
소개
이 글은 Semantic Flow Graph(SFG)를 활용하여 코드 표현을 사전 학습(Pre-training)하고, 이를 효율적인 버그 로컬라이제이션에 적용하는 연구를 정리한 것입니다. 기존 BERT 기반 버그 로컬라이제이션의 한계를 보완하기 위해 SemanticCodeBERT와 HMCBL(Hierarchical Momentum Contrastive Bug Localization)을 제안합니다.
1. 문제 정의
1.1 기존 BERT 기반 기법의 한계
- 코드의 깊은 의미(Deep Semantics) 부족
- 자연어와 달리, 프로그래밍 언어는 명확한 구조를 가짐
- 기존 모델은 코드 토큰 시퀀스로만 처리하거나 얕은 구조(예: Data Flow Graph)만 고려
- 부적절한 Negative Sample 사용 & 어휘 유사도 미반영
- 버그 보고서당 하나의 비관련 변경셋만 Negative로 선택 → 비효율적 학습
- 버그 보고서와 변경셋 간 어휘 유사도(Lexical similarity) 고려 부족
2. Semantic Flow Graph (SFG)
2.1 개념
SFG는 코드의 데이터·제어 흐름을 타입과 역할 정보까지 반영한 그래프입니다.
1
2
예시 코드:
a = m(b, c)
- 데이터 흐름:
b → a,c → a - 타입 정보 예시:
b: Integerc: User-defined typea: Boolean (함수 호출 결과)
- 역할 정보 예시:
m함수 호출을 통해b와c가a로 전달됨
SFG 정의: <N, E, T, R>
- N: 노드 집합 (변수, 함수 등)
- E: 간선(데이터/제어 흐름)
- T: 타입 집합 (총 55개)
- R: 역할 집합 (총 43개)

3. SemanticCodeBERT
3.1 입력 구조
[CLS], W, [C], S, [SEP], [N], N, [T], T, [R], R, [SEP]
- W: 버그 보고서 텍스트
- S: 소스 코드 토큰 시퀀스
- N: SFG 노드
- T: 타입 시퀀스
- R: 역할 시퀀스
- C: 주석(Comment)

3.2 Masked Attention
- SFG에서 직접 연결된 토큰 간만 Attention 허용
- 불필요한 잡음을 줄이고 의미 있는 의존성만 학습
4. HMCBL (Hierarchical Momentum Contrastive Bug Localization)
4.1 개념
- 버그 보고서(Q)와 변경셋(K) 간 유사도 학습
- (Q, Positive, Negative) Triplet 구성
- 목표: Positive 유사도↑, Negative 유사도↓
4.2 구조
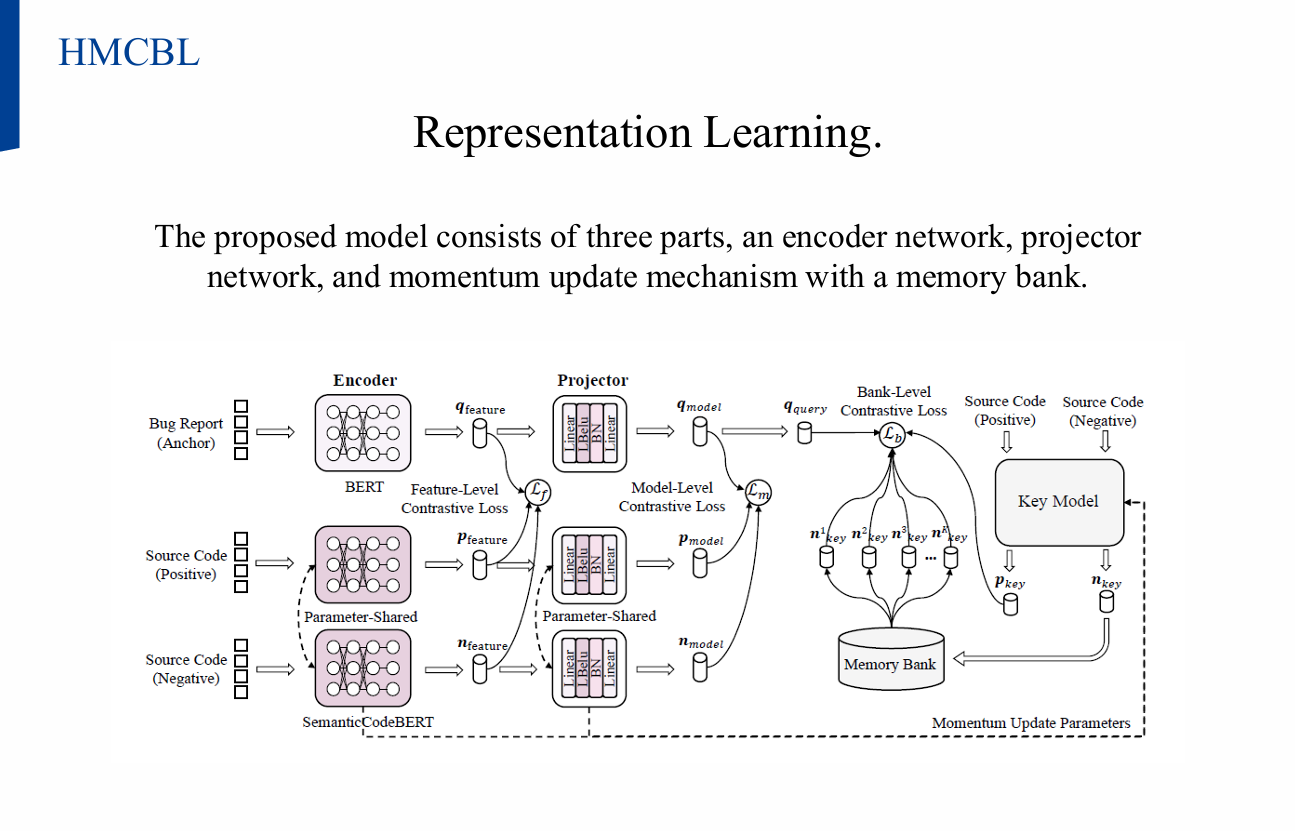
- Encoder Network
- 버그 보고서: 자연어 입력
- 변경셋: 코드 입력
- Projector Network
- 다층 퍼셉트론(MLP)으로 벡터를 압축해 공유 임베딩 공간으로 매핑
- Momentum Update + Memory Bank
- 대규모 Negative sample 활용
- 이전 배치에서 얻은 변경셋 임베딩을 메모리에 저장해 대조 학습
5. 실험
5.1 데이터셋
- 기존 버그 로컬라이제이션 벤치마크 데이터 사용
5.2 비교 모델
- BLUiR: AST 기반 전통 IR 기법
- FBL-BERT: SOTA BERT 기반 기법
- GraphCodeBERT: Data flow 고려한 코드 표현
- UniXcoder: AST+주석 등 다중 모달 활용
5.3 평가 지표
- Precision@K (P@K): 상위 K개 결과 중 정답 비율
- MAP (Mean Average Precision): 관련 변경셋 전체를 찾는 능력
- MRR (Mean Reciprocal Rank): 첫 번째 정답 위치 평가
5.4 결과
| 모델 | P@1 | P@5 | MAP | MRR |
|---|---|---|---|---|
| BLUiR | 낮음 | 낮음 | 낮음 | 낮음 |
| FBL-BERT | 높음 | 높음 | 높음 | 높음 |
| GraphCodeBERT | 중간 | 중간 | 중간 | 중간 |
| 제안 기법 | 최고 | 최고 | 최고 | 최고 |
6. Ablation Study
- SFG, 타입·역할 정보, 마스크드 어텐션 각각의 성능 기여도를 실험적으로 검증
- 모든 구성 요소가 성능 향상에 기여함을 확인
결론
- Semantic Flow Graph를 활용한 사전 학습이 코드 의미를 깊이 있게 반영
- SemanticCodeBERT + HMCBL 조합으로 기존 SOTA를 초월하는 성능 달성
- 향후 연구:
- 더 다양한 코드 구조 정보 포함
- 대규모 데이터에서 학습 안정성 개선
발표 자료
- 자세한 내용은 논문이나 아래 발표 자료로 확인 가능합니다.