
Language Model Beats Diffusion - Tokenizer is Key to Visual Generation
Abstract
LLM은 Language Generative Task들에 잘 사용되긴 하지만 Video나 Image Generation Task들에 대해서는 Diffusion Model만큼 잘 동작하지 않는다. LLM을 visual generation task에 잘 적용하기 위해서 Visual Tokenizer를 새롭게 제안한다. 이는 Pixel Space Input을 Discrete token으로 잘 Mapping하는 것을 목적으로 하며 video와 image를 공통 token vocabulary를 사용하여 표현할 수 있다.
1. Introduction
LM을 사용하여 이미지나 영상을 생성할 수 있다. 하지만 그러기 위해서는 image pixel을 discrete token sequence들로 변환하는 과정이 필요하고, 이를 Visual Tokenizer라고 부른다. 하지만, visual generation task는 diffusion model만큼의 성능은 보이지 못한다.
저자들은 이 이유에 대해서 좋은 Visual Representation이 부족하기 때문이라고 주장한다. 저자들은 좋은 visual tokenizer를 사용하는 경우 genearation fidelity와 efficiency를 모두 가질 수 있다고 주장한다. LLM들과 다른 생성모델과 가장 큰 차이점을 가지고 있는 것이 discrete latent space를 가진다는 점이다.
Video나 Image를 Discrete Latent Token들로 변환하는 것은 3가지 장점이 있다고 한다.
Compatibility with LLMs: 기존 LLM들과 잘 맞기 때문에 학습이나 안정화 방법을 많이 차용가능.Compressed Representation: 압축된 RGB 형태와 달리 Token들은 바로 모델의 입력으로 사용이 가능하고 더 빠른 processing이 가능하다.Visual Understanding Benefits: Token으로 정리한 형태가 모델이 더 잘 이해하는 형태임.
저자들은 MAGVIT-v2모델을 새롭게 제안한다. 이 모델은 Lookup-free quantization과 image/video shared vocabulary를 사용한다는 장점이 있다. 더 자세한 내용은 3절에서 다룬다.
2. Background
2.1 LM for visual generation
Visual Tokenizer $f$는 Visual Input을 Sequence of discrete token으로 변환함. Video $V \in \mathbb{R}^{T \times H \times W \times 3}$ 가 $f$를 통과하면 discrete representation $X = f(V) \in {1,\; 2,\; … \; K} ^{T^{\prime} \times H^{\prime} \times W^{\prime}}$로 재구성이 가능하다. 이때 $K$는 Codebook Size로 Visual Token 개수를 의미한다. 최종적인 $X$는 Raster Scan Order로 변환하여 1D 크기의 Input으로 변화하여 모델링한다.
2.2 Denoising Diffusion Models(DDM)
DDM과 LM의 가장 큰 차이점은 Latent Space의 종류이다. 일반적인 DDM은 Continous Latent Space로 처리하지만, LM을 사용하기 위해선 Discrete Latent Space를 사용해야 한다. 앞서 언급한 3가지 장점을 제대로 활용하기 위해서 discrete token으로 처리하는 tokenizer를 제안한다.
2.3 Visual Tokenizer
Visual Tokenization은 pixel을 discrete representation으로 변환하기 위한 중요한 과정이다. VQ-VAE가 사용한 방법을 정리해보면, $V \in \mathbb{R}^{T \times H \times W \times 3}$의 입력을 받았을 때, $Z = E(V) \in {1,\; 2,\; … \; K} ^{T^{\prime} \times H^{\prime} \times W^{\prime} \times d}$ 로 처리가 된다. 이후 $z \in R^d$를 vector quantization 을 진행하여 $q(z)$로 처리한다. 즉 아래와 같이 양자화를 진행함.
이후, $d$차원을 버리고 처리하여 ${1,\; 2,\; … \; K} ^{T^{\prime} \times H^{\prime} \times W^{\prime}}$ 크기의 Indices로 전환한다.
Video Tokenization은 더 어려운 Task이고, MAGVIT는 아직 Image를 제대로 처리하지 못하고 Long Sequence를 생성하는 과정에서 Temporal Consistency 문제가 존재한다.
3. Method
이번 논문은 Video Tokenizer를 새롭게 만드는 데에 집중을 했고, 이를 위해 Look-up quantizer와 tokenizer model에 enhancement를 진행했다.
3.1 LoopUP-Free Quantizer
Tokenizer와 관련하여 reconstruction quality와 generation quality를 혼동하는 경우가 많다. 이 둘은 큰 차이점이 있고, Larger vocabulary가 반드시 performace gain을 가져다 주지는 않는다. 이는 Figure 1을 통해서도 확인할 수 있다.
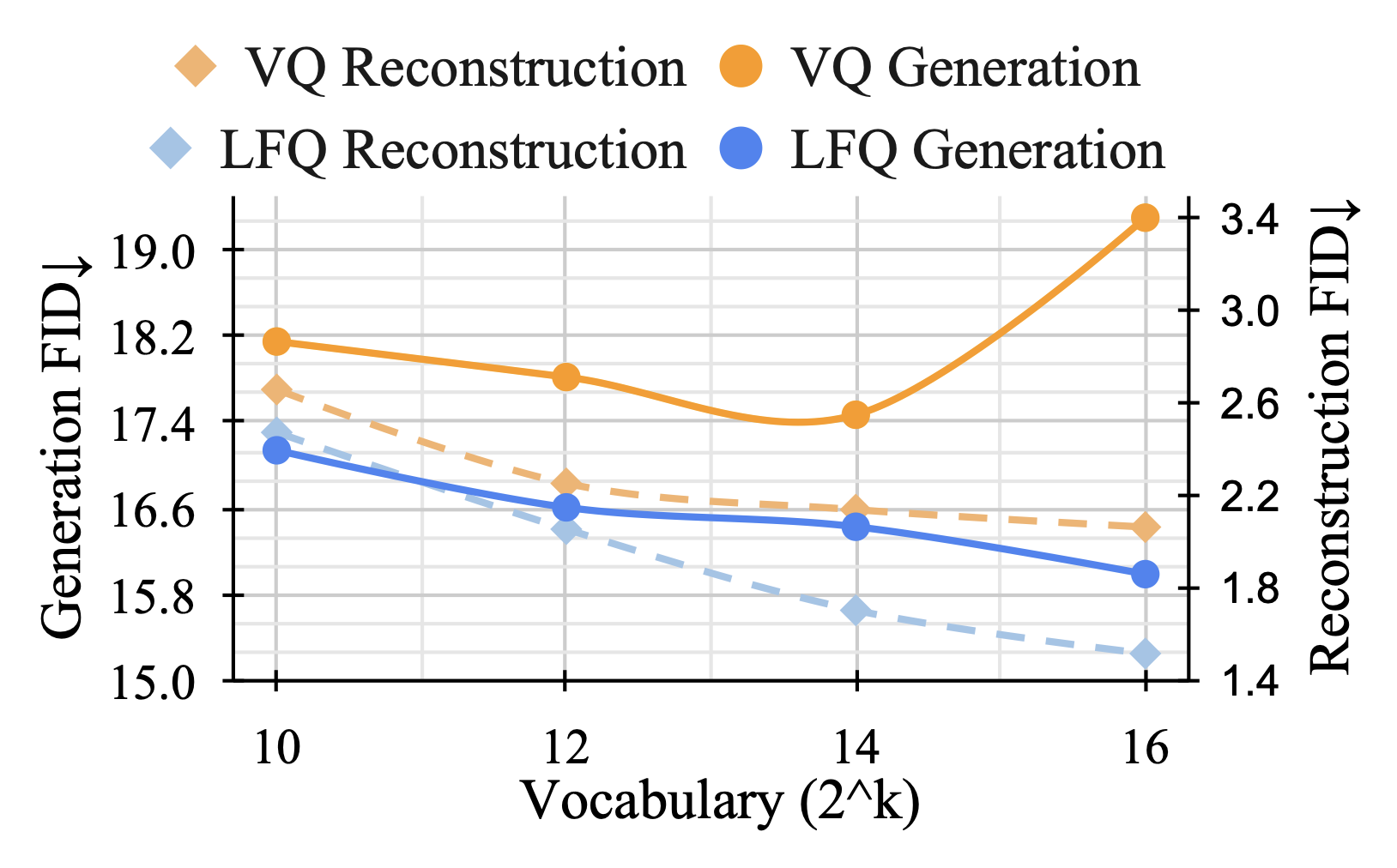
위 Figure에서 주황색을 확인해보면, Vocabulary size가 어느정도 이상이 되면 오히려 FID 값이 크게 나오는 것을 확인할 수 있다. 이를 해결하는 한 방법은 각 vocab당 embedding 크기를 줄이는 방법이 있는데, 저자들은이 직관에서 착안하여 Lookup-Free Quantization을 새롭게 제안한다.
간단하게 표현하자면, $z \in \mathbb{R}^{\log_2K}$의 Feature Vector가 들어오면 $q(z_i) = \text{sign} ({z_i})$으로 간단하게 양자화를 진행한다. 이후, 해당 이진 값을 바탕으로 $\text{Index}$(이진을 자연수로 변환)을 연산하여 token으로 사용한다. 다만, 이런 양자화를 진행하는 경우 특정 토큰으로 quantization이 cluster를 이룬다는 것이 밝혀졌기 때문에 저자들은 아래와 같은 Loss를 두어 이를 억제하고자 한다.
\[\mathcal{L}_{\text{entropy}} = \mathbb{E}[H(q(z))] - H[\mathbb{E}(q(z))]\]첫번째 Term은 내가 특정 latent를 양자화할 때의 Entropy는 작게 유지하여 확실한 quantization을 도모하도록 하고, 전체적인 Entropy는 크게 유지하여 특정 Token으로 군집되는 것을 방지하고자 한다. 이 Loss 뿐만 아니라, reconstruction loss, GAN, perceptual loss, commitment loss 까지 함께 학습을 진행한다.
3.2 Visual Tokenizer Model Improvement
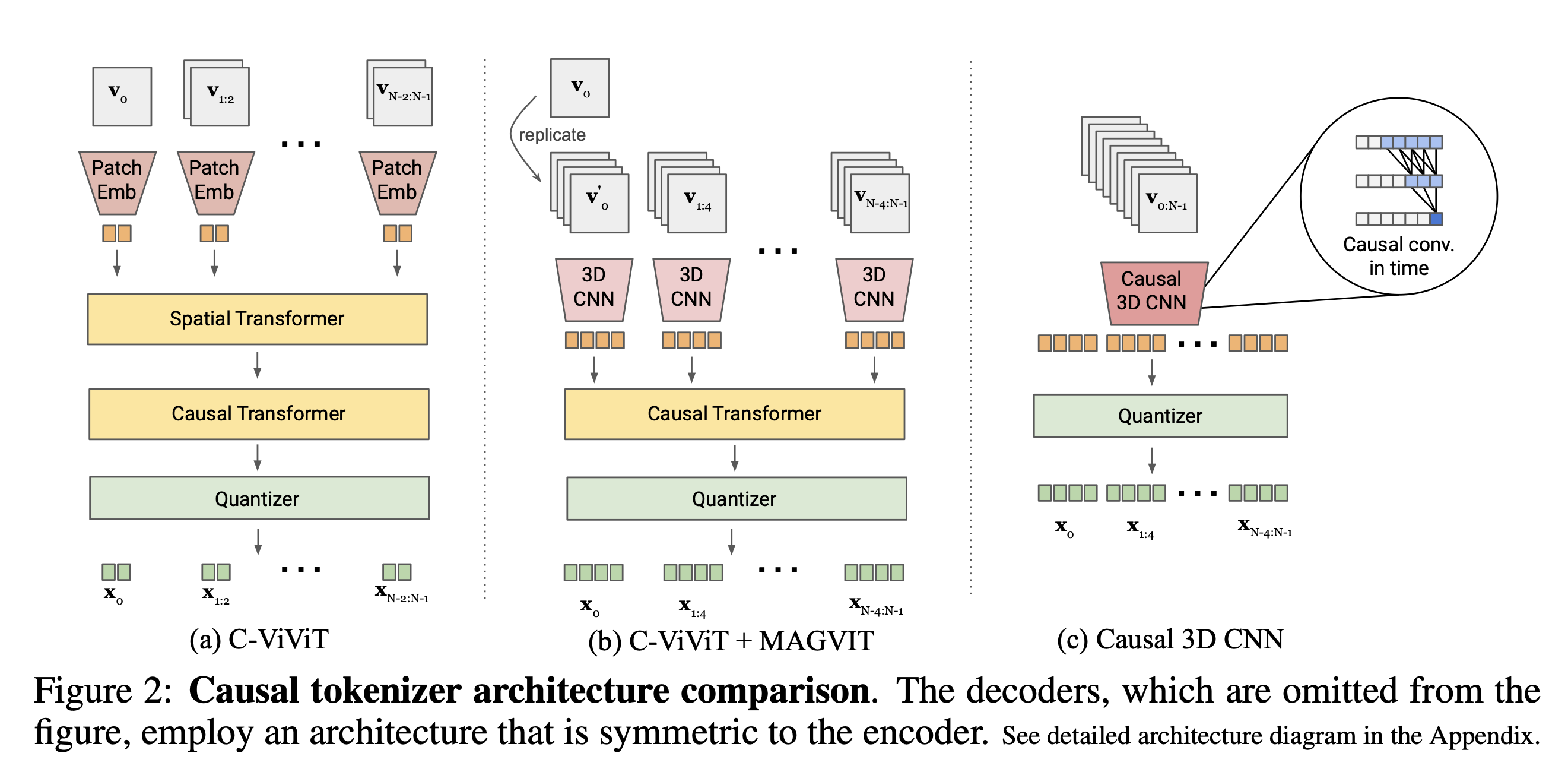
기존의 Visual Tokenizer는 사실 Tmporal receptive field의 영향으로 인해 Image/Video에 대한 joint representation이 미흡했다. 저자들은 이를 해결하기 위해서 C-ViViT의 방법론을 다시 확인했다고 한다.
C-ViViT 방법론은 (a)에서 보이는 것처럼 Spatial Transformer를 먼저 사용하고 이후 Casual Transformer를 사용하여 최종적인 quantization을 진행한다.
저자들은 이 방법이 두가지 한계점이 있다고 주장한다.
- Spatial Transformer를 사용할 때, Positional Embedding을 사용하지만 이 때문에 다양한 크기나 형태로의 확장이 굉장히 어려워지는 문제가 발생한다.
- 3D CNN이 Spatial transformer보다 더 잘 동작한다.
저자들은 이 문제를 해결하기 위해서 2가지 새로운 design을 제안한다.
(b) C-ViViT + MAGVIT 방법은 한번에 4프레임씩 Regular 3D CNN 구조를 사용하고 이후 Casual Temporal Transformer, Quantization을 진행한다.
(c) Casual 3D CNN 방법은 Casual 3D CNN을 사용하여 이전 프레임만 확인하여 Embedding을 생성하고 이후 Quantization을 진행하여 우리가 앞에서 본 LFQ를 사용한 token을 생성한다.
4. Experiment
4.1 Experimental Setups
- 실험 목적
- 제안한 MAGVIT-v2 tokenizer가 단순 reconstruction 품질뿐 아니라,
- visual generation
- video compression
- video understanding 에서 모두 더 좋은 visual representation을 제공하는지 확인한다.
- 제안한 MAGVIT-v2 tokenizer가 단순 reconstruction 품질뿐 아니라,
- 사용 데이터셋
- Video generation: Kinetics-600 (K600), UCF-101
- Image generation: ImageNet
- Video compression: MCL-JCV
- Video understanding: Kinetics-400 (K400), SSv2
- 구현 핵심
- LFQ를 사용하여 codebook lookup을 제거
- 기본 vocabulary 크기를 2^18로 설정
- entropy penalty는 초기에 더 크게 두고, 2k step 동안 선형적으로 줄여 최종 0.1로 설정
4.2 Visual Generation
(1) Video Generation
- 이 실험에서 보려는 것
- 제안한 tokenizer가 실제 비디오 생성 품질을 향상시키는지 확인
- 같은 MLM backbone을 유지해도 tokenizer 개선만으로 성능 향상이 가능한지 검증
- causal tokenizer 설계가 frame prediction에 도움이 되는지도 함께 확인
- 실험 설정
- UCF-101: class-conditional generation
- K600: 5-frame condition을 주고 나머지 frame prediction
- large vocabulary(2^18)를 다루기 위해 2^9 두 개의 head로 factorized prediction 사용
- 평가 metric
- FVD (Fréchet Video Distance)
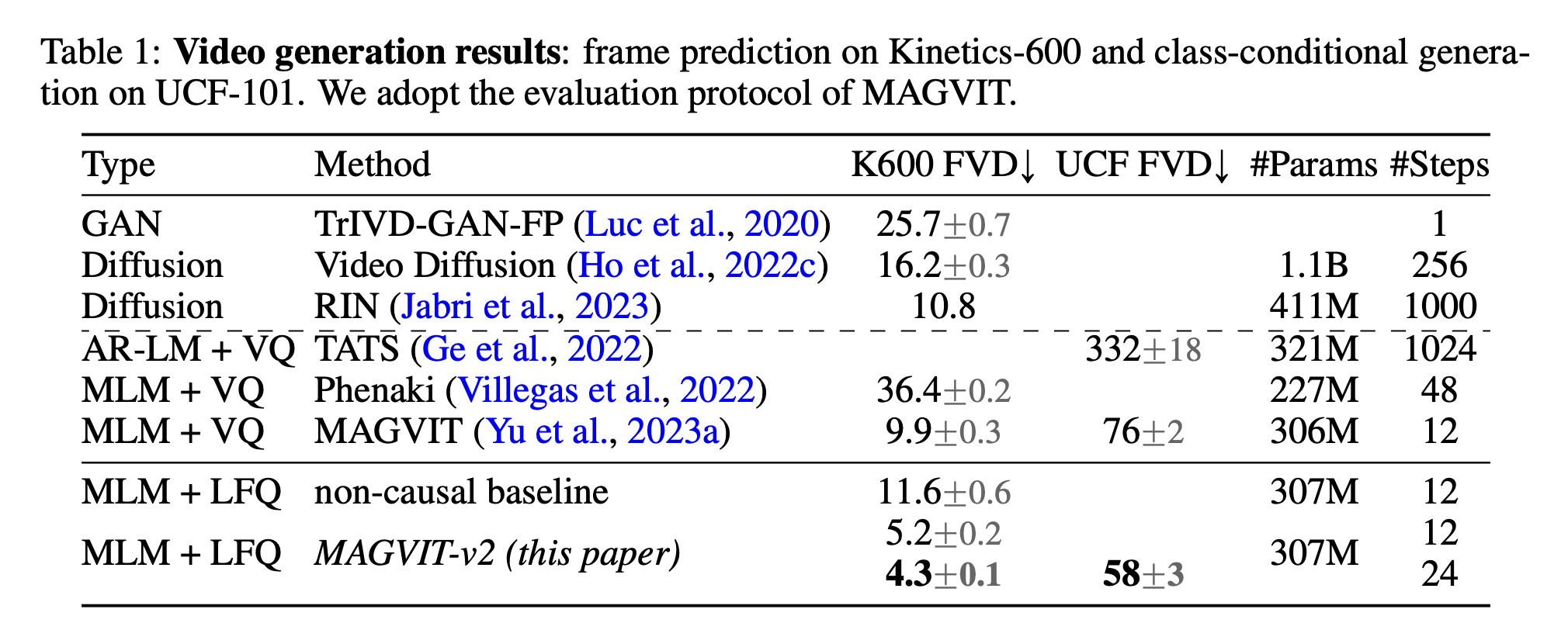
- 결과 해석
- MAGVIT-v2는 두 벤치마크에서 기존 방법들을 능가함
- 같은 MLM transformer를 사용했는데도 MAGVIT보다 크게 좋아졌으므로, 개선의 핵심 원인이 tokenizer임을 보여줌
- non-causal baseline보다도 더 좋아서, causal tokenizer 설계의 효과가 확인됨
(2) Image Generation on ImageNet
- 이 실험에서 보려는 것
- 제안 tokenizer가 이미지 생성에서도 강력한지 확인
- diffusion model과 비교했을 때, 품질과 sampling efficiency 양쪽에서 경쟁력이 있는지 검증
- 실험 설정
- ImageNet class-conditional generation
- 주로 512×512 결과를 중심으로 비교
- 평가 metric
- FID
- IS (Inception Score)
- #Steps (sampling efficiency 비교용)
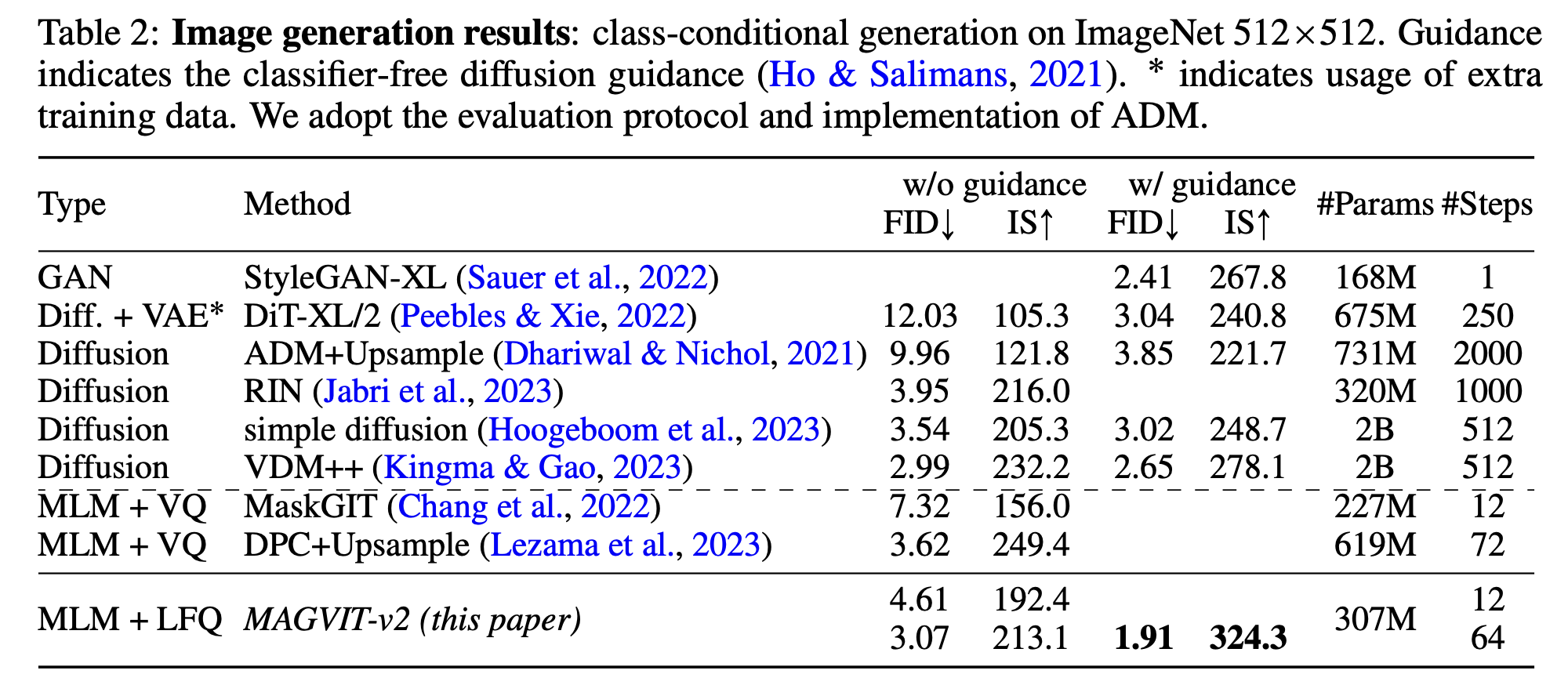
- 결과 해석
- MAGVIT-v2는 best diffusion baseline보다 더 좋은 FID/IS를 기록
- 특히 512×512에서 diffusion의 FID 2.65 대비 1.91로 크게 개선
- 생성 step 수가 훨씬 적어서 inference efficiency도 우수
- 256×256에서는 격차가 줄지만, 더 작은 모델/적은 step으로도 충분히 경쟁력 있음
4.4 Video Understanding
- 이 실험에서 보려는 것
- tokenizer가 단순 복원/생성용이 아니라, action recognition에 유용한 representation도 학습하나
- 실험 설정
- 두 가지 setup 사용
- token을 transformer의 output target으로 사용
- token을 transformer의 input으로 사용
- output target setup은 BEVT-style pretraining
- input setup은 token을 pixel로 detokenize한 뒤, raw pixel로 학습된 frozen ViViT에 입력
- 두 가지 setup 사용
- 평가 metric
- Classification accuracy

- 결과 해석
- MAGVIT-v2는 두 setup 모두에서 MAGVIT보다 더 높은 정확도 기록
- 특히 decoded token을 input으로 넣는 경우, raw pixel로 학습한 모델 성능에 더 가까워짐
- 절대적인 최고 성능을 주장하는 실험은 아니지만, tokenizer representation quality가 분명히 향상되었음
4.5 Ablation Study
- 이 실험에서 보려는 것
- Section 3에서 제안한 핵심 설계들
- LFQ
- large vocabulary
- causal architecture
- up/downsampler 변경
- late temporal downsampling
- deeper model
- adaptive normalization
- 3D blur pooling 이 실제 성능 향상에 얼마나 기여하는지 검증
- Section 3에서 제안한 핵심 설계들
(1) Causal Architecture Comparison
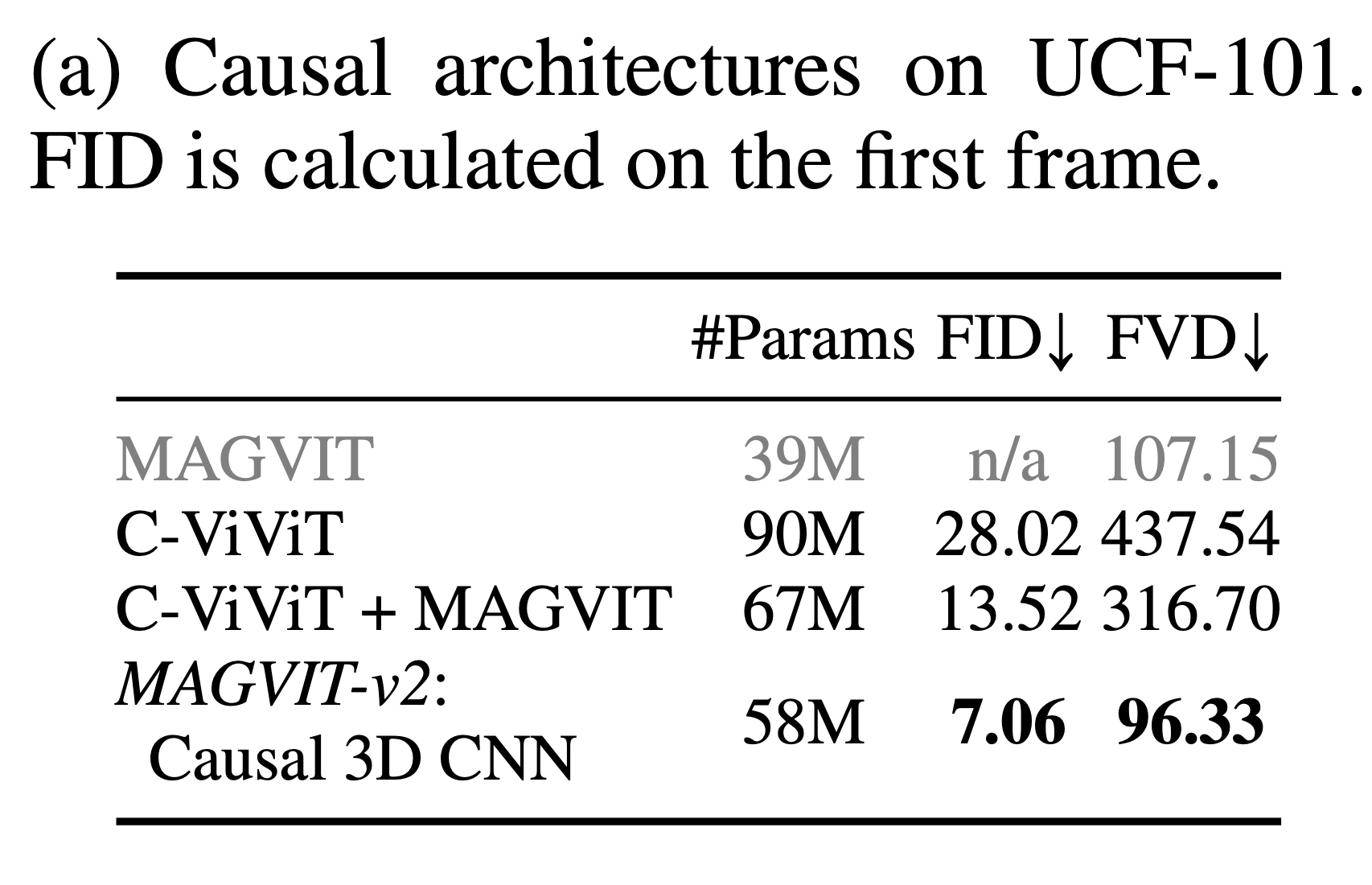
- 목적
- 세 가지 causal 구조 중 어떤 방식이 가장 좋은지 확인
- C-ViViT
- C-ViViT + MAGVIT
- causal 3D CNN
- 세 가지 causal 구조 중 어떤 방식이 가장 좋은지 확인
- 평가 metric
- FID (첫 프레임 기준)
- FVD
- 결과 해석
- causal 3D CNN이 가장 낮은 FID/FVD를 기록
- 따라서 joint image-video tokenization용 causal 구조로 가장 적합하다고 해석 가능