드는 모델 한계를 초과 → 길이 컷 적용
- 결과: End2end 대비 정제 단계에서 상한 성능이 더 높게 관측(추가 향상)
6) 평가: Decompile-Eval
6.1 왜 BLEU/Edit-Sim이 부족한가?
- 변수/함수명 변경은 의미 보존이나 토큰 유사도는 크게 변동
- 반대로 한 줄 논리 오류는 의미 붕괴지만 n-gram 점수는 높게 나올 수 있음
6.2 프로토콜(파이프라인)
1) C 소스 → 2) GCC 컴파일 → 3) objdump로 ASM →
4) (LLM) 디컴파일로 C 복원 → 5) 재컴파일(Re-compilability) → 6) 테스트(Re-executability)
- Re-compilability: 복원 코드가 컴파일 성공(syntax 정합성)
- Re-executability: 준비된 assertion 테스트 통과(semantic 보존)
7) 주요 결과
7.1 End2end
| 모델 | HumanEval(Avg) | ExeBench(Avg) |
|---|---|---|
| DeepSeek-Coder (base, 6.7B/33B) | ~0 | ~0 |
| GPT-4o | ~16 | ~3.8 |
| LLM4Decompile-End-1.3B | ~27.3 | ~14.5 |
| LLM4Decompile-End-6.7B | ~45.4 | ~18.0 |
| LLM4Decompile-End-33B | ~31.5 | ~15.4 |
최적화 단계가 O0 → O3로 갈수록 난이도가 높아지므로, 모든 모델에서 성능 하락.
6.7B가 33B보다 좋은 구간도 존재(학습 토큰/스케줄 차이).
7.2 유사도 지표
| 모델 | BLEU(Avg) | EditSim(Avg) |
|---|---|---|
| DeepSeek-Coder-33B | 0.034 | 0.116 |
| LLM4Decompile-1B | 0.493 | 0.595 |
| LLM4Decompile-6B | 0.819 | 0.850 |
| LLM4Decompile-33B | 0.755 | 0.807 |
주의: BLEU/ES는 의미를 온전히 반영하지 못하므로 참고 지표로만 사용.
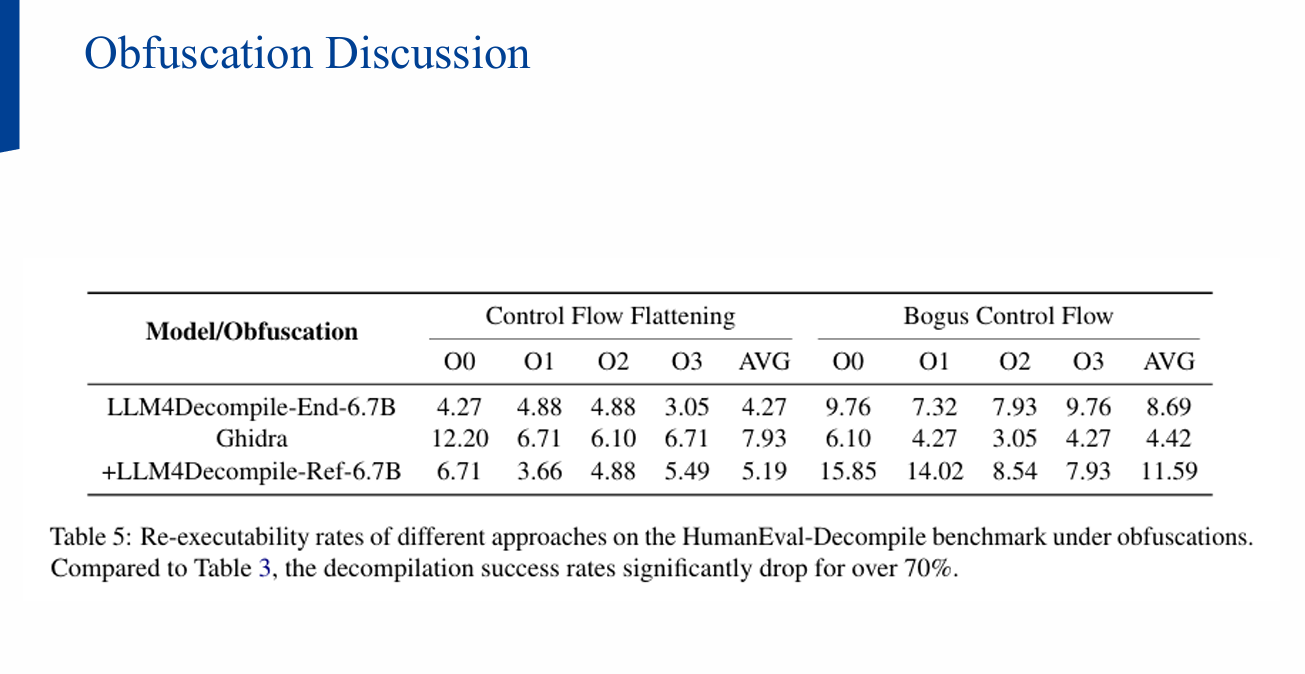
8) 난점: 코드 난독화(Obfuscation)
일반적인 상용 난독화(예: O-LLVM 변형 등)에서는 Ghidra/LLM4Decompile 모두 취약.
무단 역공학 위험 우려 대비 측면에서 악용 리스크는 제한적으로 관찰.
발표 자료
- 자세한 내용은 논문이나 아래 발표 자료로 확인 가능합니다.